Exploratory data analysis:Introduction and Univariate non-graphical EDA | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

A first look at the data.
As mentioned exploratory data analysis or “EDA” is a critical first step in analyzing the data from an experiment. Here are the main reasons we use EDA:
detection of mistakes
checking of assumptions
preliminary selection of appropriate models
determining relationships among the explanatory variables, and
assessing the direction and rough size of relationships between explanatory and outcome variables.
Loosely speaking, any method of looking at data that does not include formal statistical modeling and inference falls under the term exploratory data analysis.
4.1 Typical data format and the types of EDA
The data from an experiment are generally collected into a rectangular array (e.g., spreadsheet or database), most commonly with one row per experimental subject and one column for each subject identifier, outcome variable, and explanatory variable. Each column contains the numeric values for a particular quantitative variable or the levels for a categorical variable. (Some more complicated experiments require a more complex data layout.)
People are not very good at looking at a column of numbers or a whole spreadsheet and then determining important characteristics of the data. They find looking at numbers to be tedious, boring, and/or overwhelming. Exploratory data analysis techniques have been devised as an aid in this situation. Most of these techniques work in part by hiding certain aspects of the data while making other aspects more clear.
Exploratory data analysis is generally cross-classified in two ways. First, each method is either non-graphical or graphical. And second, each method is either univariate or multivariate (usually just bivariate).
Non-graphical methods generally involve calculation of summary statistics, while graphical methods obviously summarize the data in a diagrammatic or pictorial way. Univariate methods look at one variable (data column) at a time, while multivariate methods look at two or more variables at a time to explore relationships. Usually our multivariate EDA will be bivariate (looking at exactly two variables), but occasionally it will involve three or more variables. It is almost always a good idea to perform univariate EDA on each of the components of a multivariate EDA before performing the multivariate EDA.
Beyond the four categories created by the above cross-classification, each of the categories of EDA have further divisions based on the role (outcome or explanatory) and type (categorical or quantitative) of the variable(s) being examined.
Although there are guidelines about which EDA techniques are useful in what circumstances, there is an important degree of looseness and art to EDA. Competence and confidence come with practice, experience, and close observation of others. Also, EDA need not be restricted to techniques you have seen before; sometimes you need to invent a new way of looking at your data.
The four types of EDA are univariate non-graphical, multivariate nongraphical, univariate graphical, and multivariate graphical. |
This chapter first discusses the non-graphical and graphical methods for looking at single variables, then moves on to looking at multiple variables at once, mostly to investigate the relationships between the variables.
4.2 Univariate non-graphical EDA
The data that come from making a particular measurement on all of the subjects in a sample represent our observations for a single characteristic such as age, gender, speed at a task, or response to a stimulus. We should think of these measurements as representing a “sample distribution” of the variable, which in turn more or less represents the “population distribution” of the variable. The usual goal of univariate non-graphical EDA is to better appreciate the “sample distribution” and also to make some tentative conclusions about what population distribution(s) is/are compatible with the sample distribution. Outlier detection is also a part of this analysis.
4.2.1 Categorical data
The characteristics of interest for a categorical variable are simply the range of values and the frequency (or relative frequency) of occurrence for each value. (For ordinal variables it is sometimes appropriate to treat them as quantitative variables using the techniques in the second part of this section.) Therefore the only useful univariate non-graphical techniques for categorical variables is some form of tabulation of the frequencies, usually along with calculation of the fraction (or percent) of data that falls in each category. For example if we categorize subjects by College at Carnegie Mellon University as H&SS, MCS, SCS and “other”, then there is a true population of all students enrolled in the 2007 Fall semester. If we take a random sample of 20 students for the purposes of performing a memory experiment, we could list the sample “measurements” as H&SS, H&SS, MCS, other, other, SCS, MCS, other, H&SS, MCS, SCS, SCS, other, MCS, MCS, H&SS, MCS, other, H&SS, SCS. Our EDA would look like this:

Note that it is useful to have the total count (frequency) to verify that we have an observation for each subject that we recruited. (Losing data is a common mistake, and EDA is very helpful for finding mistakes.). Also, we should expect that the proportions add up to 1.00 (or 100%) if we are calculating them correctly (count/total). Once you get used to it, you won’t need both proportion (relative frequency) and percent, because they will be interchangeable in your mind.
A simple tabulation of the frequency of each category is the best univariate non-graphical EDA for categorical data. |
4.2.2 Characteristics of quantitative data
Univariate EDA for a quantitative variable is a way to make preliminary assessments about the population distribution of the variable using the data of the observed sample. |
The characteristics of the population distribution of a quantitative variable are its center, spread, modality (number of peaks in the pdf), shape (including “heaviness of the tails”), and outliers. (See section 3.5.) Our observed data represent just one sample out of an infinite number of possible samples. The characteristics of our randomly observed sample are not inherently interesting, except to the degree that they represent the population that it came from.
What we observe in the sample of measurements for a particular variable that we select for our particular experiment is the “sample distribution”. We need to recognize that this would be different each time we might repeat the same experiment, due to selection of a different random sample, a different treatment randomization, and different random (incompletely controlled) experimental conditions. In addition we can calculate “sample statistics” from the data, such as sample mean, sample variance, sample standard deviation, sample skewness and sample kurtosis. These again would vary for each repetition of the experiment, so they don’t represent any deep truth, but rather represent some uncertain information about the underlying population distribution and its parameters, which are what we really care about.
Many of the sample’s distributional characteristics are seen qualitatively in the univariate graphical EDA technique of a histogram (see 4.3.1). In most situations it is worthwhile to think of univariate non-graphical EDA as telling you about aspects of the histogram of the distribution of the variable of interest. Again, these aspects are quantitative, but because they refer to just one of many possible samples from a population, they are best thought of as random (non-fixed) estimates of the fixed, unknown parameters (see section 3.5) of the distribution of the population of interest.
If the quantitative variable does not have too many distinct values, a tabulation, as we used for categorical data, will be a worthwhile univariate, non-graphical technique. But mostly, for quantitative variables we are concerned here with the quantitative numeric (non-graphical) measures which are the various sample statistics. In fact, sample statistics are generally thought of as estimates of the corresponding population parameters.
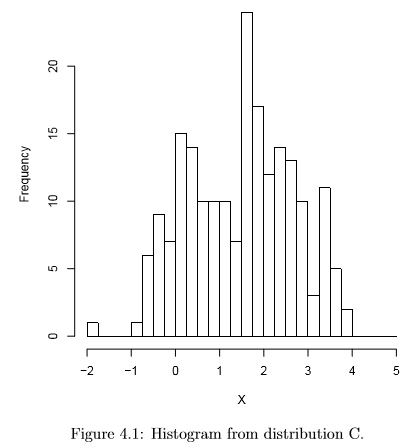
Figure 4.1 shows a histogram of a sample of size 200 from the infinite population characterized by distribution C of figure 3.1 from section 3.5. Remember that in that section we examined the parameters that characterize theoretical (population) distributions. Now we are interested in learning what we can (but not everything, because parameters are “secrets of nature”) about these parameters from measurements on a (random) sample of subjects out of that population.
The bi-modality is visible, as is an outlier at X=-2. There is no generally recognized formal definition for outlier, but roughly it means values that are outside of the areas of a distribution that would commonly occur. This can also be thought of as sample data values which correspond to areas of the population pdf (or pmf) with low density (or probability). The definition of “outlier” for standard boxplots is described below (see 4.3.3). Another common definition of “outlier” consider any point more than a fixed number of standard deviations from the mean to be an “outlier”, but these and other definitions are arbitrary and vary from situation to situation.
For quantitative variables (and possibly for ordinal variables) it is worthwhile looking at the central tendency, spread, skewness, and kurtosis of the data for a particular variable from an experiment. But for categorical variables, none of these make any sense.
4.2.3 Central tendency
The central tendency or “location” of a distribution has to do with typical or middle values. The common, useful measures of central tendency are the statistics called (arithmetic) mean, median, and sometimes mode. Occasionally other means such as geometric, harmonic, truncated, or Winsorized means are used as measures of centrality. While most authors use the term “average” as a synonym for arithmetic mean, some use average in a broader sense to also include geometric, harmonic, and other means.
Assuming that we have n data values labeled x1 through xn, the formula for calculating the sample (arithmetic) mean is
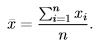
The arithmetic mean is simply the sum of all of the data values divided by the number of values. It can be thought of as how much each subject gets in a “fair” re-division of whatever the data are measuring. For instance, the mean amount of money that a group of people have is the amount each would get if all of the money were put in one “pot”, and then the money was redistributed to all people evenly. I hope you can see that this is the same as “summing then dividing by n”.
For any symmetrically shaped distribution (i.e., one with a symmetric histogram or pdf or pmf) the mean is the point around which the symmetry holds. For non-symmetric distributions, the mean is the “balance point”: if the histogram is cut out of some homogeneous stiff material such as cardboard, it will balance on a fulcrum placed at the mean.
For many descriptive quantities, there are both a sample and a population version. For a fixed finite population or for a theoretic infinite population described by a pmf or pdf, there is a single population mean which is a fixed, often unknown, value called the mean parameter (see section 3.5). On the other hand, the “sample mean” will vary from sample to sample as different samples are taken, and so is a random variable. The probability distribution of the sample mean is referred to as its sampling distribution. This term expresses the idea that any experiment could (at least theoretically, given enough resources) be repeated many times and various statistics such as the sample mean can be calculated each time. Often we can use probability theory to work out the exact distribution of the sample statistic, at least under certain assumptions.
The median is another measure of central tendency. The sample median is the middle value after all of the values are put in an ordered list. If there are an even number of values, take the average of the two middle values. (If there are ties at the middle, some special adjustments are made by the statistical software we will use. In unusual situations for discrete random variables, there may not be a unique median.)
For symmetric distributions, the mean and the median coincide. For unimodal skewed (asymmetric) distributions, the mean is farther in the direction of the “pulled out tail” of the distribution than the median is. Therefore, for many cases of skewed distributions, the median is preferred as a measure of central tendency. For example, according to the US Census Bureau 2004 Economic Survey, the median income of US families, which represents the income above and below which half of families fall, was $43,318. This seems a better measure of central tendency than the mean of $60,828, which indicates how much each family would have if we all shared equally. And the difference between these two numbers is quite substantial. Nevertheless, both numbers are “correct”, as long as you understand their meanings.
The median has a very special property called robustness. A sample statistic is “robust” if moving some data tends not to change the value of the statistic. The median is highly robust, because you can move nearly all of the upper half and/or lower half of the data values any distance away from the median without changing the median. More practically, a few very high values or very low values usually have no effect on the median.
A rarely used measure of central tendency is the mode, which is the most likely or frequently occurring value. More commonly we simply use the term “mode” when describing whether a distribution has a single peak (unimodal) or two or more peaks (bimodal or multi-modal). In symmetric, unimodal distributions, the mode equals both the mean and the median. In unimodal, skewed distributions the mode is on the other side of the median from the mean. In multi-modal distributions there is either no unique highest mode, or the highest mode may well be unrepresentative of the central tendency.
The most common measure of central tendency is the mean. For skewed distribution or when there is concern about outliers, the median may be preferred. |
4.2.4 Spread
Several statistics are commonly used as a measure of the spread of a distribution, including variance, standard deviation, and interquartile range. Spread is an indicator of how far away from the center we are still likely to find data values.
The variance is a standard measure of spread. It is calculated for a list of numbers, e.g., the n observations of a particular measurement labeled x1 through xn, based on the n sample deviations (or just “deviations”). Then for any data value, xi, the corresponding deviation is 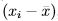 , which is the signed (- for lower and + for higher) distance of the data value from the mean of all of the n data values. It is not hard to prove that the sum of all of the deviations of a sample is zero.
, which is the signed (- for lower and + for higher) distance of the data value from the mean of all of the n data values. It is not hard to prove that the sum of all of the deviations of a sample is zero.
The variance of a population is defined as the mean squared deviation (see section 3.5.2). The sample formula for the variance of observed data conventionally has n−1 in the denominator instead of n to achieve the property of “unbiasedness”, which roughly means that when calculated for many different random samples from the same population, the average should match the corresponding population quantity (here, σ2). The most commonly used symbol for sample variance is s2, and the formula is
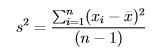
which is essentially the average of the squared deviations, except for dividing by n−1 instead of n. This is a measure of spread, because the bigger the deviations from the mean, the bigger the variance gets. (In most cases, squaring is better than taking the absolute value because it puts special emphasis on highly deviant values.) As usual, a sample statistic like s2 is best thought of as a characteristic of a particular sample (thus varying from sample to sample) which is used as an estimate of the single, fixed, true corresponding parameter value from the population, namely σ2.
Another (equivalent) way to write the variance formula, which is particularly useful for thinking about ANOVA is
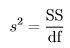
where SS is “sum of squared deviations”, often loosely called “sum of squares”, and df is “degrees of freedom” (see section 4.6).
Because of the square, variances are always non-negative, and they have the somewhat unusual property of having squared units compared to the original data. So if the random variable of interest is a temperature in degrees, the variance has units “degrees squared”, and if the variable is area in square kilometers, the variance is in units of “kilometers to the fourth power”.
Variances have the very important property that they are additive for any number of different independent sources of variation. For example, the variance of a measurement which has subject-to-subject variability, environmental variability, and quality-of-measurement variability is equal to the sum of the three variances. This property is not shared by the “standard deviation”.
The standard deviation is simply the square root of the variance. Therefore it has the same units as the original data, which helps make it more interpretable. The sample standard deviation is usually represented by the symbol s. For a theoretical Gaussian distribution, we learned in the previous chapter that mean plus or minus 1, 2 or 3 standard deviations holds 68.3, 95.4 and 99.7% of the probability respectively, and this should be approximately true for real data from a Normal distribution.
The variance and standard deviation are two useful measures of spread. The variance is the mean of the squares of the individual deviations. The standard deviation is the square root of the variance. For Normally distributed data, approximately 95% of the values lie within 2 sd of the mean. |
A third measure of spread is the interquartile range. To define IQR, we first need to define the concepts of quartiles. The quartiles of a population or a sample are the three values which divide the distribution or observed data into even fourths. So one quarter of the data fall below the first quartile, usually written Q1; one half fall below the second quartile (Q2); and three fourths fall below the third quartile (Q3). The astute reader will realize that half of the values fall above Q2, one quarter fall above Q3, and also that Q2 is a synonym for the median. Once the quartiles are defined, it is easy to define the IQR as IQR = Q3−Q1. By definition, half of the values (and specifically the middle half) fall within an interval whose width equals the IQR. If the data are more spread out, then the IQR tends to increase, and vice versa.
The IQR is a more robust measure of spread than the variance or standard deviation. Any number of values in the top or bottom quarters of the data can be moved any distance from the median without affecting the IQR at all. More practically, a few extreme outliers have little or no effect on the IQR.
In contrast to the IQR, the range of the data is not very robust at all. The range of a sample is the distance from the minimum value to the maximum value: range = maximum - minimum. If you collect repeated samples from a population, the minimum, maximum and range tend to change drastically from sample to sample, while the variance and standard deviation change less, and the IQR least of all. The minimum and maximum of a sample may be useful for detecting outliers, especially if you know something about the possible reasonable values for your variable. They often (but certainly not always) can detect data entry errors such as typing a digit twice or transposing digits (e.g., entering 211 instead of 21 and entering 19 instead of 91 for data that represents ages of senior citizens.)
The IQR has one more property worth knowing: for normally distributed data only, the IQR approximately equals 4/3 times the standard deviation. This means that for Gaussian distributions, you can approximate the sd from the IQR by calculating 3/4 of the IQR.
The interquartile range (IQR) is a robust measure of spread. |
4.2.5 Skewness and kurtosis
Two additional useful univariate descriptors are the skewness and kurtosis of a distribution. Skewness is a measure of asymmetry. Kurtosis is a measure of “peakedness” relative to a Gaussian shape. Sample estimates of skewness and kurtosis are taken as estimates of the corresponding population parameters (see section 3.5.3). If the sample skewness and kurtosis are calculated along with their standard errors, we can roughly make conclusions according to the following table where e is an estimate of skewness and u is an estimate of kurtosis, and SE(e) and SE(u) are the corresponding standard errors.

For a positive skew, values far above the mode are more common than values far below, and the reverse is true for a negative skew. When a sample (or distribution) has positive kurtosis, then compared to a Gaussian distribution with the same variance or standard deviation, values far from the mean (or median or mode) are more likely, and the shape of the histogram is peaked in the middle, but with fatter tails. For a negative kurtosis, the peak is sometimes described has having “broader shoulders” than a Gaussian shape, and the tails are thinner, so that extreme values are less likely.
Skewness is a measure of asymmetry. Kurtosis is a more subtle measure of peakedness compared to a Gaussian distribution. |
|
556 videos|198 docs
|
FAQs on Exploratory data analysis:Introduction and Univariate non-graphical EDA - Mathematics for IIT JAM, GATE, CSIR NET, UGC NET
| 1. What is exploratory data analysis? |  |
| 2. What is the purpose of univariate non-graphical EDA? | |
| 3. What are some commonly used summary statistics in univariate non-graphical EDA? | |
| 4. How can univariate non-graphical EDA help in data analysis? | |
| 5. What are some limitations of univariate non-graphical EDA? | |



Exploratory data analysis:Introduction and Univariate non-graphical EDA | Mathematics for IIT JAM
,Exploratory data analysis:Introduction and Univariate non-graphical EDA | Mathematics for IIT JAM
,shortcuts and tricks
,GATE
,GATE
,Viva Questions
,GATE
,Sample Paper
,UGC NET
,Extra Questions
,practice quizzes
,CSIR NET
,Summary
,Objective type Questions
,ppt
,mock tests for examination
,CSIR NET
,UGC NET
,Exploratory data analysis:Introduction and Univariate non-graphical EDA | Mathematics for IIT JAM
,Exam
,UGC NET
,Important questions
,Semester Notes
,MCQs
,Previous Year Questions with Solutions
,video lectures
,CSIR NET
,Free
,past year papers
,study material
;


Exploratory data analysis:Introduction and Univariate non-graphical EDA Free PDF Download
Importance of Exploratory data analysis:Introduction and Univariate non-graphical EDA
Exploratory data analysis:Introduction and Univariate non-graphical EDA Notes
Exploratory data analysis:Introduction and Univariate non-graphical EDA Mathematics Questions
Study Exploratory data analysis:Introduction and Univariate non-graphical EDA on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!