Context-Free Grammars: Definition & Parsing | Compiler Design - Computer Science Engineering (CSE) PDF Download

1. Context-free Grammars:
Definition: Formally, a context-free grammar G is a 4-tuple G = (V, T, P, S), where:
1. V is a finite set of variables (or nonterminals). These describe sets of “related” strings.
2. T is a finite set of terminals (i.e., tokens).
3. P is a finite set of productions, each of the form
A where A V is a variable, and (V T)* is a sequence of terminals and nonterminals. S V is the start symbol.
Example of CFG: E ==>EAE | (E) | -E | id A==> + | - | * | / |
Where E, A are the non-terminals while id, +, *, -, /,(, ) are the terminals. 2. Syntax analysis:
In syntax analysis phase the source program is analyzed to check whether if conforms to the source language’s syntax, and to determine its phase structure. This phase is often separated into two phases:
- Lexical analysis: which produces a stream of tokens?
- Parser: which determines the phrase structure of the program based on the context-free grammar for the language?
2.1 PARSING: Parsing is the activity of checking whether a string of symbols is in the language of some grammar, where this string is usually the stream of tokens produced by the lexical analyzer. If the string is in the grammar, we want a parse tree, and if it is not, we hope for some kind of error message explaining why not.
There are two main kinds of parsers in use, named for the way they build the parse trees:
- Top-down: A top-down parser attempts to construct a tree from the root, applying productions forward to expand non-terminals into strings of symbols.
- Bottom-up: A Bottom-up parser builds the tree starting with the leaves, using productions in reverse to identify strings of symbols that can be grouped together.
In both cases the construction of derivation is directed by scanning the input sequence from left to right, one symbol at a time.
Parse Tree:

A parse tree is the graphical representation of the structure of a sentence according to its grammar.
Example:
Let the production P is:
E T | E+T
T F | T*F
F V | (E)
V a | b | c |d
The parse tree may be viewed as a representation for a derivation that filters out the choice regarding the order of replacement.
Parse tree for a * b + c
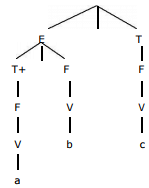
Parse tree for a + b * c is:
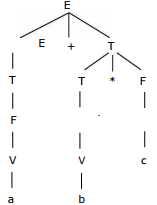
Parse tree for (a * b) * (c + d)
|
26 videos|90 docs|30 tests
|
FAQs on Context-Free Grammars: Definition & Parsing - Compiler Design - Computer Science Engineering (CSE)
| 1. What is a context-free grammar? |  |
| 2. What is parsing in computer science? | |
| 3. How does parsing relate to context-free grammars? | |
| 4. What are some applications of context-free grammars and parsing? | |
| 5. Can a context-free grammar describe all possible languages? | |



Sample Paper
,Important questions
,Extra Questions
,Context-Free Grammars: Definition & Parsing | Compiler Design - Computer Science Engineering (CSE)
,MCQs
,Context-Free Grammars: Definition & Parsing | Compiler Design - Computer Science Engineering (CSE)
,study material
,Viva Questions
,Summary
,practice quizzes
,past year papers
,Objective type Questions
,video lectures
,ppt
,mock tests for examination
,Previous Year Questions with Solutions
,Context-Free Grammars: Definition & Parsing | Compiler Design - Computer Science Engineering (CSE)
,shortcuts and tricks
,Exam
,Free
,Semester Notes
;






Context-Free Grammars: Definition & Parsing Free PDF Download
Importance of Context-Free Grammars: Definition & Parsing
Context-Free Grammars: Definition & Parsing Notes
Context-Free Grammars: Definition & Parsing Computer Science Engineering (CSE) Questions
Study Context-Free Grammars: Definition & Parsing on the App
|
© EduRev
|
Education Revolution
|



|





