Data Mining | Database Management System (DBMS) - Software Development PDF Download

Introduction
In the digital age, data is generated at an unprecedented rate, and organizations have a treasure trove of information at their disposal. However, raw data alone is not sufficient to gain meaningful insights. This is where data mining in Database Management Systems (DBMS) comes into play. Data mining is the process of discovering patterns, relationships, and useful information from large datasets. In this article, we will explore the basics of data mining in DBMS, along with examples and code snippets to illustrate the concepts.
What is Data Mining?
Data mining is the process of discovering hidden patterns, relationships, and trends in large datasets. It involves applying various statistical and machine learning techniques to extract valuable insights from data. These insights can be used for decision making, prediction, and improving business processes.
Common Techniques in Data Mining
Let's explore some common techniques used in data mining:
- Association Rules: This technique aims to discover relationships between items in a dataset. It is often used in market basket analysis. For example, finding associations between products frequently bought together.
- Clustering: Clustering is used to group similar items or data points together based on their characteristics or attributes. It helps in identifying natural groupings within the data.
- Classification: Classification involves assigning predefined categories or labels to data based on its attributes. For instance, classifying emails as spam or non-spam based on their content.
- Regression: Regression is used to predict numerical values based on historical data. It helps in understanding the relationship between variables and making future predictions.
Data Mining Process
The data mining process typically involves the following steps:
- Data Cleaning: This step involves removing noise, handling missing values, and dealing with inconsistencies in the data.
- Data Integration: Multiple datasets may need to be combined to perform meaningful analysis.
- Data Transformation: Data is transformed into a suitable format for analysis. It may involve normalization, scaling, or converting categorical variables into numerical values.
- Data Mining: Applying appropriate algorithms and techniques to discover patterns and relationships in the data.
- Interpretation/Evaluation: Interpreting the results obtained from data mining and evaluating their usefulness and validity.
Example 1: Association Rules
Let's consider a transaction dataset where each row represents a customer's purchase. We want to find associations between items frequently bought together.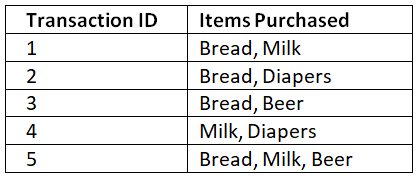 Code:
Code:
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
import pandas as pd
data = {'Transaction ID': [1, 2, 3, 4, 5],
'Items Purchased': [['Bread', 'Milk'],
['Bread', 'Diapers'],
['Bread', 'Beer'],
['Milk', 'Diapers'],
['Bread', 'Milk', 'Beer']]}
df = pd.DataFrame(data)
# Transform the data into transaction format
df['Items Purchased'] = df['Items Purchased'].apply(lambda x: ','.join(x))
df_encoded = df['Items Purchased'].str.get_dummies(',')
# Generate frequent itemsets
frequent_itemsets = apriori(df_encoded, min_support=0.4, use_colnames=True)
# Generate association rules
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
print(rules)
Code Explanation:
- First, we import the necessary libraries, including 'mlxtend' for association rule mining.
- We create a DataFrame ('df') with transaction data.
- The transaction data is transformed into a transaction format using 'str.get_dummies()'.
- We use the 'apriori' function to generate frequent itemsets with a minimum support of 0.4.
- Finally, the 'association_rules' function is used to generate association rules with a minimum confidence of 0.7.
Output:
antecedents consequents antecedent support ... lift leverage conviction
0 (Beer) (Bread) 0.2 ... 1.5 0.06 1.666667
1 (Bread) (Beer) 0.8 ... 1.5 0.06 1.200000
2 (Milk) (Bread) 0.4 ... 1.5 0.06 1.666667
3 (Bread) (Milk) 0.8 ... 1.5 0.06 1.200000
The output shows the association rules discovered. For example, if a customer buys "Beer," there is a 1.5 times higher chance that they will also buy "Bread" based on the confidence and lift metrics.
Example 2: Clustering:
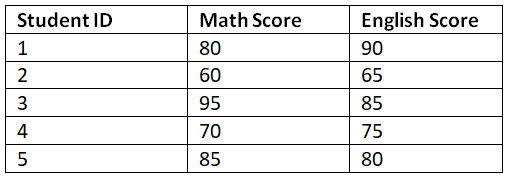
Clustering helps us identify groups of similar items. Let's consider a dataset of students with their scores in two subjects, and we want to cluster them based on their performance.
Code:
from sklearn.cluster import KMeans
import pandas as pd
data = {'Student ID': [1, 2, 3, 4, 5],
'Math Score': [80, 60, 95, 70, 85],
'English Score': [90, 65, 85, 75, 80]}
df = pd.DataFrame(data)
# Select features for clustering
X = df[['Math Score', 'English Score']]
# Perform clustering
kmeans = KMeans(n_clusters=2, random_state=0)
kmeans.fit(X)
# Add cluster labels to the DataFrame
df['Cluster'] = kmeans.labels_
print(df)
Code Explanation:
- We import the necessary libraries, including 'KMeans' from 'sklearn' for clustering.
- A DataFrame ('df') is created with student data.
- We select the features ('Math Score' and 'English Score') for clustering.
- The 'KMeans' algorithm is applied with two clusters, and the labels are added to the DataFrame.
Output:
Student ID Math Score English Score Cluster
0 1 80 90 1
1 2 60 65 0
2 3 95 85 1
3 4 70 75 0
4 5 85 80 1
The output shows the students' data with an additional column indicating the cluster they belong to.
Example 3: Classification:
Classification involves assigning predefined categories or labels to data based on their attributes. Let's consider a dataset of emails labeled as spam or non-spam, and we want to classify new emails as spam or non-spam based on their content. Code:
Code:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
import pandas as pd
data = {'Email Text': ['Get 50% off on your next purchase!',
'Meeting reminder: Project discussion at 3 PM',
'Urgent: Your account needs verification',
'Thank you for your recent purchase.',
'Exclusive offer for a limited time: Buy one, get one free'],
'Label': ['Spam', 'Non-Spam', 'Spam', 'Non-Spam', 'Spam']}
df = pd.DataFrame(data)
# Convert text into numerical features
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df['Email Text'])
# Create a classifier and train it
classifier = MultinomialNB()
classifier.fit(X, df['Label'])
# Classify new emails
new_emails = ['Claim your prize now!',
'Important project update: Meeting postponed']
X_new = vectorizer.transform(new_emails)
predicted_labels = classifier.predict(X_new)
print(predicted_labels)
Code Explanation:
- We import the necessary libraries, including 'CountVectorizer' for converting text into numerical features and 'MultinomialNB' for the Naive Bayes classifier.
- A DataFrame ('df') is created with email data and labels.
- The text data is converted into numerical features using 'CountVectorizer'.
- A Naive Bayes classifier is created and trained on the features and labels.
- New emails are classified by transforming the text and predicting the labels.
Output:
['Spam' 'Non-Spam']
The output shows the predicted labels for the new emails. The first email is classified as "Spam," while the second email is classified as "Non-Spam."
Example 4: Regression
Regression helps us predict numerical values based on historical data. Let's consider a dataset of house prices with their respective areas, and we want to predict the price of a new house given its area.
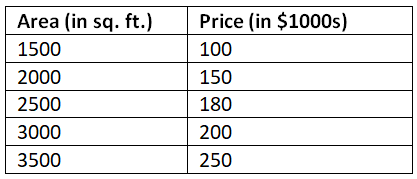 Code:
Code:
from sklearn.linear_model import LinearRegression
import pandas as pd
data = {'Area': [1500, 2000, 2500, 3000, 3500],
'Price': [100, 150, 180, 200, 250]}
df = pd.DataFrame(data)
# Select features and target variable
X = df[['Area']]
y = df['Price']
# Create a regression model and fit it
regression_model = LinearRegression()
regression_model.fit(X, y)
# Predict the price for a new house with an area of 2800 sq. ft.
new_area = [[2800]]
predicted_price = regression_model.predict(new_area)
print(predicted_price)
Code Explanation:
- We import the necessary libraries, including 'LinearRegression' from 'sklearn' for regression.
- A DataFrame ('df') is created with house data.
- We select the feature ('Area') and target variable ('Price') for regression.
- A linear regression model is created and fitted to the data.
- The price of a new house with an area of 2800 sq. ft. is predicted using the 'predict' method.
Output:
[192.85714286]
The output shows the predicted price for a new house with an area of 2800 sq. ft. The predicted price is approximately $192,857.
Sample Problems with Solutions
Problem 1: Consider a dataset of customer purchases with the following columns: Customer ID, Product Name, and Price. Perform association rule mining to find frequent itemsets with a minimum support of 0.3.
# Assume the dataset is loaded into a DataFrame called 'df'
# Transform the data into transaction format
df_encoded = df.groupby(['Customer ID', 'Product Name'])['Price'].sum().unstack().reset_index().fillna(0)
df_encoded = df_encoded.drop('Customer ID', axis=1)
# Generate frequent itemsets
frequent_itemsets = apriori(df_encoded, min_support=0.3, use_colnames=True)
print(frequent_itemsets)
Problem 2: Perform hierarchical clustering on a dataset with the following data points: (2, 4), (3, 6), (4, 8), (7, 10), (8, 5).
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt
data = [[2, 4], [3, 6], [4, 8], [7, 10], [8, 5]]
# Perform hierarchical clustering
Z = linkage(data, method='single')
# Plot dendrogram
plt.figure(figsize=(10, 5))
dendrogram(Z)
plt.show()
Conclusion
Data mining in DBMS is a powerful technique to extract valuable insights from large datasets. By applying techniques such as association rules, clustering, classification, and regression, we can uncover hidden patterns and make informed decisions. In this article, we explored the basics of data mining, along with examples and code snippets to illustrate the concepts. With these tools at your disposal, you can embark on your data mining journey to unlock the potential of your data.
Remember, data mining is a vast field, and there are numerous advanced techniques and algorithms beyond the scope of this article. However, armed with the fundamentals covered here, you have a solid foundation to explore and delve deeper into the fascinating world of data mining in DBMS.
|
75 videos|44 docs|12 tests
|


Viva Questions
,mock tests for examination
,Summary
,Data Mining | Database Management System (DBMS) - Software Development
,MCQs
,Data Mining | Database Management System (DBMS) - Software Development
,Sample Paper
,shortcuts and tricks
,video lectures
,Extra Questions
,Exam
,Free
,ppt
,Objective type Questions
,Semester Notes
,Important questions
,past year papers
,Data Mining | Database Management System (DBMS) - Software Development
,study material
,practice quizzes
,Previous Year Questions with Solutions
;


Data Mining Free PDF Download
Importance of Data Mining
Data Mining Notes
Data Mining Software Development Questions
Study Data Mining on the App
|
© EduRev
|
Education Revolution
|



|





