Classification of Data | Statistics for SSC CGL PDF Download
| Table of contents |
|
| Classification of Data |
|
| Objectives of Classification of Data |
|
| Characteristics of a Good Classification |
|
| Important Points on Classification of Data |
|
Data is not always neatly organized. An analyst or investigator must arrange the gathered data properly for better analysis and achieving desired outcomes. One crucial method for organizing such data is data classification. Through this approach, raw data is transformed into various statistical series to yield more valuable and insightful results.
Classification of Data
To perform statistical analysis, various types of data are collected by the investigator or analyst. Initially, the data is in raw form, making it difficult to analyze. To make the analysis meaningful and easier, the raw data is organized or classified into different categories based on their characteristics. This process is known as the Classification of Data, where similar or homogeneous characteristics are grouped together into different categories or classes. Each of these categories is referred to as a Class. The primary bases for classifying statistical information include Geographical, Chronological, Qualitative (both Simple and Manifold), and Quantitative or Numerical.For instance, if an investigator wants to assess the poverty level in a state, they can gather information about the state's residents and then classify it based on factors such as income and education.
Objectives of Classification of Data
- Brief and Simple: Raw data collected needs to be organized into different groups for better understanding. Classifying data helps present information clearly and concisely, making analysis easier.
- Utility: Analysts gather information from various sources and categorize it to highlight similarities, improving its usefulness for investigation.
- Distinctiveness: Sorting data into categories makes differences more obvious, aiding in drawing distinct conclusions from heterogeneous data.
- Comparability: Data classification enables comparison between datasets, simplifying the process of estimating and analyzing information.
- Scientific Arrangement: Organizing data based on common attributes facilitates a logical and reliable arrangement, enhancing the data's credibility.
- Attractive and Effective: Well-classified data not only enhances effectiveness but also makes information visually appealing and easy to comprehend at a glance.
Characteristics of a Good Classification

- Comprehensiveness: To achieve better outcomes, it's crucial to organize the gathered raw data in a thorough manner. This involves placing each piece of data into a specific class, category, or group, ensuring nothing is overlooked.
- Clarity: The individual collecting and assessing data should categorize the raw information into distinct groups with clarity. Ensuring clear allocation of items into different categories prevents any confusion for the reader or investigator.
- Homogeneity: For effective investigation results, it's important to group the collected raw data into homogeneous categories. Classifying data based on similar attributes facilitates easier and more accurate data analysis.
- Suitability: For data classification to be useful, it should align with the investigation's objectives. For instance, when determining a country's literacy rate, classifying data based on income and expenditure is irrelevant. The data should be categorized as educated and uneducated.
- Stability: Consistency in how data is classified is essential. This means the criteria for data classification should remain constant across investigations. Each type of investigation should use the same classification criteria.
- Elastic: Data classification should be flexible. This flexibility allows for adjustments to the classification if the purpose or focus of the investigation changes. Investigators should be able to modify the classification as needed.
Bases of Classification of Data
Classification of data is the process of arranging data in an orderly manner. Now let us learn the types of data classification in statistics. The four important bases of classification are discussed below:

Geographical Classification of data
- The grouping of information based on where it comes from is known as geographical data classification.
- Simply put, geographical data classification involves organizing information by geographical location or area.
- For example, if we classify data on the production of sugarcane, pulses, or cotton based on four main regions in India, it falls under geographical data classification.
Region | Production of Pulses (in kg.) |
Eastern Region | 2837 |
Western Region | 968 |
Southern Region | 2149 |
Northern Region | 1746 |
It is also recognized as ‘spatial classification of data’.
Chronological Classification of data
In the organization of data according to time, information is grouped based on when it happened, like years, months, weeks, and days. This sorting arranges data in either increasing or decreasing order concerning time units like years, quarters, months, weeks, and days. This kind of data arrangement is also called temporal classification of data.Year | No of Students in a School |
2015 | 1270 |
2017 | 1890 |
2019 | 1750 |
2020 | 1530 |
Qualitative Classification of data
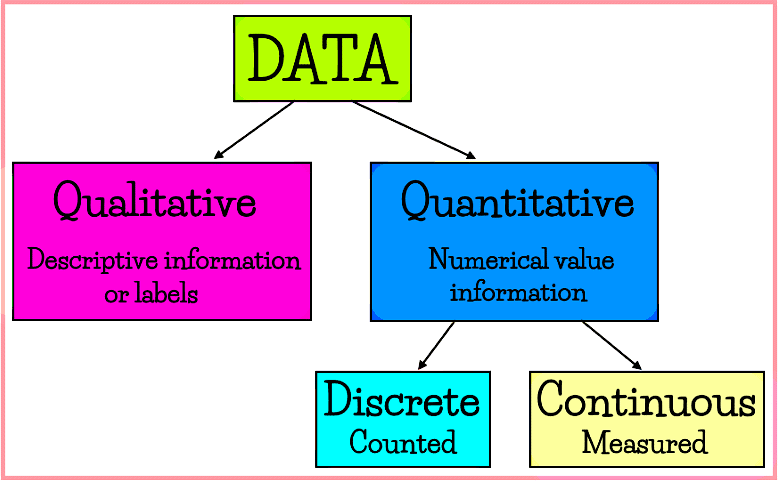
- Classification of information based on qualities and features is called qualitative data classification.
- In this type of grouping, data is categorized by specific attributes like gender, honesty, hair color, literacy, intelligence, religion, etc.
- When using qualitative data classification in statistics, the attribute being studied is not measurable; it can only be identified as present or absent.
- Qualitative data is usually split into two main categories:
- Data is organized based on characteristics.
- Examples of attributes include gender, honesty, hair color, literacy, intelligence, and religion.
- Attributes cannot be measured directly.
Qualitative data has two primary types.
- Simple classification of data
- Manifold classification of data
Simple Classification of data
- Objective: In this kind of sorting of information, we split data into two exact groups. For instance, if we are looking at students based on one feature, like their level of education, we can divide them into two categories: educated and uneducated. Similarly, they can also be categorized into basic education or higher education.
- Method: This method of sorting where we create two distinct groups is known as simple or twofold or dichotomous data classification. Here, we form two groups, one with the specified feature and the other without it.
Manifold Classification of data
- Apart from creating only two groups, if we further split the information based on additional characteristics within those groups, it becomes known as manifold classification. This means that after sorting data into two groups based on one characteristic, each of those groups is then divided into two more based on another characteristic. This can result in multiple levels of data classification with more than just two categories.
- For instance, we can classify the student population into males and females. Then, these groups can be further divided into educated and uneducated individuals, which can then be categorized into basic education and higher education levels.
Quantitative Classification of data
- Quantitative classification of data deals with numbers that can be measured or calculated, unlike qualitative classification. It allows data to be sorted into numerical categories.
- A quantitative variable gives information on a numerical scale and can be measured or operated on. Examples include weight, temperature, volume, height, income, student grades, and numerical values.
- In statistics, data is categorized based on different ranges of values, showing how things change over time or across various areas. Quantitative classification is also known as classification by variables. There are two types of quantitative data: discrete and continuous.
- Discrete quantitative data includes variables that can be counted and have a specific, finite value.
- Continuous quantitative data encompasses values that can be measured and can vary across a range.
Discrete quantitative data example:
- The number of students in a class.
- The total data stored on a USB drive.
Continuous quantitative data example:
- The temperature each day in summer.
- The weight of each passenger on a train.
Important Points on Classification of Data
- Classification of Data: Data is sorted into types, and we study them one by one. Understanding classification in statistics is crucial.
- Variable: Variable means something that changes. It can differ from person to person, time to time, or place to place. There are two main types: discrete and continuous variables.
- Frequency and Frequency Distribution: Frequency shows how often each variable appears. Frequency distribution involves analyzing data based on measurable variables like rates, weight, or payments.
- Table: A structured way of organizing statistical data with columns and rows. Rows are horizontal, while columns are vertical.
- Types of Data Classification:
- One-way Classification: Sorting data based on a single characteristic.
- Two-way Classification: Sorting data based on two characteristics simultaneously.
- Multi-way Classification: Sorting data based on more than two characteristics at once.
- Levels of Measurement: There are four levels of statistical data measurement: nominal, ordinal, interval, and ratio, ranging from the least to the most precise.
|
72 videos|87 docs|18 tests
|
FAQs on Classification of Data - Statistics for SSC CGL
| 1. What are the objectives of classification of data? |  |
| 2. What are the characteristics of a good classification system? | |
| 3. What are some important points to consider in the classification of data? | |
| 4. How can classification of data benefit organizations in decision-making? | |
| 5. How does the classification of data contribute to data security? | |

|
4.71/5 Rating |

|
Dec 26, 2024 Last updated |

|
Explore Courses for SSC CGL exam
|
|
Semester Notes
,shortcuts and tricks
,Previous Year Questions with Solutions
,Exam
,Important questions
,Classification of Data | Statistics for SSC CGL
,Sample Paper
,Classification of Data | Statistics for SSC CGL
,past year papers
,study material
,Viva Questions
,Summary
,video lectures
,Free
,Extra Questions
,Objective type Questions
,Classification of Data | Statistics for SSC CGL
,ppt
,MCQs
,practice quizzes
,mock tests for examination
;






Classification of Data Free PDF Download
Importance of Classification of Data
Classification of Data Notes
Classification of Data SSC CGL Questions
Study Classification of Data on the App
|
© EduRev
|
Education Revolution
|



|




