Test: SQL - Computer Science Engineering (CSE) MCQ
30 Questions MCQ Test - Test: SQL

Which of the following statements are TRUE about an SQL query?
P : An SQL query can contain a HAVING clause even if it does not have a GROUP BY clause
Q : An SQL query can contain a HAVING clause only if it has a GROUP BY clause
R : All attributes used in the GROUP BY clause must appear in the SELECT clause
S : Not all attributes used in the GROUP BY clause need to appear in the SELECT clause
Q : An SQL query can contain a HAVING clause only if it has a GROUP BY clause
R : All attributes used in the GROUP BY clause must appear in the SELECT clause
S : Not all attributes used in the GROUP BY clause need to appear in the SELECT clause
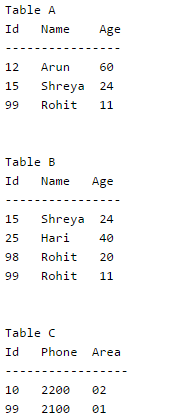
Consider the above tables A, B and C. How many tuples does the result of the following SQL query contains?


Consider a database table T containing two columns X and Y each of type integer. After the creation of the table, one record (X=1, Y=1) is inserted in the table. Let MX and My denote the respective maximum values of X and Y among all records in the table at any point in time. Using MX and MY, new records are inserted in the table 128 times with X and Y values being MX+1, 2*MY+1 respectively. It may be noted that each time after the insertion, values of MX and MY change. What will be the output of the following SQL query after the steps mentioned above are carried out?
SELECT Y FROM T WHERE X=7;
Database table by name Loan_Records is given below.
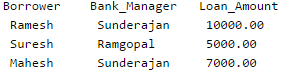
What is the output of the following SQL query?

A relational schema for a train reservation database is given below. Passenger (pid, pname, age) Reservation (pid, class, tid)
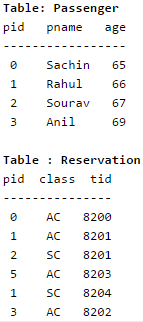
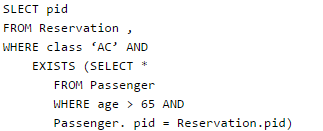
What pids are returned by the following SQL query for the above instance of the tables?
Let R and S be relational schemes such that R={a,b,c} and S={c}. Now consider the following queries on the database:
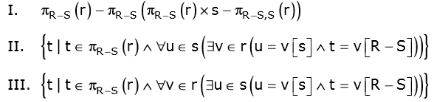
IV.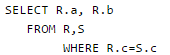
Q. Which of the above queries are equivalent?
Consider the following relational schema:
Suppliers(sid:integer, sname:string, city:string, street:string)
Parts(pid:integer, pname:string, color:string)
Catalog(sid:integer, pid:integer, cost:real)
Consider the following relational query on the above database:
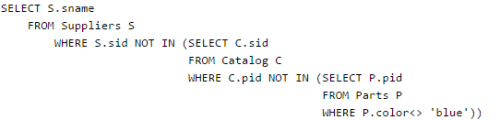
Q. Assume that relations corresponding to the above schema are not empty. Which one of the following is the correct interpretation of the above query?




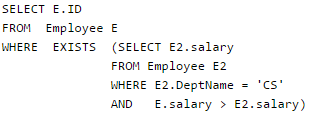
Consider the table employee(empId, name, department, salary) and the two queries Q1 ,Q2 below. Assuming that department 5 has more than one employee, and we want to find the employees who get higher salary than anyone in the department 5, which one of the statements is TRUE for any arbitrary employee table?
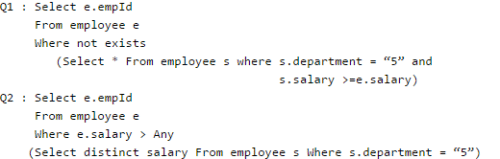
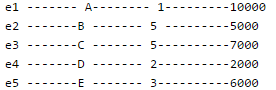
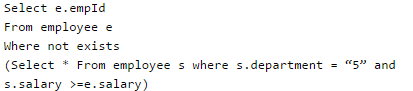

Given the following statements:

Q. Which one of the following statements is CORRECT?


Given the following schema:
employees(emp-id, first-name, last-name, hire-date, dept-id, salary) departments(dept-id, dept-name, manager-id, location-id)
You want to display the last names and hire dates of all latest hires in their respective departments in the location ID 1700. You issue the following query:
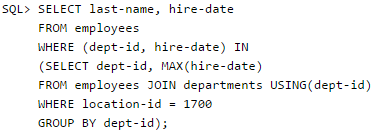
Q. What is the outcome?
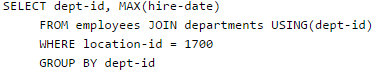

SQL allows tuples in relations, and correspondingly defines the multiplicity of tuples in the result of joins. Which one of the following queries always gives the same answer as the nested query shown below:
select * from R where a in (select S.a from S)
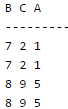
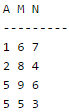
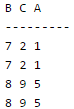
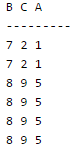

Consider the following relational schema:
employee(empId, empName, empDept)
customer(custId, custName, salesRepId, rating)
salesRepId is a foreign key referring to empId of the employee relation. Assume that each employee makes a sale to at least one customer. What does the following query return?

The statement that is executed automatically by the system as a side effect of the modification of the database is
Consider the relation account (customer, balance) where customer is a primary key and there are no null values. We would like to rank customers according to decreasing balance. The customer with the largest balance gets rank 1. ties are not broke but ranks are skipped: if exactly two customers have the largest balance they each get rank 1 and rank 2 is not assigned

Consider these statements about Query1 and Query2.
1. Query1 will produce the same row set as Query2 for some but not all databases.
2. Both Query1 and Query2 are correct implementation of the specification
3. Query1 is a correct implementation of the specification but Query2 is not
4. Neither Query1 nor Query2 is a correct implementation of the specification
5. Assigning rank with a pure relational query takes less time than scanning in decreasing balance order assigning ranks using ODBC.
Q. Which two of the above statements are correct?
Consider the relation "enrolled(student, course)" in which (student, course) is the primary key, and the relation "paid(student, amount)" where student is the primary key. Assume no null values and no foreign keys or integrity constraints. Given the following four queries:

Q. Which one of the following statements is correct?
The following table has two attributes A and C where A is the primary key and C is the foreign key referencing A with on-delete cascade.
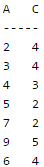
The set of all tuples that must be additionally deleted to preserve referential integrity when the tuple (2,4) is deleted is:
The relation book (title, price) contains the titles and prices of different books. Assuming that no two books have the same price, what does the following SQL query list?
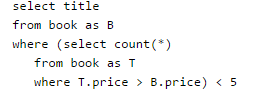
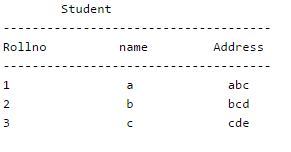
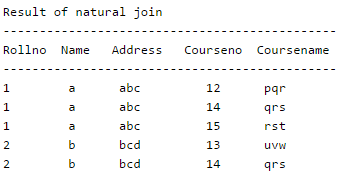
Consider the following relation schema pertaining to a students database:
Student (rollno, name, address)
Enroll (rollno, courseno, coursename)
where the primary keys are shown underlined. The number of tuples in the Student and Enroll tables are 120 and 8 respectively. What are the maximum and minimum number of tuples that can be present in (Student * Enroll), where '*' denotes natural join ?

The employee information in a company is stored in the relation
Employee (name, sex, salary, deptName)
Consider the following SQL query

It returns the names of the department in which

Consider the following SQL query
select distinct al, a2,........., an
from r1, r2,........, rm
where P
For an arbitrary predicate P, this query is equivalent to which of the following relational algebra expressions ?
 is used to select resultant tuples.
is used to select resultant tuples.  is used to select a subset of attributes from the resultant tuples by specifying the names of the attributes. So attributes a1, a2, an are projected from the resultant tuples.
is used to select a subset of attributes from the resultant tuples by specifying the names of the attributes. So attributes a1, a2, an are projected from the resultant tuples. Consider the set of relations shown below and the SQL query that follows.


Q. Which of the following sets is computed by the above query?
Given relations r(w, x) and s(y, z), the result of

is guaranteed to be same as r, provided
In SQL, relations can contain null values, and comparisons with null values are treated as unknown. Suppose all comparisons with a null value are treated as false. Which of the following pairs is not equivalent?
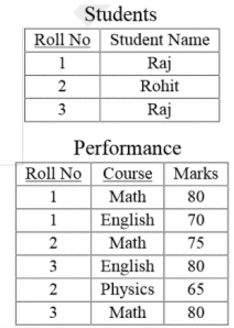
Consider the following three table to store student enrollements in different courses.
Student(EnrollNo, Name)
Course(CourseID, Name)
EnrollMents(EnrollNo, CourseID)
Q. What does the following query do?

Consider the following Employee table
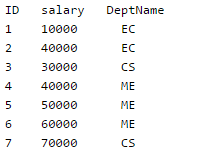
How many rows are there in the result of following query?
Consider the following relations:

The number of rows that will be returned by the SQL query is _________

Consider the following relation
Cinema (theater, address, capacity)
Which of the following options will be needed at the end of the SQL query
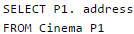
Q. Such that it always finds the addresses of theaters with maximum capacity?
A company maintains records of sales made by its salespersons and pays them commission based on each individual's total sales made in a year. This data is maintained in a table with following schema:
salesinfo = (salespersonid, totalsales, commission)
In a certain year, due to better business results, the company decides to further reward its salespersons by enhancing the commission paid to them as per the following formula:
If commission < = 50000, enhance it by 2% If 50000 < commission < = 100000, enhance it by 4% If commission > 100000, enhance it by 6%
The IT staff has written three different SQL scripts to calculate enhancement for each slab, each of these scripts is to run as a separate transaction as follows:

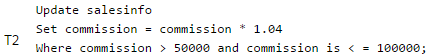

Q. Which of the following options of running these transactions will update the commission of all salespersons correctly




Important Questions for SQL
SQL MCQs with Answers
Online Tests for SQL
|
© EduRev
|
Education Revolution
|



|








