Test: Pipelining- 1 - Computer Science Engineering (CSE) MCQ
30 Questions MCQ Test GATE Computer Science Engineering(CSE) 2026 Mock Test Series - Test: Pipelining- 1

The stage delays in a -stage pipeline are 800, 500, 400 and 300 picoseconds. The first stage (with delay 800 picoseconds) is replaced with a functionality equivalent design involving two stages with respective delays 600 and 350 picoseconds. The throughput increase of the pipeline is ___________ percent.
Consider a
3 GHz (gigahertz) processor with a three stage pipeline and stage latencies
T1, T2 and T3 such that
 If the longest pipeline stage is split into two pipeline stages of equal latency , the new frequency is
If the longest pipeline stage is split into two pipeline stages of equal latency , the new frequency is
__________
GHz, ignoring delays in the pipeline registers.
3 GHz (gigahertz) processor with a three stage pipeline and stage latencies
T1, T2 and T3 such that
If the longest pipeline stage is split into two pipeline stages of equal latency , the new frequency is__________
GHz, ignoring delays in the pipeline registers.

The stage delays in a -stage pipeline are 800, 500, 400 and 300 picoseconds. The first stage (with delay 800 picoseconds) is replaced with a functionality equivalent design involving two stages with respective delays 600 and 350 picoseconds. The throughput increase of the pipeline is ___________ percent.
An instruction pipeline consists of 4 stages – Fetch (F), Decode field (D), Execute (E) and Result Write (W). The 5 instructions in a certain instruction sequence need these stages for the different number of clock cycles as shown by the table below
No. of cycles needed for
Instruction F D E W
1 1 2 1 1
2 1 2 2 1
3 2 1 3 2
4 1 3 2 1
5 1 2 1 2
Find the number of clock cycles needed to perform the 5 instructions.

Comparing the time T1 taken for a single instruction on a pipelined CPU with time T2 taken on a non-pipelined but identicalCPU, we can say that
An instruction pipeline has five stages where each stage take 2 nanoseconds and all instruction use all five stages. Branch instructions are not overlapped. i.e., the instruction after the branch is not fetched till the branch instruction is completed. Under ideal conditions,
a. Calculate the average instruction execution time assuming that 20% of all instructions executed are branch instruction. Ignore the fact that some branch instructions may be conditional.
b. If a branch instruction is a conditional branch instruction, the branch need not be taken. If the branch is not taken, the following instructions can be overlapped. When 80% of all branch instructions are conditional branch instructions, and 50% of the conditional branch instructions are such that the branch is taken, calculate the average instruction execution time.
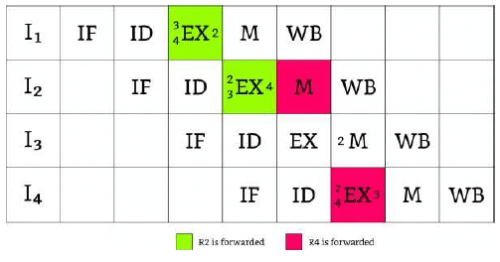
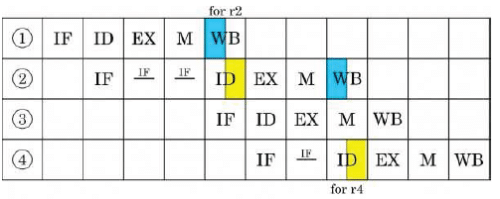
Consider a 5-stage pipeline - IF (Instruction Fetch), ID (Instruction Decode and register read), EX (Execute), MEM (memory), and WB (Write Back). All (memory or register) reads take place in the second phase of a clock cycle and all writes occur in the first phase. Consider the execution of the following instruction sequence:
a. Show all data dependencies between the four instructions.
b. Identify the data hazards.
c. Can all hazards be avoided by forwarding in this case.

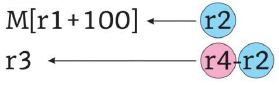

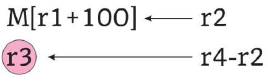
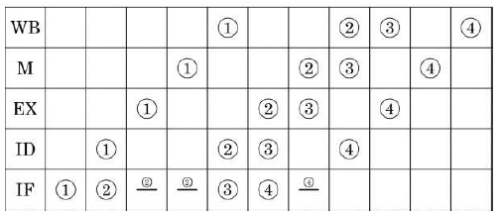
For a pipelined CPU with a single ALU, consider the following situations
I. The j+1 –st instruction uses the result of the j-th instruction as an operand
II. The execution of a conditional jump instruction
III. The j-th and j+1st instructions require the ALU at the same time.
Which of the above can cause a hazard
A 4-stage pipeline has the stage delays as 150, 120, 160 and 140 nanoseconds respectively. Registers that are usedbetween the stages have a delay of 5 nanoseconds each. Assuming constant clocking rate, the total time taken to process1000 data items on this pipeline will be
Consider a pipeline processor with 4 stages S1 to S4. We want to execute the following loop:
for (i = 1; i < = 1000; i++)
{I1, I2, I3, I4}
where the time taken (in ns) by instructions I1 to I4 for stages S1 to S4 are given below:
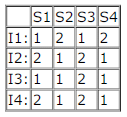
The output of I1 for i = 2 will be available after
A 5 stage pipelined CPU has the following sequence of stages:
- IF – instruction fetch from instruction memory
- RD – Instruction decode and register read
- EX – Execute: ALU operation for data and address computation
- MA – Data memory access – for write access, the register read at RD state is used.
- WB – Register write back
Consider the following sequence of instructions:
- I1: L R0, loc 1; R0 <= M[loc1]
- I2: A R0, R0; R0 <= R0 +R0
- I3: S R2, R0; R2 <= R2-R0
Let each stage take one clock cycle
What is the number of clock cycles taken to complete the above sequence of instructions starting from the fetch of ?
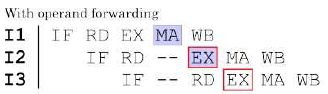
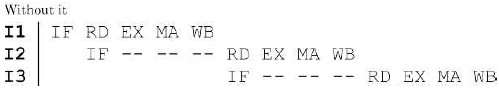

We have two designs D1 and D2 for a synchronous pipeline processor. D1 has 5 pipeline stages with execution times of 3nsec, 2 nsec, 4 nsec, 2 nsec and 3 nsec while the design D2 has 8 pipeline stages each with 2 nsec execution time Howmuch time can be saved using design D2 over design D1 for executing 100 instructions?
A CPU has a five-stage pipeline and runs at 1 GHz frequency. Instruction fetch happens in the first stage of the pipeline. A conditional branch instruction computes the target address and evaluates the condition in the third stage of the pipeline. The processor stops fetching new instructions following a conditional branch until the branch outcome is known. A program
executes 109 instructions out of which 20% are conditional branches. If each instruction takes one cycle to complete on average, the total execution time of the program is:
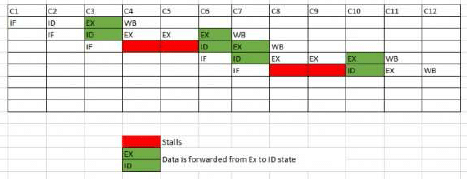
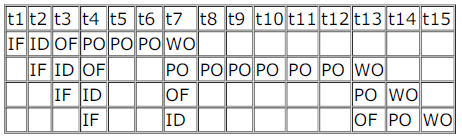
A pipelined processor uses a 4-stage instruction pipeline with the following stages: Instruction fetch (IF), Instruction decode (ID), Execute (EX) and Writeback (WB). The arithmetic operations as well as the load and store operations are carried out in the EX stage. The sequence of instructions corresponding to the statement X = (S - R * (P + Q))/T is given below. The values of variables P, Q, R, S and T are available in the registers R0, R1, R2, R3 and R4 respectively, before the execution of the instruction sequence.
ADD R5, R0, R1 ; R5 ← R0 + R1
MUL R6, R2, R5 ; R6 ← R2 * R5
SUB R5, R3, R6 ; R5 ← R3 - R6
DIV R6, R5, R4 ; R6 ← R5/R4
STORE R6, X ; X ← R6
The number of Read-After-Write (RAW) dependencies, Write-After-Read( WAR) dependencies, and Write-After-Write (WAW) dependencies in the sequence of instructions are, respectively,
A pipelined processor uses a 4-stage instruction pipeline with the following stages: Instruction fetch (IF), Instruction decode (ID), Execute (EX) and Writeback (WB). The arithmetic operations as well as the load and store operations are carried out in the EX stage. The sequence of instructions corresponding to the statement X = (S - R * (P + Q))/T is given below. The values of variables P, Q, R, S and T are available in the registers R0, R1, R2, R3 and R4 respectively, before the execution of the instruction sequence.
ADD R5, R0, R1 ; R5 → R0 + R1
MUL R6, R2, R5 ; R6 → R2 * R5
SUB R5, R3, R6 ; R5 → R3 - R6
DIV R6, R5, R4 ; R6 → R5/R4
STORE R6, X ; X ← R6
The IF, ID and WB stages take 1 clock cycle each. The EX stage takes 1 clock cycle each for the ADD, SUB and STORE operations, and 3 clock cycles each for MUL and DIV operations. Operand forwarding from the EX stage to the ID stage is used. The number of clock cycles required to complete the sequence of instructions is
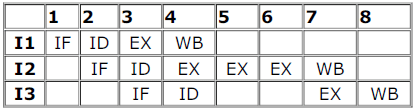
Consider a pipelined processor with the following four stages:
- IF: Instruction Fetch
- ID: Instruction Decode and Operand Fetch
- EX: Execute
- WB: Write Back
The IF, ID and WB stages take one clock cycle each to complete the operation. The number of clock cycles for the EX stage depends on the instruction. The ADD and SUB instructions need 1 clock cycle and the MUL instruction needs 3 clock cycles in the EX stage. Operand forwarding is used in the pipelined processor. What is the number of clock cycles taken to complete the following sequence of instructions?
ADD R2, R1, R0 R2 ← R1 + R0
MUL R4, R3, R2 R4 ← R3 * R2
SUB R6, R5, R4 R6 ← R5 - R4
A processor takes 12 cycles to complete an instruction I. The corresponding pipelined processor uses 6 stages with the execution times of 3, 2, 5, 4, 6 and 2 cycles respectively. What is the asymptotic speedup assuming that a very large number of instructions are to be executed?
Which of the following are NOT true in a pipelined processor?
I. Bypassing can handle all RAW hazards
II. Register renaming can eliminate all register carried WAR hazards
III. Control hazard penalties can be eliminated by dynamic branch prediction
Delayed branching can help in the handling of control hazardsFor all delayed conditional branch instructions, irrespective of whether the condition evaluates to true or false,
Delayed branching can help in the handling of control hazards
The following code is to run on a pipelined processor with one branch delay slot:
I1: ADD 
I2: Sub 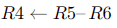
I3: ADD 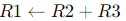
I4: STORE Memory 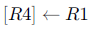
BRANCH to Label if 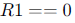
Which of the instructions I1, I2, I3 or I4 can legitimately occupy the delay slot without any program modification?
A non pipelined single cycle processor operating at 100 MHz is converted into a synchronous pipelined processor with five stages requiring 2.5 nsec, 1.5 nsec, 2 nsec, 1.5 nsec and 2.5 nsec, respectively. The delay of the latches is 0.5 nsec. The speedup of the pipeline processor for a large number of instructions is
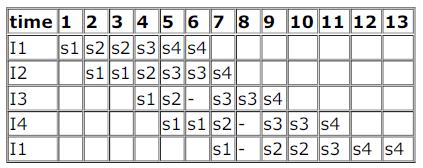
Consider a 4 stage pipeline processor. The number of cycles needed by the four instructions I1, I2, I3, I4 in stages S1, S2,
S3, S4 is shown below:
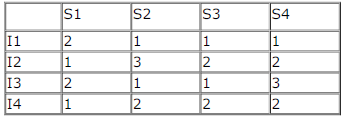
What is the number of cycles needed to execute the following loop?
For (i=1 to 2) {I1; I2; I3; I4;}
A 5-stage pipelined processor has Instruction Fetch (IF), Instruction Decode (ID), Opearnd Fetch (OF), Perform Operation (PO) and Write Operand (WO) stages. The IF, ID, OF and WO stages take 1 clock cycle each for any instruction. The PO stage takes 1 clock cycle for ADD and SUB instructions, 3 clock cycles for MUL instruction and 6 clock cycles for DIV instruction respectively. Operand forwarding is used in the pipeline. What is the number of clock cycles needed to execute the following sequence of instructions?
Instruction Meaning of instruction
t0 : MUL R2,R0,R1R2 ← R0 ∗ R1
t1 : DIV R5,R3,R4 R5 ← R3/R4
t2 : ADD R2,R5,R2R2 ← R5 + R2
t3 : SUB R5,R2,R6 R ← − 5 R2 R6
Consider an instruction pipeline with four stages (S1, S2, S3 and S4) each with combinational circuit only. The pipeline registers are required between each stage and at the end of the last
stage. Delays for the stages and for the pipeline registers are as given in the figure.
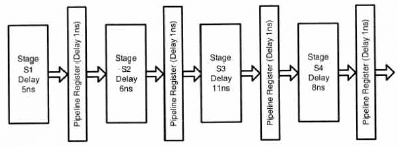
What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation?
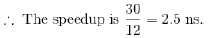
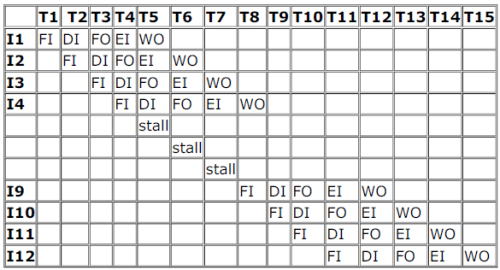
Consider an instruction pipeline with five stages without any branch prediction: Fetch Instruction (FI), Decode Instruction(DI), Fetch Operand (FO), Execute Instruction (EI) and Write Operand (WO). The stage delays for FI, DI, FO, EI and WO are5 ns, 7 ns, 10 ns, 8 ns and 6 ns, respectively. There are intermediate storage buffers after each stage and the delay of eachbuffer is 1 ns. A program consisting of 12 instructions I1, I2, I3, …, I12 is executed in this pipelined processor. Instruction I4is the only branch instruction and its branch target is I9. If the branch is taken during the execution of this program, thetime (in ns) needed to complete the program is
Consider a 6-stage instruction pipeline, where all stages are perfectly balanced. Assume that there is no cycle-time overhead of pipelining. When an application is executing on this 6-stage pipeline, the speedup achieved with respect to non-pipelined execution if 25% of the instructions incur 2 pipeline stall cycles is ____________
An instruction pipeline has five stages, namely, instruction fetch (IF), instruction decode and register fetch (ID/RF), instruction execution (EX), memory access (MEM), and register writeback (WB) with stage latencies 1 ns, 2.2 ns, 2 ns, 1 ns, and 0.75 ns, respectively (ns stands for nanoseconds). To gain in terms of frequency, the designers have decided to split the ID/RF stage into three stages (ID, RF1, RF2) each of latency 2.2/3 ns. Also, the EX stage is split into two stages (EX1, EX2) each of latency 1 ns. The new design has a total of eight pipeline stages. A program has 20% branch instructions which execute in the EX stage and produce the next instruction pointer at the end of the EX stage in the old design and at the end of the EX2 stage in the new design. The IF stage stalls after fetching a branch instruction until the next instruction pointer is computed. All instructions other than the branch instruction have an average CPI of one in both the designs. The execution times of this program on the old and the new design are P and Q nanoseconds, respectively. The value of P/Q is __________.
Consider the following processors (ns stands for nanoseconds). Assume that the pipeline registers have zero latency.
P1: Four-stage pipeline with stage latencies 1 ns, 2 ns, 2 ns, 1 ns.
P2: Four-stage pipeline with stage latencies 1 ns, 1.5 ns, 1.5 ns, 1.5 ns.
P3: Five-stage pipeline with stage latencies 0.5 ns, 1 ns, 1 ns, 0.6 ns, 1 ns.
P4: Five-stage pipeline with stage latencies 0.5 ns, 0.5 ns, 1 ns, 1 ns, 1.1 ns.
Which processor has the highest peak clock frequency?
|
57 docs|215 tests
|
|
57 docs|215 tests
|
Important Questions for Pipelining- 1
Pipelining- 1 MCQs with Answers
Online Tests for Pipelining- 1 GATE Computer Science Engineering(CSE) 2026 Mock Test Series
|
© EduRev
|
Education Revolution
|



|








