Best linear unbiased estimators, CSIR-NET Mathematical Sciences | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

Best Linear Unbiased Estimates
Definition: The Best Linear Unbiased Estimate (BLUE) of a parameter θ based on data Y is
1. alinear function of Y. That is, the estimator can be written as b'Y,
2. unbiased (E[b'Y] = θ), and
3. has the smallest variance among all unbiased linear estimators.
Theorem 1'.1.1: For any linear combination 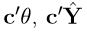 is the BLUEof c'θ, where
is the BLUEof c'θ, where 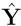 is the least-squaresorthogonalprojection of Y onto R(X). Proof: See lecture notes # 8
is the least-squaresorthogonalprojection of Y onto R(X). Proof: See lecture notes # 8
Corollary 1'.1.2: If rank(Xn×p) = p, then, for any a, 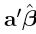 is the BLUE of a'β
is the BLUE of a'β
Note: The Gauss-Markov theorem generalizes this result to the less than full rank case, for certain linear combinations a'β (the estimable functions).
Proof of Corollary 1'.1.2:
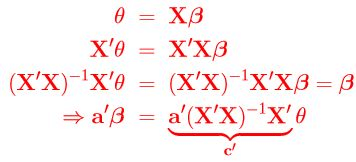
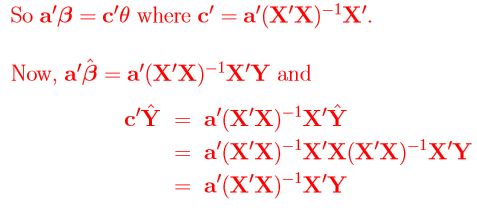
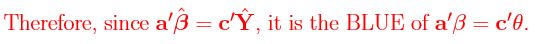
1'.2. Estimable Functions
In the less than full rank case, only certain linear combinations of the components of β can be unbiasedly estimated.
Definition: A linear combination a'β is estimable if it has a linear unbiased estimate, i.e., E[b'Y] = a'β for some b for all β.
Lemma 1'.2.1: (i) a'β is estimable if and only if a ∈ R(X'). Proof: E[b'Y] = b'Xβ, which equals a'β for all β if and only if a = X'b. (ii) If a'β is estimable, there is a unique b∗ ∈ R(X) such that a = X'b∗. Proof: a'β is estimable so using (i) a = X'b. Any  can be uniquely decomposed as
can be uniquely decomposed as 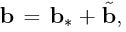 , where b∗ ∈ R(X), and
, where b∗ ∈ R(X), and 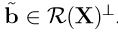 . Then
. Then
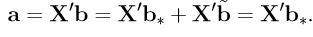
Comment: Part (i) of the lemma may be a little bit surprising since all of a sudden we are talking about the row space of X, not the column space. However, the idea behind the result need not be mysterious. Every observation we have is an unbiased estimate of its expected value; the expected value of an observation is some linear combination of parameters. Such linear combinations of parameters is therefore estimable. These correspond exactly to the rows of X. Clearly, also, linear combinations of estimable functions should be estimable. These are the vectors that are spanned by the rows of X – the row space of X.
1'.3. Gauss-Markov Theorem
Note: In the full rank case (r = p), any a'β is estimable. In particular,
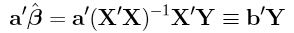
is a linear unbiased estimate of a'β. In this case we also know that 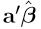 is the BLUE (Corollary 1'.1.2).
is the BLUE (Corollary 1'.1.2).
Theorem 1'.3.1: (Gauss-Markov). If a'β is estimable, then
(i) a' 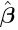 is unique (i.e., the same for all solutions to the normal equations ).
is unique (i.e., the same for all solutions to the normal equations ).
(ii) a' is the BLUE of a'β.
Proof: (i) By Lemma 1'.2.1, a = X'b∗ for a unique b∗ ∈ R(X). Therefore,
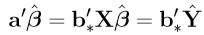
is unique because 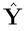 is unique. (In fact
is unique. (In fact 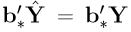 since
since
b∗ ∈ R(X), so that 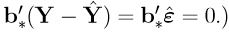
(ii) By Theorem 1'.1.1, 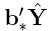 is the BLUE of
is the BLUE of 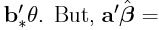 from part (i) and
from part (i) and 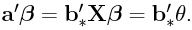
1'.4. The Variance of 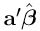
Lemma 1'.4.1: If a'β is estimable then
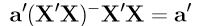
for any generalized inverse (X'X)−.
Proof: If a'β is estimable, then a = X'b∗, b∗ ∈ R(X) by Lemma 1'.2.1. Then
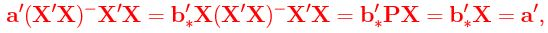
regardless of the generalized inverse used.
Theorem 1'.4.2: If a'β is estimable, then
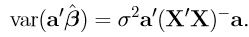
Proof: Using an estimate 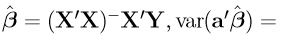
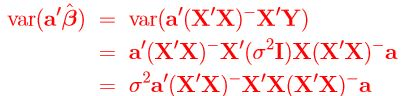
(by the Lemma) 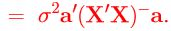
Note that

is unique (same for all generalized inverses (X'X)−).
In-class exercise: One–way ANOVA with K groups. There are K groups with J observations from each group. The model is
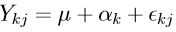
for k = 1,...,K and j = 1,...,J. As usual, E[ε] = ' and var(ε) = σ2I. In this setting we are almost never interested in the µ parameter (why not?). What are the estimable functions of the α parameters?
|
558 videos|198 docs
|
FAQs on Best linear unbiased estimators, CSIR-NET Mathematical Sciences - Mathematics for IIT JAM, GATE, CSIR NET, UGC NET
| 1. What are the properties of best linear unbiased estimators? |  |
| 2. How are best linear unbiased estimators (BLUE) different from other estimators? | |
| 3. How are best linear unbiased estimators (BLUE) calculated? | |
| 4. What are the applications of best linear unbiased estimators (BLUE)? | |
| 5. Can best linear unbiased estimators (BLUE) be used in non-linear models? | |



CSIR NET
,Best linear unbiased estimators
,GATE
,Best linear unbiased estimators
,video lectures
,Summary
,study material
,Exam
,practice quizzes
,Sample Paper
,Objective type Questions
,CSIR NET
,CSIR NET
,Previous Year Questions with Solutions
,UGC NET
,Free
,UGC NET
,GATE
,Best linear unbiased estimators
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Important questions
,MCQs
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Extra Questions
,ppt
,GATE
,Semester Notes
,UGC NET
,Viva Questions
,shortcuts and tricks
,past year papers
,mock tests for examination
;


Best linear unbiased estimators, CSIR-NET Mathematical Sciences Free PDF Download
Importance of Best linear unbiased estimators, CSIR-NET Mathematical Sciences
Best linear unbiased estimators, CSIR-NET Mathematical Sciences Notes
Best linear unbiased estimators, CSIR-NET Mathematical Sciences Mathematics Questions
Study Best linear unbiased estimators, CSIR-NET Mathematical Sciences on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!