Test: Memory Management & Virtual Memory- 2 - Computer Science Engineering (CSE) MCQ
30 Questions MCQ Test GATE Computer Science Engineering(CSE) 2025 Mock Test Series - Test: Memory Management & Virtual Memory- 2

Which of the following is NOT an advantage of using shared, dynamically linked libraries as opposed to using statically linked libraries ?
A processor uses 2-level page tables for virtual to physical address translation. Page tables for both levels are stored in the main memory. Virtual and physical addresses are both 32 bits wide. The memory is byte addressable. For virtual to physical address translation, the 10 most significant bits of the virtual address are used as index into the first level page table while the next 10 bits are used as index into the second level page table. The 12 least significant bits of the virtual address are used as offset within the page. Assume that the page table entries in both levels of page tables are 4 bytes wide. Further, the processor has a translation look-aside buffer (TLB), with a hit rate of 96%. The TLB caches recently used virtual page numbers and the corresponding physical page numbers. The processor also has a physically addressed cache with a hit rate of 90%. Main memory access time is 10 ns, cache access time is 1 ns, and TLB access time is also 1 ns. Assuming that no page faults occur, the average time taken to access a virtual address is approximately (to the nearest 0.5 ns)
| 1 Crore+ students have signed up on EduRev. Have you? Download the App |
A processor uses 2-level page tables for virtual to physical address translation. Page tables for both levels are stored in the main memory. Virtual and physical addresses are both 32 bits wide. The memory is byte addressable. For virtual to physical address translation, the 10 most significant bits of the virtual address are used as index into the first level page table while the next 10 bits are used as index into the second level page table. The 12 least significant bits of the virtual address are used as offset within the page. Assume that the page table entries in both levels of page tables are 4 bytes wide. Further, the processor has a translation look-aside buffer (TLB), with a hit rate of 96%. The TLB caches recently used virtual page numbers and the corresponding physical page numbers. The processor also has a physically addressed cache with a hit rate of 90%. Main memory access time is 10 ns, cache access time is 1 ns, and TLB access time is also 1 ns. Suppose a process has only the following pages in its virtual address space: two contiguous code pages starting at virtual address 0x00000000, two contiguous data pages starting at virtual address 0×00400000, and a stack page starting at virtual address 0×FFFFF000. The amount of memory required for storing the page tables of this process is:
Which of the following is not a form of memory?
The optimal page replacement algorithm will select the page that
Dynamic linking can cause security concerns because:
Which of the following statements is false?
The process of assigning load addresses to the various parts of the program and adjusting the code and date in the program to reflect the assigned addresses is called
Consider a virtual memory system with FIFO page replacement policy. For an arbitrary page access pattern, increasing the number of page frames in main memory will
Consider a machine with 64 MB physical memory and a 32-bit virtual address space. If the page size is 4KB, what is the approximate size of the page table?
Suppose the time to service a page fault is on the average 10 milliseconds, while a memory access takes 1 microsecond. Then a 99.99% hit ratio results in average memory access time of
Consider a system with byte-addressable memory, 32 bit logical addresses, 4 kilobyte page size and page table entries of 4 bytes each. The size of the page table in the system in megabytes is ___________
A computer system implements a 40 bit virtual address, page size of 8 kilobytes, and a 128-entry translation look-aside buffer (TLB) organized into 32 sets each having four ways. Assume that the TLB tag does not store any process id. The minimum length of the TLB tag in bits is _________
Consider six memory partitions of size 200 KB, 400 KB, 600 KB, 500 KB, 300 KB, and 250 KB, where KB refers to kilobyte. These partitions need to be allotted to four processes of sizes 357 KB, 210 KB, 468 KB and 491 KB in that order. If the best fit algorithm is used, which partitions are NOT allotted to any process?
A Computer system implements 8 kilobyte pages and a 32-bit physical address space. Each page table entry contains a valid bit, a dirty bit three permission bits, and the translation. If the maximum size of the page table of a process is 24 megabytes, the length of the virtual address supported by the system is _______________ bits
Which one of the following is NOT shared by the threads of the same process?
Consider a fully associative cache with 8 cache blocks (numbered 0-7) and the following sequence of memory block requests: 4, 3, 25, 8, 19, 6, 25, 8, 16, 35, 45, 22, 8, 3, 16, 25, 7 If LRU replacement policy is used, which cache block will have memory block 7?
The storage area of a disk has innermost diameter of 10 cm and outermost diameter of 20 cm. The maximum storage density of the disk is 1400bits/cm. The disk rotates at a speed of 4200 RPM. The main memory of a computer has 64-bit word length and 1µs cycle time. If cycle stealing is used for data transfer from the disk, the percentage of memory cycles stolen for transferring one word is
A disk has 200 tracks (numbered 0 through 199). At a given time, it was servicing the request of reading data from track 120, and at the previous request, service was for track 90. The pending requests (in order of their arrival) are for track numbers. 30 70 115 130 110 80 20 25. How many times will the head change its direction for the disk scheduling policies SSTF(Shortest Seek Time First) and FCFS (First Come Fist Serve)
In a virtual memory system, size of virtual address is 32-bit, size of physical address is 30-bit, page size is 4 Kbyte and size of each page table entry is 32-bit. The main memory is byte addressable. Which one of the following is the maximum number of bits that can be used for storing protection and other information in each page table entry?
In a particular Unix OS, each data block is of size 1024 bytes, each node has 10 direct data block addresses and three additional addresses: one for single indirect block, one for double indirect block and one for triple indirect block. Also, each block can contain addresses for 128 blocks. Which one of the following is approximately the maximum size of a file in the file system?
A two-way switch has three terminals a, b and c. In ON position (logic value 1), a is connected to b, and in OFF position, a is connected to c. Two of these two-way switches S1 and S2 are connected to a bulb as shown below.
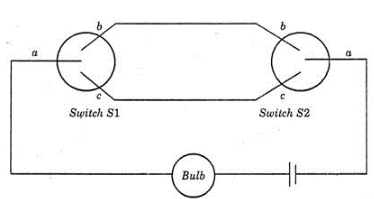
Which of the following expressions, if true, will always result in the lighting of the bulb ?
Consider a 2-way set associative cache memory with 4 sets and total 8 cache blocks (0-7) and a main memory with 128 blocks (0-127). What memory blocks will be present in the cache after the following sequence of memory block references if LRU policy is used for cache block replacement. Assuming that initially the cache did not have any memory block from the current job? 0 5 3 9 7 0 16 55
A disk has 8 equidistant tracks. The diameters of the innermost and outermost tracks are 1 cm and 8 cm respectively. The innermost track has a storage capacity of 10 MB. What is the total amount of data that can be stored on the disk if it is used with a drive that rotates it with (i) Constant Linear Velocity (ii) Constant Angular Velocity?
Consider a computer system with 40-bit virtual addressing and page size of sixteen kilobytes. If the computer system has a one-level page table per process and each page table entry requires 48 bits, then the size of the per-process page table is _________megabytes.
Note : This question was asked as Numerical Answer Type.
Consider a computer system with ten physical page frames. The system is provided with an access sequence a1, a2, ..., a20, a1, a2, ..., a20), where each ai number. The difference in the number of page faults between the last-in-first-out page replacement policy and the optimal page replacement policy is __________
[Note that this question was originally Fill-in-the-Blanks question]
In which one of the following page replacement algorithms it is possible for the page fault rate to increase even when the number of allocated frames increases?
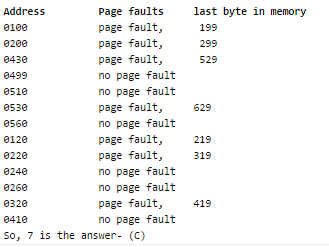
The address sequence generated by tracing a particular program executing in a pure demand paging system with 100 bytes per page is
0100, 0200, 0430, 0499, 0510, 0530, 0560, 0120, 0220, 0240, 0260, 0320, 0410.
Suppose that the memory can store only one page and if x is the address which causes a page fault then the bytes from addresses x to x + 99 are loaded on to the memory.
Q. How many page faults will occur ?
A paging scheme uses a Translation Look-aside Buffer (TLB). A TLB-access takes 10 ns and a main memory access takes 50 ns. What is the effective access time(in ns) if the TLB hit ratio is 90% and there is no page-fault?
|
55 docs|215 tests
|
|
55 docs|215 tests
|
Top Courses for Computer Science Engineering (CSE)




Important Questions for Memory Management & Virtual Memory- 2
Memory Management & Virtual Memory- 2 MCQs with Answers
Online Tests for Memory Management & Virtual Memory- 2 GATE Computer Science Engineering(CSE) 2025 Mock Test Series
|
© EduRev
|
Education Revolution
|



Follow Us
|







