Relational Model | GATE Computer Science Engineering(CSE) 2025 Mock Test Series - Computer Science Engineering (CSE) PDF Download
| Table of contents |
|
| Introduction |
|
| What is Relational Model? |
|
| Constraints in Relational Model |
|
| Codd Rules |
|
| Keys in Relational Model (Candidate, Super, Primary, Alternate and Foreign) |
|
Introduction
Relational Model was proposed by E.F. Codd to model data in the form of relations or tables. After designing the conceptual model of Database using ER diagram, we need to convert the conceptual model into the relational model which can be implemented using any RDMBS languages like Oracle SQL, MySQL etc. So we will see what Relational Model is.
What is Relational Model?
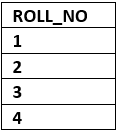
Relational Model represents how data is stored in Relational Databases. A relational database stores data in the form of relations (tables). Consider a relation STUDENT with attributes ROLL_NO, NAME, ADDRESS, PHONE and AGE shown in Table below.
STUDENT

Important Terminologies
- Attribute: Attributes are the properties that define a relation. e.g.; ROLL_NO, NAME
- Relation Schema: A relation schema represents name of the relation with its attributes. e.g.; STUDENT (ROLL_NO, NAME, ADDRESS, PHONE and AGE) is relation schema for STUDENT. If a schema has more than 1 relation, it is called Relational Schema.
- Tuple: Each row in the relation is known as tuple. The above relation contains 4 tuples, one of which is shown as:

- Relation Instance: The set of tuples of a relation at a particular instance of time is called as relation instance. Table (STUDENT shows the relation instance of STUDENT at a particular time. It can change whenever there is insertion, deletion or updation in the database.
- Degree: The number of attributes in the relation is known as degree of the relation. The STUDENT relation defined above has degree 5.
- Cardinality: The number of tuples in a relation is known as cardinality. The STUDENT relation defined above has cardinality 4.
- Column: Column represents the set of values for a particular attribute. The column ROLL_NO is extracted from relation STUDENT.
- NULL Values: The value which is not known or unavailable is called NULL value. It is represented by blank space. e.g.; PHONE of STUDENT having ROLL_NO 4 is NULL.
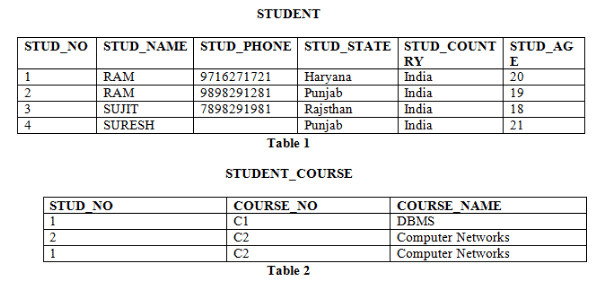
- Table 1 and Table 2 represent relational model having two relations STUDENT and STUDENT_COURSE

Constraints in Relational Model
While designing Relational Model, we define some conditions which must hold for data present in database are called Constraints. These constraints are checked before performing any operation (insertion, deletion and updation) in database. If there is a violation in any of constrains, operation will fail.
Domain Constraints
These are attribute level constraints. An attribute can only take values which lie inside the domain range. e.g,; If a constrains AGE>0 is applied on STUDENT relation, inserting negative value of AGE will result in failure.
Key Integrity
Every relation in the database should have atleast one set of attributes which defines a tuple uniquely. Those set of attributes is called key. e.g.; ROLL_NO in STUDENT is a key. No two students can have same roll number. So a key has two properties:
- It should be unique for all tuples.
- It can’t have NULL values.
Referential Integrity
When one attribute of a relation can only take values from other attribute of same relation or any other relation, it is called referential integrity. Let us suppose we have 2 relations
STUDENT
BRANCH
BRANCH_CODE of STUDENT can only take the values which are present in BRANCH_CODE of BRANCH which is called referential integrity constraint. The relation which is referencing to other relation is called REFERENCING RELATION (STUDENT in this case) and the relation to which other relations refer is called REFERENCED RELATION (BRANCH in this case).
Anomalies
An anomaly is an irregularity or something which deviates from the expected or normal state. When designing databases, we identify three types of anomalies: Insert, Update and Delete.
Insertion Anomaly in Referencing Relation
We can’t insert a row in REFERENCING RELATION if referencing attribute’s value is not present in referenced attribute value. e.g.; Insertion of a student with BRANCH_CODE ‘ME’ in STUDENT relation will result in error because ‘ME’ is not present in BRANCH_CODE of BRANCH.
Deletion/ Updation Anomaly in Referenced Relation
We can’t delete or update a row from REFERENCED RELATION if value of REFRENCED ATTRIBUTE is used in value of REFERENCING ATTRIBUTE. e.g; if we try to delete tuple from BRANCH having BRANCH_CODE ‘CS’, it will result in error because ‘CS’ is referenced by BRANCH_CODE of STUDENT, but if we try to delete the row from BRANCH with BRANCH_CODE CV, it will be deleted as the value is not been used by referencing relation. It can be handled by following method:
On Delete Cascade
It will delete the tuples from REFERENCING RELATION if value used by REFERENCING ATTRIBUTE is deleted from REFERENCED RELATION. e.g; if we delete a row from BRANCH with BRANCH_CODE ‘CS’, the rows in STUDENT relation with BRANCH_CODE CS (ROLL_NO 1 and 2 in this case) will be deleted.
On Update Cascade
It will update the REFERENCING ATTRIBUTE in REFERENCING RELATION if attribute value used by REFERENCING ATTRIBUTE is updated in REFERENCED RELATION. e.g;, if we update a row from BRANCH with BRANCH_CODE ‘CS’ to ‘CSE’, the rows in STUDENT relation with BRANCH_CODE CS (ROLL_NO 1 and 2 in this case) will be updated with BRANCH_CODE ‘CSE’.
Codd Rules
Codd rules were proposed by E.F. Codd which should be satisfied by relational model.
- Information Rule: Data stored in Relational model must be a value of some cell of a table.
- Guaranteed Access Rule: Every data element must be accessible by table name, its primary key and name of attribute whose value is to be determined.
- Systematic Treatment of NULL values: NULL value in database must only correspond to missing, unknown or not applicable values.
- Active Online Catalog: Structure of database must be stored in an online catalog which can be queried by authorized users.
- Comprehensive Data Sub-language Rule: A database should be accessible by a language supported for definition, manipulation and transaction management operation.
- View Updating Rule: Different views created for various purposes should be automatically updatable by the system.
- High level insert, update and delete rule: Relational Model should support insert, delete, update etc. operations at each level of relations. Also, set operations like Union, Intersection and minus should be supported.
- Physical data independence: Any modification in the physical location of a table should not enforce modification at application level.
- Logical data independence: Any modification in logical or conceptual schema of a table should not enforce modification at application level. For example, merging of two tables into one should not affect application accessing it which is difficult to achieve.
- Integrity Independence: Integrity constraints modified at database level should not enforce modification at application level.
- Distribution Independence: Distribution of data over various locations should not be visible to end-users.
- Non-Subversion Rule: Low level access to data should not be able to bypass integrity rule to change data.
Keys in Relational Model (Candidate, Super, Primary, Alternate and Foreign)
Candidate Key
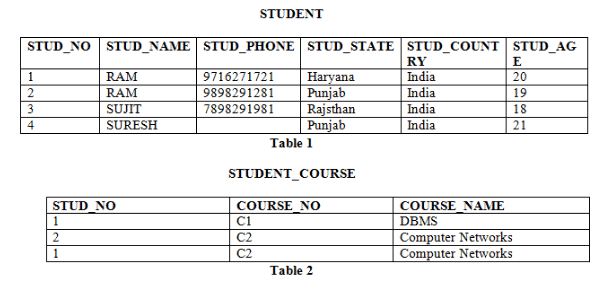
The minimal set of attribute which can uniquely identify a tuple is known as candidate key. For Example, STUD_NO in STUDENT relation.
- The value of Candidate Key is unique and non-null for every tuple.
- There can be more than one candidate key in a relation. For Example, STUD_NO as well as STUD_PHONE both are candidate keys for relation STUDENT.
- The candidate key can be simple (having only one attribute) or composite as well. For Example, {STUD_NO, COURSE_NO} is a composite candidate key for relation STUDENT_COURSE.
Super Key
The set of attributes which can uniquely identify a tuple is known as Super Key. For Example, STUD_NO, (STUD_NO, STUD_NAME) etc.
- Adding zero or more attributes to candidate key generates super key.
- A candidate key is a super key but vice versa is not true.
Primary Key
There can be more than one candidate key in a relation out of which one can be chosen as primary key. For Example, STUD_NO as well as STUD_PHONE both are candidate keys for relation STUDENT but STUD_NO can be chosen as primary key (only one out of many candidate keys).
Alternate Key
The candidate key other than primary key is called as alternate key. For Example, STUD_NO as well as STUD_PHONE both are candidate keys for relation STUDENT but STUD_PHONE will be alternate key (only one out of many candidate keys).
Foreign Key
If an attribute can only take the values which are present as values of some other attribute, it will be foreign key to the attribute to which it refers. The relation which is being referenced is called referenced relation and corresponding attribute is called referenced attribute and the relation which refers to referenced relation is called referencing relation and corresponding attribute is called referencing attribute. Referenced attribute of referencing attribute should be primary key. For Example, STUD_NO in STUDENT_COURSE is a foreign key to STUD_NO in STUDENT relation.
FAQs on Relational Model - GATE Computer Science Engineering(CSE) 2025 Mock Test Series - Computer Science Engineering (CSE)
| 1. What is the relational model? |  |
| 2. What are constraints in the relational model? | |
| 3. What are Codd's rules in the relational model? | |
| 4. What are the different types of keys in the relational model? | |
| 5. How does the relational model ensure data integrity? | |

|
2K Views |

|
4.89/5 Rating |

|
Dec 22, 2024 Last updated |
|
55 docs|215 tests
|

|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
Semester Notes
,Exam
,Free
,Extra Questions
,Relational Model | GATE Computer Science Engineering(CSE) 2025 Mock Test Series - Computer Science Engineering (CSE)
,ppt
,video lectures
,shortcuts and tricks
,study material
,MCQs
,Viva Questions
,practice quizzes
,Relational Model | GATE Computer Science Engineering(CSE) 2025 Mock Test Series - Computer Science Engineering (CSE)
,Sample Paper
,Summary
,Relational Model | GATE Computer Science Engineering(CSE) 2025 Mock Test Series - Computer Science Engineering (CSE)
,mock tests for examination
,Important questions
,Previous Year Questions with Solutions
,Objective type Questions
,past year papers
;






Relational Model Free PDF Download
Importance of Relational Model
Relational Model Notes
Relational Model Computer Science Engineering (CSE) Questions
Study Relational Model on the App
|
© EduRev
|
Education Revolution
|



|




