Test: Pipelining- 2 - Computer Science Engineering (CSE) MCQ
13 Questions MCQ Test - Test: Pipelining- 2

A 5 stage pipeline with the stages taking 1, 1, 3, 1, 1 units of time has a throughput of

Which of the following statements is false with regard to instruction pipelining?
Pipelined operation is interrupted whenever two operations being attempted in parallel need same hardware component. Such a conflict can occur if _______.
Consider the unpipelined machine with 10 ns clock cycles. It uses four cycles for ALU operations and branches, whereas five cycles for memory operations. Assume that the relative frequencies of there operations are 40%, 20%, 40% respectively. Suppose that due to clock skew and setup, pipelining the machine adds 1 ns overhead to the clock. How much speed up in the instruction execution rate will we gain from a pipeline?

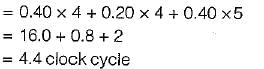
Using a sequential implementation, it takes a total of 320 ns for each instruction, 300 ns for the combinational logic to complete, and 20 ns to store the result (in a register). This means that a throughput will be about 3.12 millions instructions/second. Assuming you switch to a 3 stage pipeline by splitting the combinational logic into three equal parts and all registers take 20 ns to store results
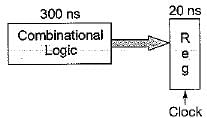
How long will it take for a single instruction to execute in the pipelined implementation?
Using a sequential implementation, it takes a total of 320 ns for each instruction, 300 ns for the combinational logic to complete, and 20 ns to store the result (in a register). This means that a throughput will be about 3.12 millions instructions/second. Assuming you switch to a 3 stage pipeline by splitting the combinational logic into three equal parts and all registers take 20 ns to store results
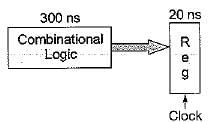
By assuming the pipeline never starts, what will the improvement in throughput be?
A 5 stage pipeline is used to overlap all the instructions except the branch instructions. The target of the branch can’t be fetched till the current instruction is completed. What is throughput of the system if 20% of instructions are branch instructions? Ignore the overhead of buffer register. Each stage is having same amount delay. The pipeline clock is 10 ns. Branch penalty is of 4 cycles.
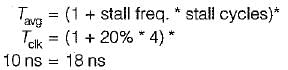
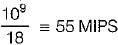
A pipelined processor uses a 4-stage instruction pipeline with the following stages: instruction fetch (IF), Instruction decode (ID), Execute (EX) and Write-back (WB). The arithmetic operations as well as the load and store operations are carried out in the EX stage. The sequence of instructions corresponding to the statement X = (S - R * (P+ G))/T is given below. The values of variables P, Q, R, S and T are available in the registers R0, R 1, R2, R3 and R4 respectively, before the execution of the instruction sequence.
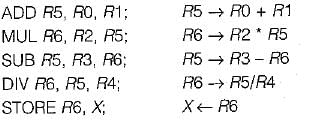
Q. The number of Read-After-Write (RAW) dependencies, Write-After-R ead (WAR) dependencies, and Write-After-Write (WAW) dependencies in the sequence of instructions are, respectively,
A pipelined processor uses a 4-stage instruction pipeline with the following stages: instruction fetch (IF), Instruction decode (ID), Execute (EX) and Write-back (WB). The arithmetic operations as well as the load and store operations are carried out in the EX stage. The sequence of instructions corresponding to the statement X = (S - R * (P+ G))/T is given below. The values of variables P, Q, R, S and T are available in the registers R0, R 1, R2, R3 and R4 respectively, before the execution of the instruction sequence.
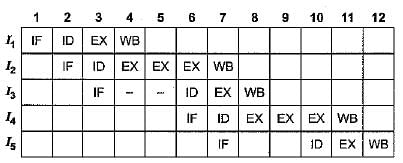
Q. The IF, ID and WB stages take 1 clock cycle each. The EX stage takes 1 clock cycle each for the ADD, SUB and STORE operations, and 3 clock cycles each for MUL and DIV operations. Operand forwarding from the EX stage to the ID stage is used. The number of clock cycles required to complete the sequence of instructions is
We have two designs D1 and D2 for a synchronous pipeline processor. D1 has 5 pipeline stages with execution times of 3 nsec, 2 nsec, 4 nsec, 2 nsec and 3 nsec while the design D2 has 8 pipeline stages each with 2 nsec execution time. How much time can be saved using design D2 over design D1 for executing 100 instructions?
Suppose that an unpipelined processor has a cycle time of 25 ns, and that its datapath is made up of modules with latencies of 2,3,4,7,3,2 and 4 ns (in that order). In pipelining this processor, it is not possible to rearrange the order of the modules (for examples, putting the register read stage before the instruction decode stage) or to divide a module into multiple pipeline stages (for complexity reasons). Given pipeline latches with 1 ns latency:
If the processor is divided into the rewest number of stages that allow is to achieve the minimum latency from part 1, what is the latency of the pipeline?




Important Questions for Pipelining- 2
Pipelining- 2 MCQs with Answers
Online Tests for Pipelining- 2
|
© EduRev
|
Education Revolution
|



|








