Elementary Bayesian inference - 2, CSIR-NET Mathematical Sciences | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

4.5. Proper and Improper Priors
It is important for the prior distribution to be proper. A prior distribution, p(θ), is improper12 when
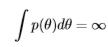
As noted previously, an unbounded uniform prior distribution is an improper prior distribution because p(θ) ∝ 1, for −∞ < θ < ∞. An improper prior distribution can cause an improper posterior distribution. When the posterior distribution is improper, inferences are invalid, it is non-integrable, and Bayes factors cannot be used (though there are exceptions).
To determine the propriety of a joint posterior distribution, the marginal likelihood must be finite for all y. Again, the marginal likelihood is
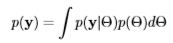
Although improper prior distributions can be used, it is good practice to avoid them.
5. Hierarchical Bayes
Prior distributions may be estimated within the model via hyperprior distributions, which are usually vague and nearly flat. Parameters of hyperprior distributions are called hyperparameters. Using hyperprior distributions to estimate prior distributions is known as hierarchical Bayes. In theory, this process could continue further, using hyper-hyperprior distributions to estimate the hyperprior distributions. Estimating priors through hyperpriors, and from the data, is a method to elicit the optimal prior distributions. One of many natural uses for hierarchical Bayes is multilevel modeling.
Recall that the unnormalized joint posterior distribution (equation 2) is proportional to the likelihood times the prior distribution
p(Θ|y) ∝ p(y|Θ)p(Θ)
The simplest hierarchical Bayes model takes the form
p(Θ,Φ|y) ∝ p(y|Θ)p(Θ|Φ)p(Φ)
where Φ is a set of hyperprior distributions. By reading the equation from right to left, it begins with hyperpriors Φ, which are used conditionally to estimate priors p(Θ|Φ), which in turn is used, as per usual, to estimate the likelihood p(y|Θ), and finally the posterior is p(Θ,Φ|y).
6. Conjugacy
When the posterior distribution p(Θ|y) is in the same family as the prior probability distribution p(Θ), the prior and posterior are then called conjugate distributions, and the prior is called a conjugate prior for the likelihood13. For example, the Gaussian family is conjugate to itself (or self-conjugate) with respect to a Gaussian likelihood function: if the likelihood function is Gaussian, then choosing a Gaussian prior for the mean will ensure that the posterior distribution is also Gaussian. All probability distributions in the exponential family have conjugate priors. See Robert (2007) for a catalog. Although the gamma distribution is the conjugate prior distribution for the precision of a normal distribution (Spiegelhalter, Thomas, Best, and Lunn 2003),
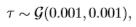
better properties for scale parameters are yielded with the non-conjugate, proper, halfCauchy14 distribution, with a general recommendation of scale=25 for a weakly informative scale parameter (Gelman 2006),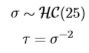
When the half-Cauchy is unavailable, a uniform distribution is often placed on σ in hierarchical Bayes when the number of groups is, say, at least five,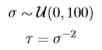
Conjugacy is mathematically convenient in that the posterior distribution follows a known parametric form (Gelman et al. 2004, p. 40). It is obviously easier to summarize a normal distribution than a complex, multi-modal distribution with no known form. If information is available that contradicts a conjugate parametric family, then it may be necessary to use a more realistic, inconvenient, prior distribution.
The basic justification for the use of conjugate prior distributions is similar to that for using standard models (such as the binomial and normal) for the likelihood: it is easy to understand the results, which can often be put in analytic form, they are often a good approximation, and they simplify computations. Also, they are useful as building blocks for more complicated models, including many dimensions, where conjugacy is typically impossible. For these reasons, conjugate models can be good starting points (Gelman et al. 2004, p. 41).
Nonconjugate prior distributions can make interpretations of posterior inferences less transparent and computation more difficult, though this alternative does not pose any conceptual problems. In practice, for complicated models, conjugate prior distributions may not even be possible (Gelman et al. 2004, p. 41-42).
When conjugate distributions are used, a summary statistic for a posterior distribution of θ may be represented as t(y) and said to be a sufficient statistic (Gelman et al. 2004, p. 42). When nonconjugate distributions are used, a summary statistic for a posterior distribution is usually not a sufficient statistic. A sufficient statistic is a statistic that has the property of sufficiency with respect to a statistical model and the associated unknown parameter. The quantity t(y) is said to be a sufficient statistic for θ, because the likelihood for θ depends on the data y only through the value of t(y). Sufficient statistics are useful in algebraic manipulations of likelihoods and posterior distributions.
7. Likelihood
In order to complete the definition of a Bayesian model, both the prior distributions and the likelihood15 must be approximated or fully specified. The likelihood, likelihood function, or p(y|Θ), contains the available information provided by the sample. The likelihood is
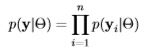
The data y affects the posterior distribution p(Θ|y) only through the likelihood function p(y|Θ). In this way, Bayesian inference obeys the likelihood principle, which states that for a given sample of data, any two probability models p(y|Θ) that have the same likelihood function yield the same inference for Θ. For more information on the likelihood principle, see section 7.2.
7.1. Terminology: From Inverse Probability to Bayesian Probability
A gambler’s dispute in 1654 led to the creation of a mathematical theory of probability by two famous French mathematicians, Blaise Pascal and Pierre de Fermat. Reverend Thomas Bayes (1701-1761) discovered Bayes’ theorem, published posthumously in 1763, in which he was the first to use inverse probability (Bayes and Price 1763). ‘Inverse probability’ refers to assigning a probability distribution to an unobserved variable, and is in essence, probability in the opposite direction of the usual sense.
For example, the probability of obtaining heads on the next coin flip in a Bayesian context would be the predicted probability, p(ynew|y,θ), but to estimate this predicted probability, the probability distribution of θ must first be estimated, using coin toss data y to estimate the parameter θ by the likelihood function p(y|θ), which contains the likelihood p(θ|y), where θ is estimated from the data, y. Therefore, the data, y, is used to estimate the most probable θ that would lead to a data-generating process for y.
Unaware of Bayes, Pierre-Simon Laplace (1749-1827) independently developed Bayes’ theorem and first published his version in 1774, eleven years after Bayes, in one of Laplace’s first major works (Laplace 1774, p. 366-367). In 1812, Laplace (1749-1827) introduced a host of new ideas and mathematical techniques in his book, Theorie Analytique des Probabilites (Laplace 1812). Before Laplace, probability theory was solely concerned with developing a mathematical analysis of games of chance. Laplace applied probabilistic ideas to many scientific and practical problems.
Then, in 1814, Laplace published his “Essai philosophique sur les probabilites”, which introduced a mathematical system of inductive reasoning based on probability (Laplace 1814). In it, the Bayesian interpretation of probability was developed independently by Laplace, much more thoroughly than Bayes, so some “Bayesians” refer to Bayesian inference as Laplacian inference.
Terminology has changed, so that today, Bayesian probability (rather than inverse probability) refers to assigning a probability distribution to an unobservable variable. The “distribution” of an unobserved variable given data is the likelihood function (which is not a distribution), and the distribution of an unobserved variable, given both data and a prior distribution, is the posterior distribution. The term“Bayesian”, which displaced“inverse probability”, was in fact introduced by Ronald A. Fisher as a derogatory term.
In modern terms, given a probability distribution p(y|θ) for an observable quantity y conditional on an unobserved variable θ, the “inverse probability” is the posterior distribution p(θ|y), which depends both on the likelihood function (the inversion of the probability distribution) and a prior distribution. The distribution p(y|θ) itself is called the direct probability
However, p(y|θ) is also called the likelihood function, which can be confusing, seeming to pit the definitions of probability and likelihood against each other. A quick introduction to the likelihood principle follows, and finally all of the information on likelihood comes together in the section entitled “Likelihood Function of a Parameterized Model”.
7.2. The Likelihood Principle
An informal summary of the likelihood principle may be that inferences from data to hypotheses should depend on how likely the actual data are under competing hypotheses, not on how likely imaginary data would have been under a single“null”hypothesis or any other properties of merely possible data. Bayesian inferences depend only on the probabilities assigned due to the observed data, not due to other data that might have been observed.
A more precise interpretation may be that inference procedures which make inferences about simple hypotheses should not be justified by appealing to probabilities assigned to observations that have not occurred. The usual interpretation is that any two probability models with the same likelihood function yield the same inference for θ.
Some authors mistakenly claim that frequentist inference, such as the use of maximum likelihood estimation (MLE), obeys the likelihood, though it does not. Some authors claim that the largest contention between Bayesians and frequentists regards prior probability distributions. Other authors argue that, although the subject of priors gets more attention, the true contention between frequentist and Bayesian inference is the likelihood principle, which Bayesian inference obeys, and frequentist inference does not.
There have been many frequentist attacks on the likelihood principle, and have been shown to be poor arguments. Some Bayesians have argued that Bayesian inference is incompatible with the likelihood principle on the grounds that there is no such thing as an isolated likelihood function (Bayarri and DeGroot 1987). They argue that in a Bayesian analysis there is no principled distinction between the likelihood function and the prior probability function. The objection is motivated, for Bayesians, by the fact that prior probabilities are needed in order to apply what seems like the likelihood principle. Once it is admitted that there is a universal necessity to use prior probabilities, there is no longer a need to separate the likelihood function from the prior. Thus, the likelihood principle is accepted ‘conditional’ on the assumption that a likelihood function has been specified, but it is denied that specifying a likelihood function is necessary. Nonetheless, the likelihood principle is seen as a useful Bayesian weapon to combat frequentism.
Following are some interesting qutoes from prominent statisticians
“Using Bayes’ rule with a chosen probability model means that the data y affect posterior inference ’only’ through the function p(y|θ), which, when regarded as a function of θ, for fixed y, is called the ‘likelihood function’. In this way Bayesian inference obeys what is sometimes called the ‘likelihood principle’, which states that for a given sample of data, any two probability models p(y|θ) that have the same likelihood function yield the same inference for θ”(Gelman et al. 2004, p. 9).
“The likelihood principle is reasonable, but only within the framework of the model or family of models adopted for a particular analysis” (Gelman et al. 2004, p. 9).
Frequentist “procedures typically violate the likelihood principle, since long-run behavior under hypothetical repetitions depends on the entire distribution p(y|θ), y ∈ Y and not only on the likelihood” (Bernardo and Smith 2000, p. 454).
There is “a general fact about the mechanism of parametric Bayesian inference which is trivially obvious; namely ‘for any specified p(θ), if the likelihood functions p1(y1|θ),p2(y2|θ) are proportional as functions of θ, the resulting posterior densities for θ are identical’. It turns out...that many non-Bayesian inference procedures do not lead to identical inferences when applied to such proportional likelihoods. The assertion that they ‘should’, the so-called ‘Likelihood Principle’, is therefore a controversial issue among statisticians. In contrast, in the Bayesian inference context...this is a straightforward consequence of Bayes’ theorem, rather than an imposed ‘principle’ ” (Bernardo and Smith 2000, p. 249).
“Although the likelihood principle is implicit in Bayesian statistics, it was developed as a separate principle by Barnard (Barnard 1949), and became a focus of interest when Birnbaum (1962) showed that it followed from the widely accepted sufficiency and conditionality principles” (Bernardo and Smith 2000, p. 250).
“The likelihood principle, by itself, is not sufficient to build a method of inference but should be regarded as a minimum requirement of any viable form of inference. This is a controversial point of view for anyone familiar with modern econometrics literature. Much of this literature is devoted to methods that do not obey the likelihood principle...” (Rossi, Allenby, and McCulloch 2005, p. 15).
“Adherence to the likelihood principle means that inferences are ‘conditional’ on the observed data as the likelihood function is parameterized by the data. This is worth contrasting to any sampling-based approach to inference. In the sampling literature, inference is conducted by examining the sampling distribution of some estimator of θ, 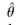 = f(y). Some sort of sampling experiment results in a distribution of y and therefore, the estimator is viewed as a random variable. The sampling distribution of the estimator summarizes the properties of the estimator ‘prior’ to observing the data. As such, it is irrelevant to making inferences given the data we actually observe. For any finite sample, this dinstinction is extremely important. One must conclude that, given our goal for inference, sampling distributions are simply not useful” (Rossi et al. 2005, p. 15).
= f(y). Some sort of sampling experiment results in a distribution of y and therefore, the estimator is viewed as a random variable. The sampling distribution of the estimator summarizes the properties of the estimator ‘prior’ to observing the data. As such, it is irrelevant to making inferences given the data we actually observe. For any finite sample, this dinstinction is extremely important. One must conclude that, given our goal for inference, sampling distributions are simply not useful” (Rossi et al. 2005, p. 15).
7.3. Likelihood Function of a Parameterized Model
In non-technical parlance,“likelihood”is usually a synonym for“probability”, but in statistical usage there is a clear distinction: whereas“probability”allows us to predict unknown outcomes based on known parameters,“likelihood”allows us to estimate unknown parameters based on known outcomes. In a sense, likelihood can be thought a reversed version of conditional probability. Reasoning forward from a given parameter θ, the conditional probability of y is the density p(y|θ). With θ as a parameter, here are relationships in expressions of the likelihood function
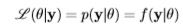
where y is the observed outcome of an experiment, and the likelihood (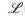 ) of θ given y is equal to the density p(y|θ) or function f(y|θ). When viewed as a function of y with θ fixed, it is not a likelihood function (θ|y), but merely a probability density function p(y|θ). When viewed as a function of θ with y fixed, it is a likelihood function and may be denoted as (θ|y), p(y|θ), or f(y|θ)16.
) of θ given y is equal to the density p(y|θ) or function f(y|θ). When viewed as a function of y with θ fixed, it is not a likelihood function (θ|y), but merely a probability density function p(y|θ). When viewed as a function of θ with y fixed, it is a likelihood function and may be denoted as (θ|y), p(y|θ), or f(y|θ)16.
For example, in a Bayesian linear regression with an intercept and two independent variables, the model may be specified as
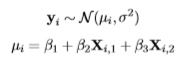
The dependent variable y, indexed by i = 1,...,n, is stochastic, and normally-distributed according to the expectation vector µ, and variance σ2. Expectation vector µ is an additive, linear function of a vector of regression parameters, β, and the design matrix X.
Since y is normally-distributed, the probability density function (PDF) of a normal distribution will be used, and is usually denoted as
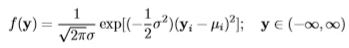
By considering a conditional distribution, the record-level likelihood in Bayesian notation is
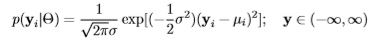
In both theory and practice, and in both frequentist and Bayesian inference, the log-likelihood is used instead of the likelihood, on both the record- and model-level. The model-level product of record-level likelihoods can exceed the range of a number that can be stored by a computer, which is usually affected by sample size. By estimating a record-level log-likelihood, rather than likelihood, the model-level log-likelihood is the sum of the record-level log-likelihoods, rather than a product of the record-level likelihoods.
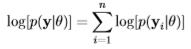
rather than
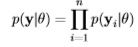
As a function of θ, the unnormalized joint posterior distribution is the product of the likelihood function and the prior distributions. To continue with the example of Bayesian linear regression, here is the unnormalized joint posterior distribution
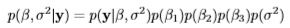
More usually, the logarithm of the unnormalized joint posterior distribution is used, which is the sum of the log-likelihood and prior distributions. Here is the logarithm of the unnormalized joint posterior distribution for this example

The logarithm of the unnormalized joint posterior distribution is maximized with numerical approximation.
8. Numerical Approximation
The technical problem of evaluating quantities required for Bayesian inference typically reduces to the calculation of a ratio of two integrals (Bernardo and Smith 2000, p. 339). In all cases, the technical key to the implementation of the formal solution given by Bayes’ theorem is the ability to perform a number of integrations (Bernardo and Smith 2000, p. 340). Except in certain rather stylized problems, the required integrations will not be feasible analytically and, thus, efficient approximation strategies are required.
There are too many different types of numerical approximation algorithms in Bayesian inference to cover in any detail in this article. An incomplete list of broad categories of Bayesian numerical approximation may include Approximate Bayesian Computation (ABC), Importance Sampling, Iterative Quadrature, Laplace Approximation, Markov chain Monte Carlo (MCMC), and Variational Bayes (VB). For more information on algorithms in LaplacesDemon, see the accompanying vignette entitled “LaplacesDemon Tutorial”.
Approximate Bayesian Computation (ABC), also called likelihood-free estimation, is a family of numerical approximation techniques in Bayesian inference. ABC is especially useful when evaluation of the likelihood, p(y|Θ) is computationally prohibitive, or when suitable likelihoods are unavailable. As such, ABC algorithms estimate likelihood-free approximations. ABC is usually faster than a similar likelihood-based numerical approximation technique, because the likelihood is not evaluated directly, but replaced with an approximation that is usually easier to calculate. The approximation of a likelihood is usually estimated with a measure of distance between the observed sample, y, and its replicate given the model, yrep, or with summary statistics of the observed and replicated samples.
Importance Sampling is a method of estimating a distribution with samples from a different distribution, called the importance distribution. Importance weights are assigned to each sample. The main difficulty with importance sampling is in the selection of the importance distribution. Importance sampling is the basis of a wide variety of algorithms, some of which involve the combination of importance sampling and Markov chain Monte Carlo. There are also many variations of importance sampling, including adaptive importance sampling, and parametric and nonparametric self-normalized importance sampling. Population Monte Carlo (PMC) is based on adaptive importance sampling.
Iterative quadrature is a traditional approach to evaluating integrals. Multidimensional quadrature, often called cubature, performs well, but is limited usually to ten or fewer parameters. Componentwise quadrature may be applied to any model regardless of dimension, but estimates only variance, rather than covariance. Bayesian quadrature typically uses adaptive Gauss-Hermite quadrature, which assumes the marginal posterior distributions are normallydistrubted. Under this assumption, the conditional mean and conditional variance of each distribution is adapted each iteration according to the evaluation of samples determined by quadrature rules.
Laplace Approximation dates back to Laplace (1774, 1814), and is used to approximate the posterior moments of integrals. Specifically, the posterior mode is estimated for each parameter, assumed to be unimodal and Gaussian. As a Gaussian distribution, the posterior mean is the same as the posterior mode, and the variance is estimated. Laplace Approximation is a family of deterministic algorithms that usually converge faster than MCMC, and just a little slower than Maximum Likelihood Estimation (MLE) (Azevedo-Filho and Shachter 1994). Laplace Approximation shares many limitations of MLE, including asymptotic estimation with respect to sample size.
MCMC algorithms originated in statistical physics and are now used in Bayesian inference to sample from probability distributions by constructing Markov chains. In Bayesian inference, the target distribution of each Markov chain is usually a marginal posterior distribution, such as each parameter θ. Each Markov chain begins with an initial value and the algorithm iterates, attempting to maximize the logarithm of the unnormalized joint posterior distribution and eventually arriving at each target distribution. Each iteration is considered a state. A Markov chain is a random process with a finite state-space and the Markov property, meaning that the next state depends only on the current state, not on the past. The quality of the marginal samples usually improves with the number of iterations.
A Monte Carlo method is an algorithm that relies on repeated pseudo-random sampling for computation, and is therefore stochastic (as opposed to deterministic). Monte Carlo methods are often used for simulation. The union of Markov chains and Monte Carlo methods is called MCMC. The revival of Bayesian inference since the 1980s is due to MCMC algorithms and increased computing power. The most prevalent MCMC algorithms may be the simplest: random-walk Metropolis and Gibbs sampling. There are a large number of MCMC algorithms, and further details on MCMC are best explored outside of this article.
VB is a family of algorithms within variational inference. VB are deterministic optimization algorithms that approximate the posterior with a distribution. Each marginal posterior distribution is estimated with an approximating distribution. VB usually converges faster than MCMC. VB shares many limitations of MLE, including asymptotic estimation with respect to sample size.
|
556 videos|198 docs
|



shortcuts and tricks
,UGC NET
,UGC NET
,GATE
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,MCQs
,past year papers
,Previous Year Questions with Solutions
,Viva Questions
,Sample Paper
,study material
,video lectures
,practice quizzes
,Important questions
,Exam
,Objective type Questions
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Elementary Bayesian inference - 2
,Extra Questions
,mock tests for examination
,CSIR NET
,Free
,CSIR NET
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Elementary Bayesian inference - 2
,UGC NET
,Elementary Bayesian inference - 2
,GATE
,GATE
,CSIR NET
,ppt
,Semester Notes
,Summary
;


Elementary Bayesian inference - 2, CSIR-NET Mathematical Sciences Free PDF Download
Importance of Elementary Bayesian inference - 2, CSIR-NET Mathematical Sciences
Elementary Bayesian inference - 2, CSIR-NET Mathematical Sciences Notes
Elementary Bayesian inference - 2, CSIR-NET Mathematical Sciences Mathematics Questions
Study Elementary Bayesian inference - 2, CSIR-NET Mathematical Sciences on the App
|
© EduRev
|
Education Revolution
|



|





