Metrics | Computer Networks - Computer Science Engineering (CSE) PDF Download

Metrics
The preceding discussion assumes that link costs, or metrics, are known when we execute the routing algorithm. In this section, we look at some ways to calculate link costs that have proven effective in practice. One example that we have seen already, which is quite reasonable and very simple, is to assign a cost of 1 to all links—the least-cost route will then be the one with the fewest hops. Such an approach has several drawbacks, however. First, it does not distinguish between links on a latency basis. Thus, a satellite link with 250-ms latency looks just as attractive to the routing protocol as a terrestrial link with 1-ms latency. Second, it does not distinguish between routes on a capacity basis, making a 9.6-Kbps link look just as good as a 45-Mbps link. Finally, it does not distinguish between links based on their current load, making it impossible to route around overloaded links. It turns out that this last problem is the hardest because you are trying to capture the complex and dynamic characteristics of a link in a single scalar cost.
The ARPANET was the testing ground for a number of different approaches to link-cost calculation. (It was also the place where the superior stability of link-state over distance-vector routing was demonstrated; the original mechanism used distance vector while the later version used link state.) The following discussion traces the evolution of the ARPANET routing metric and, in so doing, explores the subtle aspects of the problem.
The original ARPANET routing metric measured the number of packets that were queued waiting to be transmitted on each link, meaning that a link with 10 packets queued waiting to be transmitted was assigned a larger cost weight than a link with 5 packets queued for transmission. Using queue length as a routing metric did not work well, however, since queue length is an artificial measure of load—it moves packets toward the shortest queue rather than toward the destination, a situation all too familiar to those of us who hop from line to line at the grocery store. Stated more precisely, the original ARPANET routing mechanism suffered from the fact that it did not take either the bandwidth or the latency of the link into consideration.
A second version of the ARPANET routing algorithm, sometimes called the “new routing mechanism,” took both link bandwidth and latency into consideration and used delay, rather than just queue length, as a measure of load. This was done as follows. First, each incoming packet was timestamped with its time of arrival at the router (ArrivalTime); its departure time from the router (DepartTime) was also recorded. Second, when the link-level ACK was received from the other side, the node computed the delay for that packet as
Delay = (DepartTime− ArrivalTime) +TransmissionTime +Latency
where TransmissionTime and Latency were statically defined for the link and captured the link’s bandwidth and latency, respectively. Notice that in this case, DepartTime − ArrivalTime represents the amount of time the packet was delayed (queued) in the node due to load. If the ACK did not arrive, but instead the packet timed out, then DepartTime was reset to the time the packet was retransmitted. In this case, DepartTime − ArrivalTime captures the reliability of the link—the more frequent the retransmission of packets, the less reliable the link, and the more we want to avoid it. Finally, the weight assigned to each link was derived from the average delay experienced by the packets recently sent over that link.
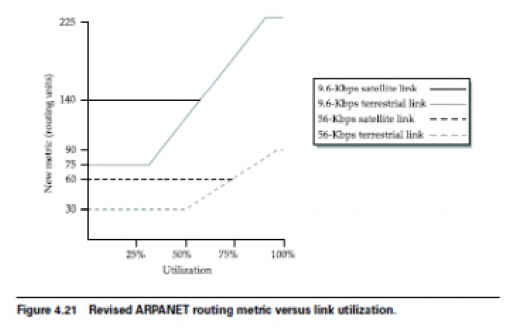
- A highly loaded link never shows a cost of more than three times its cost when idle;
- The most expensive link is only seven times the cost of the least expensive;
- A high-speed satellite link is more attractive than a low-speed terrestrial link;
- Cost is a function of link utilization only at moderate to high loads.
|
21 videos|145 docs|66 tests
|
FAQs on Metrics - Computer Networks - Computer Science Engineering (CSE)
| 1. What are metrics in marketing? |  |
| 2. Why are metrics important in marketing? | |
| 3. What are some key metrics to measure marketing performance? | |
| 4. How can businesses use metrics to improve their marketing strategies? | |
| 5. How can metrics help businesses measure the success of their marketing campaigns? | |



Free
,past year papers
,Metrics | Computer Networks - Computer Science Engineering (CSE)
,Metrics | Computer Networks - Computer Science Engineering (CSE)
,study material
,shortcuts and tricks
,Exam
,Semester Notes
,mock tests for examination
,Important questions
,Viva Questions
,video lectures
,Summary
,Sample Paper
,ppt
,practice quizzes
,Metrics | Computer Networks - Computer Science Engineering (CSE)
,MCQs
,Previous Year Questions with Solutions
,Objective type Questions
,Extra Questions
;






Metrics Free PDF Download
Importance of Metrics
Metrics Notes
Metrics Computer Science Engineering (CSE) Questions
Study Metrics on the App
|
© EduRev
|
Education Revolution
|



|





