Distribution of quadratic forms, CSIR-NET Mathematical Sciences | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

2.1 Quadratic Forms
For a k × k symmetric matrix A = {aij} the quadratic function of k variables x = (x1,...,xn)' defined by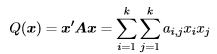
is called the quadratic form with matrix A. If A is not symmetric, we can have an equivalent expression/quadratic form replacing A by (A + A')/2.
Definition 1. Q(x) and the matrix A are called positive definite if
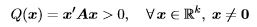
and positive semi-definite if
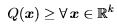
For negative definite and negative semi-definite, replace the > and ≥ in the above definitions by < and ≤, respectively
Theorem 1. A symmetric matrix A is positive definite if and only if it has a Cholesky decomposition A = R'R with strictly positive diagonal elements in R, so that R−1 exists. (In practice this means that none of the diagonal elements of R are very close to zero.)
Proof. The “if” part is proven by construction. The Cholesky decomposition, R, is constructed a row at a time and the diagonal elements are evaluated as the square roots of expressions calculated from the current row of A and previous rows of R. If the expression whose square root is to be calculated is not positive then you can determine a non-zero x ∈Rk for which x'Ax ≤ 0.
Suppose that A = R'R with R invertible. Then
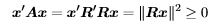
with equality only if Rx = 0. But if R−1 exists then x = R−10 must also be zero.
Transformation of Quadratic Forms:
Theorem 2. Suppose that B is a k × k nonsingular matrix. Then the quadratic form Q∗(y) = y'B'ABy is positive definite if and only if Q(x) = x'Ax is positive definite. Similar results hold for positive semi-definite, negative definite and negative semi-definite.
Proof.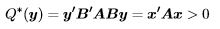
where x = By ≠ 0 because y ≠ 0 and B is nonsingular.
Theorem 3. For any k×k symmetric matrix A the quadratic form defined by A can be written using its spectral decomposition as
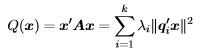
where the eigendecomposition of of A is Q'ΛQ with Λ diagonal with diagonal elements λi, i = 1,...,k, Q is the orthogonal matrix with the eigenvectors, qi, i = 1,...,k as its columns. (Be careful to distinguish the bold face Q, which is a matrix, from the unbolded Q(x), which is the quadratic form.) Proof. For any 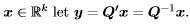 Then
Then
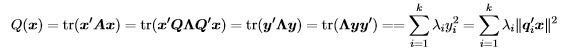
This proof uses a common “trick” of expressing the scalar Q(x) as the trace of a 1×1 matrix so we can reverse the order of some matrix multiplications.
Corollary 1. A symmetric matrix A is positive definite if and only if its eigenvalues are all positive, negative definite if and only if its eignevalues are all negative, and positive semi-definite if all its eigenvalues are non-negative.
Corollary 2. rank(A) = rank(Λ) hence rank(A) equals the number of non-zero eigenvalues of A
2.2 Idempotent Matrices
Definition 2 (Idempotent). The k×k matrix A, is idempotent if A2 — AA — A.
Definition 3 (Projection matrices). A symmetric, idempotent matrix A is a projection matrix. The effect of the mapping x → Ax is orthogonal projection of x onto col(A).
Theorem 4. All the eigenvalues of an idempotent matrix are either zero or one.
Proof. Suppose that λ is an eigenvalue of the idempotent matrix A. Then there exists a non-zero x such that Ax — λx. But Ax — AAx because A is idempotent. Thus
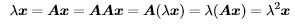
and
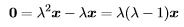
for some non-zero x, which implies that λ — 0 or λ — 1.
Corollary 3. The k×k symmetric matrix A is idempotent of rank(A) — r iff A has r eigenvalues equal to 1 and k−r eigenvalues equal to 0
Proof. A matrix A with r eigenvalues of 1 and k−r eigenvalues of zero has r non-zero eigenvalues and hence rank(A) — r. Because A is symmetric its eigendecomposition is A — QΛQ' for an orthogonal Q and a diagonal Λ. Because the eigenvalues of Λ are the same as those of A, they must be all zeros or ones. That is all the diagonal elements of Λ are zero or one. Hence Λ is idempotent, ΛΛ — Λ, and
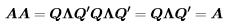
is also idempotent.
Corollary 4. For a symmetric idempotent matrix A, we have tr(A) — rank(A), which is the dimension of col(A), the space into which A projects.
2.3 Expected Values and Covariance Matrices of Random Vectors
An k-dimensional vector-valued random variable (or, more simply, a random vector),X, is a k-vector composed of k scalar random variables
X = (X1,...,Xk)'
If the expected values of the component random variables are µi = E(Xi), i = 1,...,k then
E(X) = µX = (µ1,...,µk)'
Suppose that Y = (Y1,...,Ym)' is an m-dimensional random vector, then the covariance of X and Y, written Cov(X,Y) is
ΣXY = Cov(X,Y) = E[(X −µX)(Y−µY)']
The variance-covariance matrix of X is
Var(X) = ΣXX = E[(X −µX)(X −µ§)
Suppose that c is a constant m-vector, A is a constant m×k matrix and Z = ZX + c is a linear transformation of X. Then E(Z) = AE(X) + c
and
Var(Z) = AVar(X)A'
If we let W = BY + d be a linear transformation of Y for suitably sized B and d then Cov(Z,W) = ACov(X,Y)B'
Theorem 5. The variance-covariance matrix ΣX,X of X is a symmetric and positive semi-definite matrix
Proof. The result follows from the property that the variance of a scalar random variable is nonnegative. Suppose that b is any nonzero, constant k-vector. Then
0 ≤ Var(b'X) = b'ΣXXb
which is the positive, semi-definite condition.
2.4 Mean and Variance of Quadratic Forms
Theorem 6. Let X be a k-dimensional random vector and A be a constant k×k symmetric matrix. If E(X) = µ and Var(X) = Σ, then
E(X'AX) = tr(AΣ) + µ'Aµ
Proof.
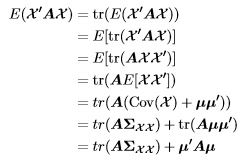
2.5 Distribution of Quadratic Forms in Normal Random Variables
Definition 4 (Non-Central χ2). If X is a (scalar) normal random variable with E(X) = µ and Var(X) = 1, then the random variableV = X2 is distributed as 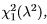 which is called the noncentral χ2 distribution with 1 degree of freedom and non-centrality parameter λ2 — µ2. The mean and variance of V are
which is called the noncentral χ2 distribution with 1 degree of freedom and non-centrality parameter λ2 — µ2. The mean and variance of V are
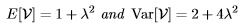
As described in the previous chapter, we are particularly interested in random n-vectors, Y , that have a spherical normal distribution.
Theorem 7.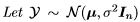 be an n-vector with a spherical normal distribution and A be an n × n symmetric matrix. Then the ratio
be an n-vector with a spherical normal distribution and A be an n × n symmetric matrix. Then the ratio 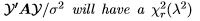 distribution with λ2 = µ'Aµ/σ2 if and only if A is idempotent with rank(A) = r
distribution with λ2 = µ'Aµ/σ2 if and only if A is idempotent with rank(A) = r
Proof. Suppose that A is idempotent (which, in combination with being symmetric, means that it is a projection matrix) and has rank(A) = r. Its eigendecomposition, A = V ΛV ', is such that V is orthogonal and Λ is n×n diagonal with exactly r = rank(A) ones and n−r zeros on the diagonal. Without loss of generality we can (and do) arrange the eigenvalues in decreasing order so that λj = 1, j = 1,...,r and λj = 0, j = r + 1,...,n Let X = V 'Y
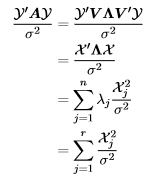
(Notice that the last sum is to j = r, not j = n.) However, 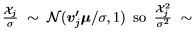
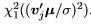 Therefore
Therefore
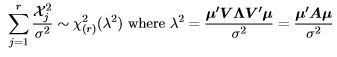
Corollary 5. For A a projection of rank r, (Y'AY)/σ2 has a central χ2 distribution if and only if Aµ = 0
Proof. The χ2 r distribution will be central if and only if
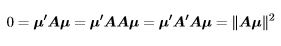
Corollary 6. In the full-rank Gaussian linear model,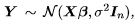 the residual sum of squares,
the residual sum of squares, 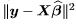 has a central
has a central 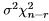 distribution.
distribution.
Proof. In the full rank model with the QR decomposition of X given by
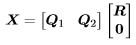
and R invertible, the fitted values are 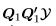 and the residuals are Q2Q2y so the residual sum of squares is the quadratic form
and the residuals are Q2Q2y so the residual sum of squares is the quadratic form 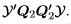 . The matrix defining the quadratic form,
. The matrix defining the quadratic form, 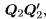 , is a projection matrix. It is obviously symmetric and it is idempotent because
, is a projection matrix. It is obviously symmetric and it is idempotent because 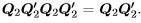 As
As
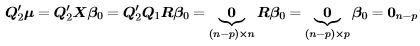
the ratio
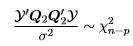
and the RSS has a central 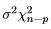 distribution.
distribution.
|
556 videos|198 docs
|
FAQs on Distribution of quadratic forms, CSIR-NET Mathematical Sciences - Mathematics for IIT JAM, GATE, CSIR NET, UGC NET
| 1. What is the definition of a quadratic form? |  |
| 2. How is the distribution of quadratic forms related to CSIR-NET Mathematical Sciences exam? | |
| 3. What are some important properties of quadratic forms? | |
| 4. How can the distribution of quadratic forms be analyzed? | |
| 5. Can you provide an example of a quadratic form and its distribution? | |



UGC NET
,Viva Questions
,GATE
,shortcuts and tricks
,CSIR NET
,Distribution of quadratic forms
,Important questions
,Previous Year Questions with Solutions
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Free
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Distribution of quadratic forms
,Extra Questions
,Sample Paper
,Semester Notes
,study material
,past year papers
,Summary
,GATE
,CSIR NET
,practice quizzes
,MCQs
,UGC NET
,CSIR NET
,ppt
,UGC NET
,Exam
,GATE
,Objective type Questions
,mock tests for examination
,Distribution of quadratic forms
,video lectures
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
;


Distribution of quadratic forms, CSIR-NET Mathematical Sciences Free PDF Download
Importance of Distribution of quadratic forms, CSIR-NET Mathematical Sciences
Distribution of quadratic forms, CSIR-NET Mathematical Sciences Notes
Distribution of quadratic forms, CSIR-NET Mathematical Sciences Mathematics Questions
Study Distribution of quadratic forms, CSIR-NET Mathematical Sciences on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!