Test: Regular Expressions & Finite Automata- 4 - Computer Science Engineering (CSE) MCQ
20 Questions MCQ Test GATE Computer Science Engineering(CSE) 2025 Mock Test Series - Test: Regular Expressions & Finite Automata- 4

Which of the following languages is generated by the given grammar?
S -> aS|bS|ε
Which one of the following regular expressions represents the language: the set of all binary strings having two consecutive 0s and two consecutive 1s?
| 1 Crore+ students have signed up on EduRev. Have you? Download the App |
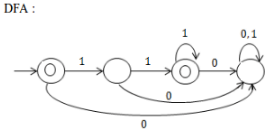
The number of states in the minimum sized DFA that accepts the language defined by the regular expression (0+1)*(0+1)(0+1)* is __________________
[Note that this question was originally asked as Fill-in-the-Blanks type]
[Note that this question was originally asked as Fill-in-the-Blanks type]
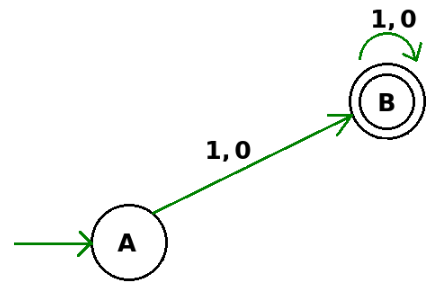
Consider the following two statements:
I. If all states of an NFA are accepting states then the language accepted by the NFA is Σ∗ .
II. There exists a regular language A such that for all languages B, A ∩ B is regular.
Q. Which one of the following is CORRECT?
In the automaton below, s is the start state and t is the only final state.
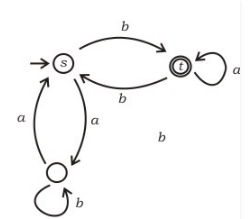
Consider the strings u = abbaba, v = bab, and w = aabb. Which of the following statements is true?
In the context-free grammar below, S is the start symbol, a and b are terminals, and ϵ denotes the empty string S → aSa | bSb | a | b | ϵ Which of the following strings is NOT generated by the grammar?
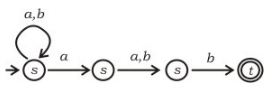
Which regular expression best describes the language accepted by the non-deterministic automaton below?
Consider an ambiguous grammar G and its disambiguated version D. Let the language recognized by the two grammars be denoted by L(G) and L(D) respectively. Which one of the following is true ?
Which of the following regular expressions describes the language over {0, 1} consisting of strings that contain exactly two 1's?
Let N be an NFA with n states and let M be the minimized DFA with m states recognizing the same language. Which of the following in NECESSARILY true?
If the final states and non-final states in the DFA below are interchanged, then which of the following languages over the alphabet {a,b} will be accepted by the new DFA?
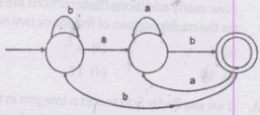
Consider the following languages.
L1 = {ai bj ck | i = j, k ≥ 1}
L1 = {ai bj | j = 2i, i ≥ 0}
Q. Which of the following is true?
Which of the following languages is (are) non-regular? L1 = {0m1n | 0 ≤ m ≤ n ≤ 10000} L2 = {w | w reads the same forward and backward} L3 = {w ∊ {0, 1} * | w contains an even number of 0's and an even number of 1's}
Consider the following two finite automata. M1 accepts L1 and M2 accepts L2.
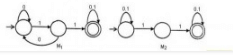
Q. Which one of the following is TRUE?
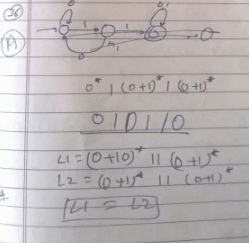
Which of the following intuitive definition is true about LR(1) Grammar.
Consider the Following regular expressions
r1 = 1(0 + 1)*
r2 = 1(1 + 0)+
r3 = 11*0
Q. What is the relation between the languages generated by the regular expressions above ?
Consider regular expression r, where r = (11 + 111)* over Ʃ = {0, 1}. Number of states in minimal NFA and DFA respectively are:
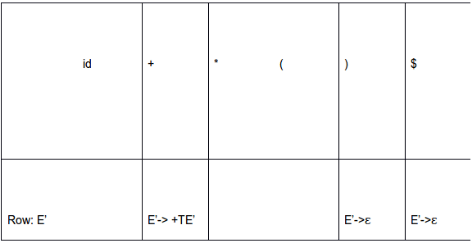
Consider the grammar G.
E -> TE’
E’ -> +TE’ | ԑ
T’ -> FT’
T’ -> *FT’ | ԑ
F -> (E) | id
If LL(1) parsing table is constructed using the grammar G, then how many entries are present in the row that represents E’ nonterminal ? (consider the entries which are not error/not blank entries)
Let, init (L) = {set of all prefixes of L},
Let L = {w | w has equal number of 0’s and 1’s}
init (L) will contain:
Suppose M1 and M2 are two TM’s such that L(M1) = L(M2). Then
|
55 docs|215 tests
|
|
55 docs|215 tests
|
Top Courses for Computer Science Engineering (CSE)




Important Questions for Regular Expressions & Finite Automata- 4
Regular Expressions & Finite Automata- 4 MCQs with Answers
Online Tests for Regular Expressions & Finite Automata- 4 GATE Computer Science Engineering(CSE) 2025 Mock Test Series
|
© EduRev
|
Education Revolution
|



Follow Us
|







