Operator: Precedence Parsing | Compiler Design - Computer Science Engineering (CSE) PDF Download

3. OPERATOR : PRECEDENCE PARSING:
Precedence/ Operator grammar: The grammars having the property:
1. No production right side is should contain ∈
2. No production sight side should contain two adjacent non-terminals.
Is called an operator grammar.
Operator – precedence parsing has three disjoint precedence relations, <.,=and .> between certain pairs of terminals. These precedence relations guide the selection of handles and have the following
meanings:
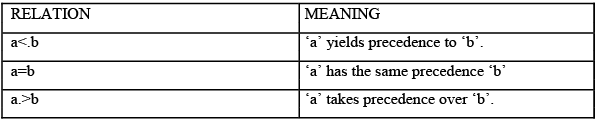
Operator precedence parsing has a number of disadvantages:
1. It is hard to handle tokens like the minus sign, which has two different precedences.
2. Only a small class of grammars can be parsed.
3. The relationship between a grammar for the language being parsed and the operatorprecedence parser itself is tenuous, one cannot always be sure the parser accepts exactly the desired language.
Disadvantages:
1. L(G) ¹L(parser)
2. error detection
3. usage is limited
4. They are easy to analyse manually
Example:
Grammar: E→EAE|(E)|-E/id
A →+|-|*|/|
Input string: id+id*id
The operator – precedence relations are: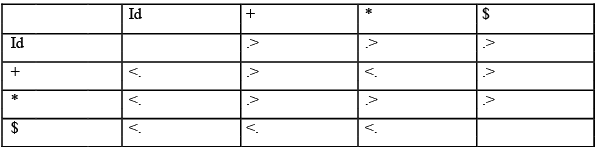
Solution:
This is not operator grammar, so first reduce it to operator grammar form,
by eliminating adjacent non-terminals.
Operator grammar is: E→E+E|E-E|E*E|E/E|EE|(E)|-E| id
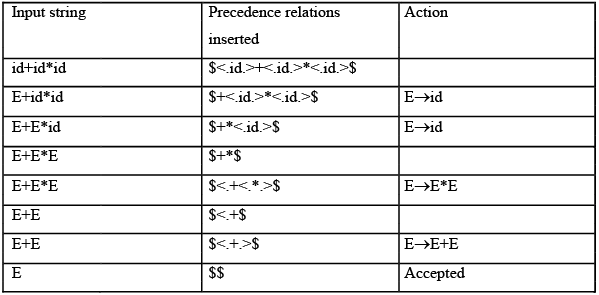
The input string with precedence relations interested is:
$<.id.> + <.id.> * <.id.> $
Scan the string the from left end until first .> is encounted.
$<.id.>+<.id.>*<.id.<$
This occurs between the first id and +.
Scan backwards (to the left) over any =’s until a <. Is encounted. We scan backwards to $.
$<.id.>+<.id.>*<.id.>$
Everything to the left of the first .> and to the right of <. Is called handle. Here, the handle is the first
id.
Then reduce id to E. At this point we have: E+id*id
By repeating the process and proceding in the same way: $+<.id.>*<.id.>$
substitute E→id,
After reducing the other id to E by the same process, we obtain the right-sentential form
E+E*E
Now, the 1/p string afte detecting the non-terminals sis:
⇒ $+*$
Inserting the precedence relations, we get: $<.+<.*.>$
The left end of the handle lies between + and * and the right end between * and $. It indicates that, in the right sentential form E+E*E, the handle is E*E.
Reducing by E→E*E, we get:
E+E
Now the input string is: $<.+$
Again inserting the precedence relations, we get:
⇒$<.+.>$
reducing by E→E+E, we get,
$ $
and finally we are left with:
E
Hence accepted.
|
26 videos|83 docs|30 tests
|
FAQs on Operator: Precedence Parsing - Compiler Design - Computer Science Engineering (CSE)
| 1. What is precedence parsing in computer science engineering? |  |
| 2. How does precedence parsing work? | |
| 3. What is the purpose of precedence parsing in computer science engineering? | |
| 4. Are there any limitations to precedence parsing? | |
| 5. What are some applications of precedence parsing in computer science engineering? | |



Viva Questions
,Operator: Precedence Parsing | Compiler Design - Computer Science Engineering (CSE)
,video lectures
,study material
,MCQs
,Sample Paper
,Operator: Precedence Parsing | Compiler Design - Computer Science Engineering (CSE)
,Exam
,shortcuts and tricks
,Semester Notes
,mock tests for examination
,Summary
,Important questions
,Free
,Objective type Questions
,past year papers
,Previous Year Questions with Solutions
,Extra Questions
,ppt
,Operator: Precedence Parsing | Compiler Design - Computer Science Engineering (CSE)
,practice quizzes
;






Operator: Precedence Parsing Free PDF Download
Importance of Operator: Precedence Parsing
Operator: Precedence Parsing Notes
Operator: Precedence Parsing Computer Science Engineering (CSE) Questions
Study Operator: Precedence Parsing on the App
|
© EduRev
|
Education Revolution
|



|





