Canonical correlation - 1, CSIR-NET Mathematical Sciences | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

LEARNING OBJECTIVES
Upon completing this chapter, you should be able to do the following:
State the similarities and differences between multiple regression, factor analysis, discriminant analysis, and canonical correlation.
Summarize the conditions that must be met for application of canonical correlation analysis.
State what the canonical root measures and point out its limitations.
State how manyindependent canonical functions can be defined between the two sets of original variables.
Compare the advantages and disadvantages of the three methods for interpreting the nature of canonical functions.
Define redundancyand compare it with multiple regression’s R2.
CHAPTER PREVIEW
Until recent years, canonical correlation analysis was a relatively unknown statistical technique. As with almost all of the multivariate techniques, the availability of computer programs has facilitated its increased application to research problems. It is particularly useful in situations in which multiple output measures such as satisfaction, purchase, or sales volume are available. If the independent variables were only categorical, multivariate analysis of variance could be used. But what if the independent variables are metric? Canonical correlation is the answer, allowing for the assessment of the relationship between metric independent variables and multiple dependent measures. Canonical correlation is considered to be the general model on which many other multivariate techniques are based because it can use both metric and nonmetric data for either the dependent or independent variables. We express the general form of canonical analysis as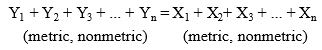
This chapter introduces the researcher to the multivariate statistical technique of canonical correlation analysis. Specifically, we (1) describe the nature of canonical correlation analysis, (2) illustrate its application, and (3) discuss its potential advantages and limitations.
KEY TERMS Before starting the chapter, review the key terms to develop an understanding of the concepts and terminology used. Throughout the chapter the key terms appear in boldface. Other points of emphasis in the chapter are italicized. Also, crossreferences within the KeyTerms appear initalics.
Canonical correlation Measure of the strength of the overall relationships between the linear composites (canonical variates) for the independent and dependent variables. In effect, it represents the bivariate correlation between the two canonical variates.
Canonical cross-loadings Correlation of each observed independent or dependent variable with the opposite canonical variate. For example, the independent variables are correlated with the dependent canonical variate. They can be interpreted like canonical loadings, but with the opposite canonical variate.
Canonical function Relationship (correlational) between two linear composites (canonical variates). Each canonical function has two canonical variates, one for the set of dependent variables and one for the set of independent variables. The strength of the relationship is given bythe canonical correlation.
Canonical loadings Measure of the simple linear correlation between the independent variables and their respective canonical variates. These can be interpreted like factor loadings, and are also known as canonical structure correlations.
Canonical roots Squared canonical correlations, which provide an estimate of the amount of shared variance between the respective optimally weighted canonical variates of dependent and independent variables. Also known as eigenvalues.
Canonical variates Linear combinations that represent the weighted sum of two or more variables and can be defined for either dependent or independent variables. Also referred to as linear composites, linear compounds, and linear combinations.
Eigenvalues See canonical roots.
Linear composites See canonical variates.
Orthogonal Mathematical constraint specifying that the canonical functions are independent of each other. In other words, the canonical functions are derived so that each is at a right angle to all other functions when plotted in multivariate space, thus ensuring statistical independence between the canonical functions.
Redundancy index Amount of variance in a canonical variate (dependent or independent) explained by the other canonical variate in the canonical function. It can be computed for both the dependent and the independent canonical variates in each canonical function. For example, a redundancy index of the dependent variate represents the amount of variance in the dependent variables explained by the independent canonical variate.
Multiple regression analysis is a multivariate technique which can predict the value of a single (metric) dependent variable from a linear function of a set of independent variables. For some research problems, however, interest may not center on a single dependent variable; rather, the researcher may be interested in relationships between sets of multiple dependent and multiple independent variables. Canonical correlation analysis is a multivariate statistical model that facilitates the study of interrelationships among sets of multiple dependent variables and multiple independent variables [5, 6]. Whereas multiple regression predicts a single dependent variable from a set of multiple independent variables, canonical correlation simultaneously predicts multiple dependent variables from multiple independent variables.
Canonical correlation places the fewest restrictions on the types of data on which it operates. Because the other techniques impose more rigid restrictions, it is generally believed that the information obtained from them is of higher quality and may be presented in a more interpretable manner. For this reason, many researchers view canonical correlation as a last-ditch effort, to be used when all other higher-level techniques have been exhausted. But in situations with multiple dependent and independent variables, canonical correlation is the most appropriate and powerful multivariate technique. It has gained acceptance in manyfields and represents a useful tool for multivariate analysis, particularly as interest has spread to considering multiple dependent variables.
Hypothetical Example of Canonical Correlation
To clarify further the nature of canonical correlation, let us consider an extension ofa simple example of multiple regression analysis. Assume that a survey was conducted to understand the relationships between family size and income as predictors of the number of credit cards a family would hold. Such a problem would involve examining the relationship between two independent variables and a single dependent variable.
Suppose the researcher then became interested in the broader concept of credit usage. To measure credit usage, the researcher considered not only the number of credit cards held by the family but also the family’s average monthly dollar charges on all credit cards. These two measures were felt to give a much better perspective on a family’s credit card usage. Readers interested in the approach of using multiple indicators to represent a concept are referred to discussions of Factor Analysis and Structural Equation Modeling. The problem now involves predicting two dependent measures simultaneously (number of credit cards and average dollar charges).
Multiple regression is capable of handling only a single dependent variable. Multivariate analysis of variance could be used, but only if all of the independent variables were nonmetric, which is not the case in this problem. Canonical correlation represents the only technique available for examining the relationship with multiple dependent variables.
The problem of predicting credit usage is illustrated in Table 8.1. The two dependent variables used to measure credit usage—number of credit cards held by the family and average monthly dollar expenditures on all credit cards—are listed at the left. The two independent variables selected to predict credit usage—family size and family income—are shown on the right. By using canonical correlation analysis, the researcher creates a composite measure of credit usage that consists of both dependent variables, rather than having to compute a separate regression equation for each of the dependent variables. The result of applying canonical correlation is a measure of the strength of the relationship between two sets of multiple variables (canonical variates). The measure of the strength of the relationship between the two variates is expressed as a canonical correlation coefficient (Rc). The researcher now has two results of interest: the canonical variates representing the optimal linear combinations of dependent and independent variables; and the canonical correlation representing the relationship between them.
Analyzing Relationships with Canonical Correlation
Canonical correlation analysis is the most generalized member of the family of multivariate statistical techniques. It is directly related to several dependence methods. Similar to regression, canonical correlation’s goal is to quantify the strength of the relationship, in this case between the two sets of variables (independent and dependent). It corresponds to factor analysis in the creation of composites of variables. It also resembles discriminant analysis in its ability to determine independent dimensions (similar to discriminant functions) for each variable set, in this situation with the objective of producing the maximum correlation between the dimensions. Thus, canonical correlation identifies the optimum structure or dimensionality of each variable set that maximizes the relationship between independent and dependent variable sets.
Canonical correlation analysis deals with the association between composites of sets of multiple dependent and independent variables. In doing so, it develops a number of independent canonical functions that maximize the correlation between the linear composites, also known as canonical variates, which are sets of dependent and independent variables. Each canonical function is actuallybased on the correlation between two canonical variates, one variate for the dependent variables and one for the independent variables. Another unique feature of canonical correlation is that the variates are derived to maximize their correlation. Moreover, canonical correlation does not stop with the derivation of a single relationship between the sets of variables. Instead, a number of canonical functions (pairs of canonical variates) maybe derived.
The following discussion of canonical correlation analysis is organized around a six-stagemodel-building process. The steps in this processinclude (1) specifying the objectives of canonical correlation, (2) developing the analysis plan, (3) assessing the assumptions underlying canonical correlation, (4) estimating the canonical model and assessing overall model fit, (5) interpreting the canonical variates, and (6) validating themodel.
Stage 1: Objectives of Canonical Correlation Analysis
The appropriate data for canonical correlation analysis are two sets of variables. We assume that each set can be given some theoretical meaning, at least to the extent that one set could be defined as the independent variables and the other as the dependent variables. Once this distinction has been made, canonical correlation can address a wide range of objectives. These objects maybe anyor all of the following:
1. Determining whether two sets of variables (measurements made on the same objects) are independent of one another or, conversely, determining the magnitude of the relationships that mayexist between the two sets.
2. Deriving a set of weights for each set of dependent and independent variables so that the linear combinations of each set are maximally correlated. Additional linear functions that maximize the remaining correlation are independent of the preceding set(s) of linear combinations.
3. Explaining the nature of whatever relationships exist between the sets of dependent and independent variables, generally by measuring the relative contribution of each variable to the canonical functions (relationships) that are extracted.
The inherent flexibility of canonical correlation in terms of the number and types of variables handled, both dependent and independent, makes it a logical candidate for manyof the more complex problems addressed with multivariate techniques.
Stage 2: Designing a Canonical Correlation Analysis
As the most general form of multivariate analysis, canonical correlation analysis shares basic implementation issues common to all multivariate techniques. Discussions on the impact of measurement error, the types of variables, and their transformations that can be included are relevant to canonical correlation analysis as well.
The issues of the impact of sample size (both small and large) and the necessity for a sufficient number of observations per variable are frequently encountered with canonical correlation. Researchers are tempted to include many variables in both the independent and dependent variable set, not realizing the implications for sample size. Sample sizes that are very small will not represent the correlations well, thus obscuring any meaningful relationships. Very large samples will have a tendency to indicate statistical significance in all instances, even where practical significance is not indicated. The researcher is also encouraged to maintain at least 10 observations per variable to avoid “overfitting” the data.
The classification of variables as dependent or independent is of little importance for the statistical estimation of the canonical functions, because canonical correlation analysis weights both variates to maximize the correlation and places no particular emphasis on either variate. Yet because the technique produces variates to maximize the correlation between them, a variable in either set relates to all other variables in both sets. This allows the addition or deletion of a single variable to affect the entire solution, particularly the other variate. The composition of each variate, either independent or dependent, becomes critical. A researcher must have conceptually linked sets of the variables before applying canonical correlation analysis.This makes the specification of dependent versus independent variates essential to establishing a strong conceptual foundation for the variables.
Stage 3: Assumptions in Canonical Correlation
The generality of canonical correlation analysis also extends to its underlying statistical assumptions. The assumption of linearity affects two aspects of canonical correlation results. First, the correlation coefficient between any two variables is based on a linear relationship. If the relationship is nonlinear, then one or both variables should be transformed, if possible. Second, the canonical correlation is the linear relationship between the variates. If the variates relate in a nonlinear manner, the relationship will not be captured by canonical correlation. Thus, while canonical correlation analysis is the most generalized multivariate method, it is still constrained to identifying linear relationships.
Canonical correlation analysis can accommodate any metric variable without the strict assumption of normality. Normality is desirable because it standardizes a distribution to allow for a higher correlation among the variables. But in the strictest sense, canonical correlation analysis can accommodate even nonnormal variables if the distributional form (e.g., highly skewed) does not decrease the correlation with other variables. This allows for transformed nonmetric data (in the form of dummy variables) to be used as well. However, multivariate normality is required for the statistical inference test of the significance of each canonical function. Because tests for multivariate normality are not readily available, the prevailing guideline is to ensure that each variable has univariate normality. Thus, although normality is not strictly required, it is highly recommended that all variables be evaluated for normalityand transformed if necessary.
Homoscedasticity, to the extent that it decreases the correlation between variables, should also be remedied. Finally, multicollinearity among either variable set will confound the ability of the technique to isolate the impact of any single variable, making interpretation less reliable.
Stage 4: Deriving the Canonical Functions and Assessing Overall Fit
The first step of canonical correlation analysis is to derive one or more canonical functions. Each function consists of a pair of variates, one representing the independent variables and the other representing the dependent variables. The maximum number of canonical variates (functions) that can be extracted from the sets of variables equals the number of variables in the smallest data set, independent or dependent. For example, when the research problem involves five independent variables and three dependent variables, the maximum number of canonical functions that can be extracted is three.
Deriving Canonical Functions
The derivation of successive canonical variates is similar to the procedure used with unrotated factor analysis. The first factor extracted accounts for the maximum amount of variance in the set of variables, then the second factor is computed so that it accounts for as much as possible of the variance not accounted for by the first factor, and so forth, until all factors have been extracted. Therefore, successive factors are derived from residual or leftover variance from earlier factors. Canonical correlation analysis follows a similar procedure but focuses on accounting for the maximum amount of the relationship between the two sets of variables, rather than within a single set. The result is that the firstpair of canonical variates is derived so as to have the highest intercorrelation possible between the two sets of variables. The second pair of canonical variates is then derived so that it exhibits the maximum relationship between the two sets of variables (variates) not accounted for by the first pair of variates. In short, successive pairs of canonical variates are based on residual variance, and their respective canonical correlations (which reflect the interrelationships between the variates) become smaller as each additional function is extracted. That is, the first pair of canonical variates exhibits the highest intercorrelation, the next pair the second-highest correlation, and so forth.
One additional point about the derivation of canonical variates: as noted, successive pairs of canonical variates are based on residual variance. Therefore, each of the pairs of variates is orthogonal and independent of all other variates derived from the same set of data.
The strength of the relationship between the pairs of variates is reflected by the canonical correlation. When squared, the canonical correlation represents the amount of variance in one canonical variate accounted for by the other canonical variate. This also may be called the amount of shared variance between the two canonical variates. Squared canonical correlations are calledcanonical roots or eigenvalues.
Which Canonical Functions Should Be Interpreted?
As with research using other statistical techniques, the most common practice is to analyze functions whose canonical correlation coefficients are statistically significant beyond some level, typically .05 or above. If other independent functions are deemed insignificant, these relationships among the variables are not interpreted. Interpretation of the canonical variates in a significant function is based on the premise that variables in each set that contribute heavily to shared variances for these functions are considered to be related to each other.
The authors believe that the use of a single criterion such as the level of significance is too superficial. Instead, they recommend that three criteria be used in conjunction with one another to decide which canonical functions should be interpreted. The three criteria are (1) level of statistical significance of the function, (2) magnitude of the canonical correlation, and (3) redundancy measure for the percentage of variance accounted for from the two data sets
Level of Significance
The level of significance of a canonical correlation generally considered to be the minimum acceptable for interpretation is the .05 level, which (along with the .01 level) has become the generally accepted level for considering a correlation coefficient statistically significant. This consensus has developed largely because of the availability of tables for these levels. These levels are not necessarily required in all situations, however, and researchers from various disciplines frequently must rely on results based on lower levels of significance. The most widely used test, and the one normally provided by computer packages, is the F statistic, based on Rao’s approximation [3].
In addition to separate tests of each canonical function, a multivariate test of all canonical roots can also be used for evaluating the significance of canonical roots. Many of the measures for assessing the significance of discriminant functions, including Wilks’ lambda, Hotelling’s trace, Pillai’s trace, and Roy’s gcr, are also provided.
Magnitude of the Canonical Relationships
The practical significance of the canonical functions, represented by the size of the canonical correlations, also should be considered when deciding which functions to interpret. No generally accepted guidelines have been established regarding suitable sizes for canonical correlations. Rather, the decision is usually based on the contribution of the findings to better understanding of the research problem being studied. It seems logical that the guidelines suggested for significant factor loadingsin factor analysis might be useful with canonical correlations, particularly when one considers that canonical correlations refer to the variance explained in the canonical variates (linear composites), not the original variables.
Redundancy Measure of Shared Variance
Recall that squared canonical correlations (roots) provide an estimate of the shared variance between the canonical variates. Although this is a simple and appealing measure of the shared variance, it may lead to some misinterpretation because the squared canonical correlations represent the variance shared by the linear composites of the sets of dependent and independent variables, and not the variance extracted from the sets of variables [1]. Thus, a relatively strong canonical correlation may be obtained between two linear composites (canonical variates), even though these linear composites may not extract significant portions of variance from their respective sets of variables.
Because canonical correlations may be obtained that are considerably larger than previously reported bivariate and multiple correlation coefficients, there may be a temptation to assume that canonical analysis has uncovered substantial relationships of conceptual and practical significance. Before such conclusions are warranted, however, further analysis involving measures other than canonical correlations must be undertaken to determine the amount of the dependent variable variance accounted for or shared with the independent variables [7].
To overcome the inherent bias and uncertainty in using canonical roots (squared canonical correlations) as a measure of shared variance, a redundancy index has been proposed [8]. It is the equivalent of computing the squared multiple correlation coefficient between the total independent variable set and each variable in the dependent variable set, and then averaging these squared coefficients to arrive at an average R2. This index provides a summary measure of the ability of a set of independent variables (taken as a set) to explain variation in the dependent variables (taken one at a time). As such, the redundancy measure is perfectly analogous to multiple regression’s R2 statistic, and its value as an index is similar.
The Stewart-Love index of redundancy calculates the amount of variance in one set of variables that can be explained bythe variance in the other set. This index serves as a measure of accounted-for variance, similar to the R2 calculation used in multiple regression. The R2 represents the amount of variance in the dependent variable explained by the regression function of the independent variables. In regression, the total variance in the dependent variable is equal to 1, or 100 percent. Remember that canonical correlation is different from multiple regression in that it does not deal with a single dependent variable but has a composite of the dependent variables, and this composite has only a portion of each dependent variable’s total variance. For this reason, we cannot assume that 100 percent of the variance in the dependent variable set is available to be explained bythe independent variable set. The set of independent variables can be expected to account only for the shared variance in the dependent canonical variate. For this reason, the calculation of the redundancy index is a threestep process. The first step involves calculating the amount of shared variance from the set of dependent variables included in the dependent canonical variate. The second step involves calculating the amount of variance in the dependent canonical variate that can be explained by the independent canonical variate. The final step is to calculate the redundancyindex, found bymultiplying these two components.
Step 1: The Amount of Shared Variance. To calculate the amount of shared variance in the dependent variable set included in the dependent canonical variate, let us first consider how the regression R2 statistic is calculated. R2 is simply the square of the correlation coefficient R, which represents the correlation between the actual dependent variable and the predicted value. In the canonical case, we are concerned with correlation between the dependent canonical variate and each of the dependent variables. Such information can be obtained from the canonical loadings (L1), which represent the correlation between each input variable and its own canonical variate (discussed in more detail in the following section). By squaring each of the dependent variable loadings (Li2), one may obtain a measure of the amount of variation in each of the dependent variables explained by the dependent canonical variate. To calculate the amount of shared variance explained by the canonical variate, a simple average of the squared loadings is used.
Step 2: The Amount of Explained Variance. The second step of the redundancy process involves the percentage of variance in the dependent canonical variate that can be explained by the independent canonical variate. This is simply the squared correlation between the independent canonical variate and the dependent canonical variate, which is otherwise known as the canonical correlation. The squared canonical correlation is commonlycalled the canonical R2.
Step 3: The Redundancy Index. The redundancy index of a variate is then derived by multiplying the two components (shared variance of the variate multiplied by the squared canonical correlation) to find the amount of shared variance that can be explained by each canonical function. To have a high redundancy index, one must have a high canonical correlation and a high degree of shared variance explained by the dependent variate. A high canonical correlation alone does not ensure a valuable canonical function. Redundancy indices are calculated for both the dependent and the independent variates, although in most instances the researcher is concerned only with the variance extracted from the dependent variable set, which provides a much more realistic measure of the predictive abilityof canonical relationships. The researcher should note that while the canonical correlation is the same for both variates in the canonical function, the redundancy index will most likely vary between the two variates, as each will have a differing amount of shared variance.
What is the minimum acceptable redundancy index needed to justify the interpretation of canonical functions? Just as with canonical correlations, no generally accepted guidelines have been established. The researcher must judge each canonical function in light of its theoretical and practical significance to the research problem being investigated to determine whether the redundancy index is sufficient to justify interpretation. A test for the significance of the redundancy index has been developed [2], although it has not been widelyutilized.
|
556 videos|198 docs
|



CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,MCQs
,video lectures
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,GATE
,past year papers
,CSIR NET
,Canonical correlation - 1
,UGC NET
,UGC NET
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Extra Questions
,Sample Paper
,shortcuts and tricks
,UGC NET
,Objective type Questions
,CSIR NET
,Summary
,CSIR NET
,Canonical correlation - 1
,Free
,Viva Questions
,Canonical correlation - 1
,study material
,Important questions
,GATE
,practice quizzes
,ppt
,Previous Year Questions with Solutions
,GATE
,mock tests for examination
,Exam
,Semester Notes
;






Canonical correlation - 1, CSIR-NET Mathematical Sciences Free PDF Download
Importance of Canonical correlation - 1, CSIR-NET Mathematical Sciences
Canonical correlation - 1, CSIR-NET Mathematical Sciences Notes
Canonical correlation - 1, CSIR-NET Mathematical Sciences Mathematics Questions
Study Canonical correlation - 1, CSIR-NET Mathematical Sciences on the App
|
© EduRev
|
Education Revolution
|



|





