Central Limit Theorem : Example 2 - Mathematical Methods of Physics, UGC - NET Physics | Physics for IIT JAM, UGC - NET, CSIR NET PDF Download
Now that we have an intuitive feel for the Central Limit Theorem, let's use it in two different examples. In the first example, we use the Central Limit Theorem to describe how the sample mean behaves, and then use that behavior to calculate a probability. In the second example, we take a look at the most common use of the CLT, namely to use the theorem to test a claim.
Example
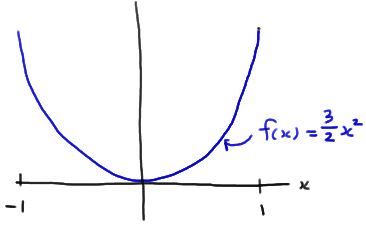
Take a random sample of size n = 15 from a distribution whose probability density function is:
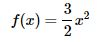
for −1 < x < 1. What is the probability that the sample mean falls between −2/5 and 1/5?
Solution. The expected value of the random variable X is 0, as the following calculation illustrates:
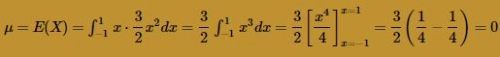
The variance of the random variable X is 3/5, as the following calculation illustrates:
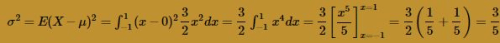
Therefore, the CLT tells us that the sample mean 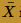 is approximately normal with mean:
is approximately normal with mean:
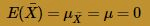
and variance:
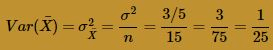
Therefore the standard deviation of is 1/5. Drawing a picture of the desired probability:
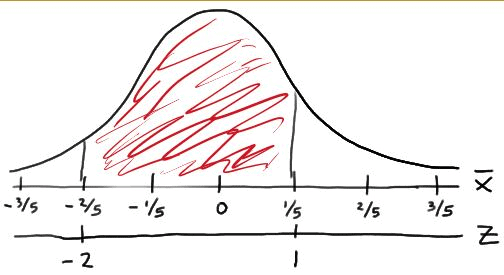
we see that:
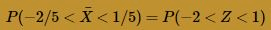
Therefore, using the standard normal table, we get:

That is, there is an 81.85% chance that a random sample of size 15 from the given distribution will yield a sample mean between −2/5 and 1/5.
Example
Let Xi denote the wating time (in minutes) for the ith customer. An assistant manager claims that μ, the average waiting time of the entire population of customers, is 2 minutes. The manager doesn't believe his assistant's claim, so he observes a random sample of 36 customers. The average waiting time for the 36 customers is 3.2 minutes. Should the manager reject his assistant's claim (... and fire him)?

Solution. It is reasonable to assume that Xi is an exponential random variable. And, based on the assistant manager's claim, the mean of Xi is:
μ = θ = 2.
Therefore, knowing what we know about exponential random variables, the variance of Xi is:
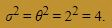
Now, we need to know, if the mean μ really is 2, as the assistant manager claims, what is the probability that the manager would obtain a sample mean as large as (or larger than) 3.2 minutes? Well, the Central Limit Theorem tells us that the sample mean is approximately normally distributed with mean:
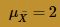
and variance:
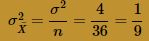
Here's a picture, then, of the normal probability that we need to determine:
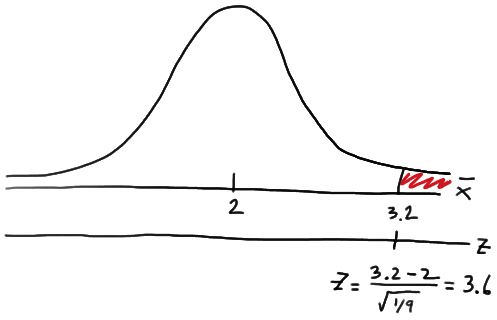
That is:
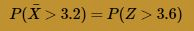
The Z value in this case is so extreme that the table in the back of our text book can't help us find the desired probability. But, using statistical software, such as Minitab, we can determine that:
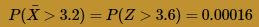
That is, if the population mean μ really is 2, then there is only a 16/100,000 chance (0.016%) of getting such a large sample mean. It would be quite reasonable, therefore, for the manager to reject his assistant's claim that the mean μ is 2. The manager should feel comfortable concluding that the population mean μ really is greater than 2. We will leave it up to him to decide whether or not he should fire his assistant!
By the way, this is the kind of example that we'll see when we study hypothesis testing in Stat 415. In general, in the process of performing a hypothesis test, someone makes a claim (the assistant, in this case), and someone collects and uses the data (the manager, in this case) to make a decision about the validity of the claim. It just so happens to be that we used the CLT in this example to help us make a decision about the assistant's claim.
FAQs on Central Limit Theorem : Example 2 - Mathematical Methods of Physics, UGC - NET Physics - Physics for IIT JAM, UGC - NET, CSIR NET
| 1. What is the Central Limit Theorem? |  |
| 2. How does the Central Limit Theorem apply to mathematical methods in physics? | |
| 3. Can you provide an example of how the Central Limit Theorem is used in physics? | |
| 4. What are the key assumptions of the Central Limit Theorem? | |
| 5. How does the Central Limit Theorem benefit UGC - NET Physics exam preparation? | |

|
4.65/5 Rating |

|
Dec 26, 2024 Last updated |

|
Explore Courses for Physics exam
|
|
CSIR NET
,Important questions
,UGC - NET
,ppt
,UGC - NET
,UGC - NET Physics | Physics for IIT JAM
,Semester Notes
,Sample Paper
,Viva Questions
,Central Limit Theorem : Example 2 - Mathematical Methods of Physics
,Central Limit Theorem : Example 2 - Mathematical Methods of Physics
,CSIR NET
,UGC - NET
,CSIR NET
,Objective type Questions
,shortcuts and tricks
,practice quizzes
,MCQs
,UGC - NET Physics | Physics for IIT JAM
,video lectures
,study material
,Exam
,UGC - NET Physics | Physics for IIT JAM
,Free
,Central Limit Theorem : Example 2 - Mathematical Methods of Physics
,past year papers
,Previous Year Questions with Solutions
,Extra Questions
,Summary
,mock tests for examination
;






Central Limit Theorem : Example 2 - Mathematical Methods of Physics, UGC - NET Physics Free PDF Download
Importance of Central Limit Theorem : Example 2 - Mathematical Methods of Physics, UGC - NET Physics
Central Limit Theorem : Example 2 - Mathematical Methods of Physics, UGC - NET Physics Notes
Central Limit Theorem : Example 2 - Mathematical Methods of Physics, UGC - NET Physics Physics Questions
Study Central Limit Theorem : Example 2 - Mathematical Methods of Physics, UGC - NET Physics on the App
|
© EduRev
|
Education Revolution
|



|




