Multivariate graphical EDA - Statistics, CSIR-NET Mathematical Sciences | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

4.5 Multivariate graphical EDA
There are few useful techniques for graphical EDA of two categorical random variables. The only one used commonly is a grouped barplot with each group representing one level of one of the variables and each bar within a group representing the levels of the other variable.
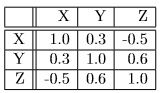
Table 4.6: A Correlation Matrix
4.5.1 Univariate graphs by category
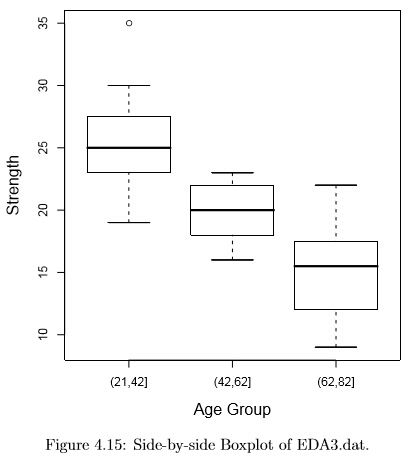
When we have one categorical (usually explanatory) and one quantitative (usually outcome) variable, graphical EDA usually takes the form of “conditioning” on the categorical random variable. This simply indicates that we focus on all of the subjects with a particular level of the categorical random variable, then make plots of the quantitative variable for those subjects. We repeat this for each level of the categorical variable, then compare the plots. The most commonly used of these are side-by-side boxplots, as in figure 4.15. Here we see the data from EDA3.dat, which consists of strength data for each of three age groups. You can see the downward trend in the median as the ages increase. The spreads (IQRs) are similar for the three groups. And all three groups are roughly symmetrical with one high strength outlier in the youngest age group.
Side-by-side boxplots are the best graphical EDA technique for examining the relationship between a categorical variable and a quantitative variable, as well as the distribution of the quantitative variable at each level of the categorical variable. |
4.5.2 Scatterplots
For two quantitative variables, the basic graphical EDA technique is the scatterplot which has one variable on the x-axis, one on the y-axis and a point for each case in your dataset. If one variable is explanatory and the other is outcome, it is a very, very strong convention to put the outcome on the y (vertical) axis.
One or two additional categorical variables can be accommodated on the scatterplot by encoding the additional information in the symbol type and/or color.
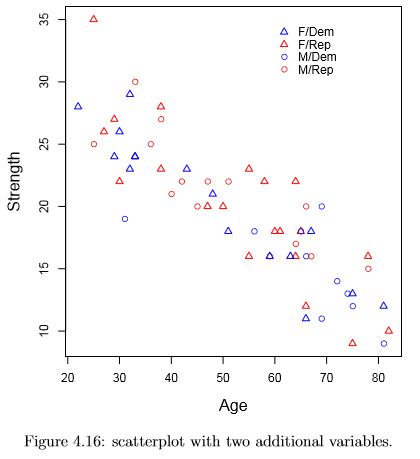
An example is shown in figure 4.16. Age vs. strength is shown, and different colors and symbols are used to code political party and gender.
In a nutshell: You should always perform appropriate EDA before further analysis of your data. Perform whatever steps are necessary to become more familiar with your data, check for obvious mistakes, learn about variable distributions, and learn about relationships between variables. EDA is not an exact science – it is a very important art! |
4.6 A note on degrees of freedom
Degrees of freedom are numbers that characterize specific distributions in a family of distributions. Often we find that a certain family of distributions is needed in a some general situation, and then we need to calculate the degrees of freedom to know which specific distribution within the family is appropriate.
The most common situation is when we have a particular statistic and want to know its sampling distribution. If the sampling distribution falls in the “t” family as when performing a t-test, or in the “F” family when performing an ANOVA, or in several other families, we need to find the number of degrees of freedom to figure out which particular member of the family actually represents the desired sampling distribution. One way to think about degrees of freedom for a statistic is that they represent the number of independent pieces of information that go into the calculation of the statistic,
Consider 5 numbers with a mean of 10. To calculate the variance of these numbers we need to sum the squared deviations (from the mean). It really doesn’t matter whether the mean is 10 or any other number: as long as all five deviations are the same, the variance will be the same. This make sense because variance is a pure measure of spread, not affected by central tendency. But by mathematically rearranging the definition of mean, it is not too hard to show that the sum of the deviations (not squared) is always zero. Therefore, the first four deviations can (freely) be any numbers, but then the last one is forced to be the number that makes the deviations add to zero, and we are not free to choose it. It is in this sense that five numbers used for calculating a variance or standard deviation have only four degrees of freedom (or independent useful pieces of information). In general, a variance or standard deviation calculated from n data values and one mean has n−1 df.
Another example is the “pooled” variance from k independent groups. If the sizes of the groups are n1 through nk, then each of the k individual variance estimates is based on deviations from a different mean, and each has one less degree of freedom than its sample size, e.g., ni −1 for group i. We also say that each numerator of a variance estimate, e.g., SSi, has ni−1 df. The pooled estimate of variance is
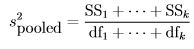
and we say that both the numerator SS and the entire pooled variance has df1+···+ dfk degrees of freedom, which suggests how many independent pieces of information are available for the calculation.
|
556 videos|198 docs
|
FAQs on Multivariate graphical EDA - Statistics, CSIR-NET Mathematical Sciences - Mathematics for IIT JAM, GATE, CSIR NET, UGC NET
| 1. What is multivariate graphical EDA? |  |
| 2. How is multivariate graphical EDA useful in statistics? | |
| 3. What are some commonly used techniques for multivariate graphical EDA? | |
| 4. How does multivariate graphical EDA assist in CSIR-NET Mathematical Sciences exam? | |
| 5. What are the benefits of using multivariate graphical EDA in mathematics research? | |



Extra Questions
,past year papers
,Exam
,Semester Notes
,Previous Year Questions with Solutions
,Multivariate graphical EDA - Statistics
,ppt
,UGC NET
,UGC NET
,Free
,CSIR NET
,MCQs
,Multivariate graphical EDA - Statistics
,UGC NET
,CSIR NET
,Objective type Questions
,practice quizzes
,GATE
,GATE
,GATE
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Important questions
,shortcuts and tricks
,Viva Questions
,Sample Paper
,CSIR NET
,Multivariate graphical EDA - Statistics
,study material
,Summary
,mock tests for examination
,video lectures
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
;


Multivariate graphical EDA - Statistics, CSIR-NET Mathematical Sciences Free PDF Download
Importance of Multivariate graphical EDA - Statistics, CSIR-NET Mathematical Sciences
Multivariate graphical EDA - Statistics, CSIR-NET Mathematical Sciences Notes
Multivariate graphical EDA - Statistics, CSIR-NET Mathematical Sciences Mathematics Questions
Study Multivariate graphical EDA - Statistics, CSIR-NET Mathematical Sciences on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!