Test: Instruction Pipeline - Electronics and Communication Engineering (ECE) MCQ
10 Questions MCQ Test Topicwise Question Bank for Electronics Engineering - Test: Instruction Pipeline

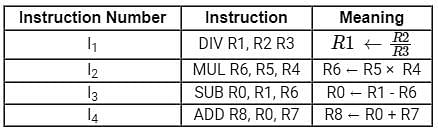
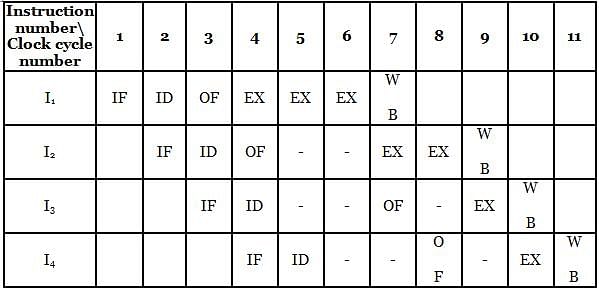
Consider a 5-stage pipeline having stages as Instruction Fetch (IF), Instruction Decode (ID), Operand Fetch (OF), Execute (EX) and Write Back (WB). Here we are given 4 instructions. IF, ID, OF and WB stages take 1 clock cycle each, but the EX-stage takes 1 cycle for ADD and SUB, 2 cycles for MUL and 3 cycles for DIV operation. If the operand forwarding technique is used from EX stage to OF stage and the clock rate of pipeline processor is 5 GHz, then choose the correct statement(s), considering the below table:
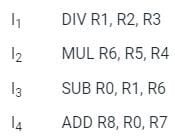
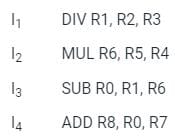
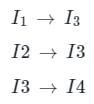
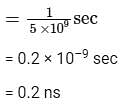
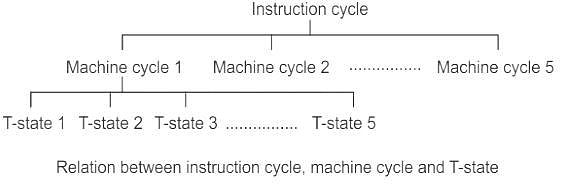
In microprocessors, the IC (instruction cycle), FC (fetch cycle) and EC (execution cycle) are related as
| 1 Crore+ students have signed up on EduRev. Have you? Download the App |
A non-pipelined CPU has 12 general purpose registers (R0, R1, R2,….R12). Following operations are supported

MUL operations takes two clock cycles, ADD takes one clock cycle.
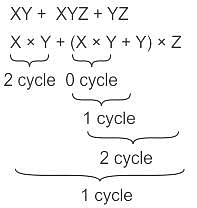
Calculate minimum number of clock cycles required to compute the value of the expression XY + XYZ + YZ. The variables X, Y, Z are initially available in registers R0, R1 and R2 and contents of these registers must not be modified.
MUL operations takes two clock cycles, ADD takes one clock cycle.
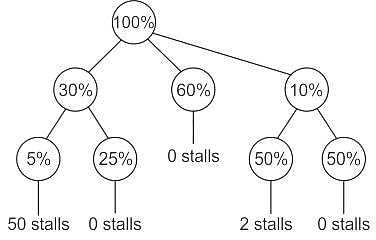
Consider a non-pipelined processor operating at 2.5 GHz. It takes 5 clock cycles to complete an instruction. You are going to make a 5-stage pipeline out of this processor. Overheads associated with pipelining force you to operate the pipelined processor at 2 GHz. In a given program, assume that 30% are memory instructions, 60% are ALU instructions and the rest are branch instructions. 5% of the memory instructions cause stalls of 50 clock cycles each due to cache misses and 50% of the branch instructions cause stalls of 2 cycles each. Assume that there are no stalls associated with the execution of ALU instructions. For this program, the speedup achieved by the pipelined processor over the non-pipelined processor (round off to 2 decimal places) is _____.
A non-pipeline system takes 50ns to process a task. The same task can be processed in six-segment pipeline with a clockcycle of 10ns. Determine approximately the speedup ratio of the pipeline for 500 tasks.
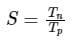
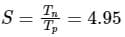
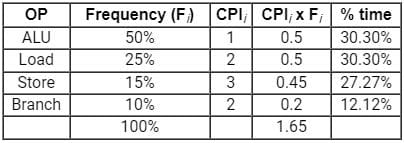
Consider the following table:

Which of the following is true about the average CPI of the above given table?
Consider the following sequence of micro-operations.

Which one of the following is a possible operation performed by this sequence?
Top Courses for Electronics and Communication Engineering (ECE)




Important Questions for Instruction Pipeline
Instruction Pipeline MCQs with Answers
Online Tests for Instruction Pipeline Topicwise Question Bank for Electronics Engineering
|
© EduRev
|
Education Revolution
|



|







