Principal component analysis and Factor Analysis, CSIR-NET Mathematical Sciences | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

1. Introduction
Data reduction techniques are applied where the goal is to aggregate or amalgamate the information contained in large data sets into manageable (smaller) information nuggets. Data reduction techniques can include simple tabulation, aggregation (computing descriptive statistics) or more sophisticated techniques like principal components analysis, factor analysis. Here, mainly principal component analysis (PCA) and factor analysis are covered along with examples and software demonstration. Different commands used in SPSS and SAS packages for PCA and factor analyses are also given.
2. Principal Component Analysis
Often, the variables under study are highly correlated and as such they are effectively “saying the same thing”. It may be useful to transform the original set of variables to a new set of uncorrelated variables called principal components. These new variables are linear combinations of original variables and are derived in decreasing order of importance so that the first principal component accounts for as much as possible of the variation in the original data. Also, PCA is a linear dimensionality reduction technique, which identifies orthogonal directions of maximum variance in the original data, and projects the data into a lower-dimensionality space formed of a sub set of the highest variance components.
Let x1, x2, x3,...,xp are variables under study, then first principal component may be defined as
z1 = a11 x1 + a12 x2 + ...... + a1p xp
such that variance of z1 is as large as possible subject to the condition that
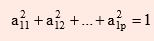
This constraint is introduced because if this is not done, then Var(z1) can be increased simply by multiplying any a1js by a constant factor. The second principal component is defined as
z2 = a21 x1 + a22 x2 + ....... + a2p xp
such that Var(z2) is as large as possible next to Var( z1) subject to the constraint that
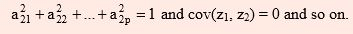
It is quite likely that first few principal components account for most of the variability in the original data. If so, these few principal components can then replace the initial p variables in subsequent analysis, thus, reducing the effective dimensionality of the problem. An analysis of principal components often reveals relationships that were not previously suspected and thereby allows interpretation that would not ordinarily result. However, Principal Component Analysis is more of a means to an end rather than an end in itself because this frequently serves as intermediate steps in much larger investigations by reducing the dimensionality of the problem and providing easier interpretation. It is a mathematical technique, which does not require user to specify the statistical model or assumption about distribution of original variates. It may also be mentioned that principal components are artificial variables and often it is not possible to assign physical meaning to them. Further, since Principal Component Analysis transforms original set of variables to new set of uncorrelated variables, it is worth stressing that if original variables are uncorrelated, then there is no point in carrying out principal component analysis.
Computation of Principal Components and Scores
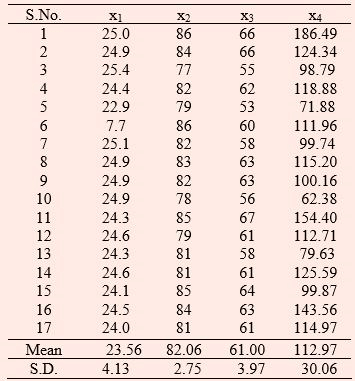
Consider the following data on average minimum temperature (x1), average relative humidity at 8 hrs. (x2), average relative humidity at 14 hrs. (x3) and total rainfall in cm. (x4) pertaining to Raipur district from 1970 to 1986 for kharif season from 21st May to 7th Oct.
The variance-covariance matrix is as follows:

The eigen values 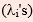 and eigen vectors (ai) of the above matrix is obtained and is given as follows in decreasing order alongwith the corresponding eigen vectors:
and eigen vectors (ai) of the above matrix is obtained and is given as follows in decreasing order alongwith the corresponding eigen vectors:
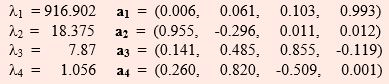
The principal components for this data will be
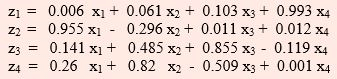
The variance of principal components will be eigen values i.e.
Var(z1) = 916.902, Var(z2) =18.375, Var (z3) = 7.87, Var(z4) = 1.056
The total variation explained by original variables is
Var(x1) + Var(x2) + Var(x3) + Var(x4)
= 17.02 + 7.56 + 15.75 + 903.87 = 944.20
The total variation explained by principal components is
λ1 + λ2 + λ3 + λ4 = 916.902 + 18.375 + 7.87 + 1.056 = 944.20
As such, it can be seen that the total variation explained by principal components is same as that explained by original variables. It could also be proved mathematically as well as empirically that the principal components are uncorrelated. The proportion of total variation accounted for by the first principal component is
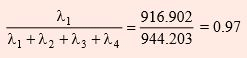
Continuing, the first two components account for a proportion
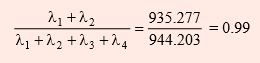
of the total variance.
Hence, in further analysis, the first or first two principal components z1 and z2 could replace four variables by sacrificing negligible information about the total variation in the system. The scores of principal components can be obtained by substituting the values of xi’s in equations of zi’s. For above data, the first two principal components for first observation i.e. for year 1970 can be worked out as
z1 = 0.006 x 25.0 + 0.061 x 86 + 0.103 x 66 + 0.993 x 186.49 = 197.380
z2 = 0.955 x 25.0 - 0.296 x 86 + 0.011 x 66 + 0.012 x 186.49 = 1.383
Similarly for the year 1971
z1 = 0.006 x 24.9 + 0.061 x 84 + 0.103 x 66 + 0.993 x 124.34 = 135.54
z2 = 0.955 x 24.9 - 0.296 x 84 + 0.011 x 66 + 0.012 x 124.34 = 1.134
Thus the whole data with four variables can be converted to a new data set with two principal components.
Note: The principal components depend on the unit of measurement, for example, if in the above example x1 is measured in 0F instead of 0C and x4 in mm in place of cm, the data gives different principal components when transformed to original x’s. In very specific situations the results are same. The conventional way of getting around this problem is to use standardized variables with unit variances, i.e., correlation matrix in place of dispersion matrix. But the principal components obtained from original variables as such and from correlation matrix will not be same and they may not explain the same proportion of variance in the system. Further more, one set of principal components is not simple function of the other. When the variables are standardized, the resulting variables contribute almost equally to the principal components determined from correlation matrix. Variables should probably be standardized if they are measured in units with widely differing ranges or if measured units are not commensurate. Often population dispersion matrix or correlation matrix is not available. In such situations, sample dispersion matrix or correlation matrix can be used.
Applications of Principal Components
- The most important use of principal component analysis is reduction of data. It provides the effective dimensionality of the data. If first few components account for most of the variation in the original data, then first few components’ scores can be utilized in subsequent analysis in place of original variables.
- Plotting of data becomes difficult with more than three variables. Through principal component analysis, it is often possible to account for most of the variability in the data by first two components, and it is possible to plot the values of first two components scores for each individual. Thus, principal component analysis enables us to plot the data in two dimensions. Particularly detection of outliers or clustering of individuals will be easier through this technique. Often, use of principal component analysis reveals grouping of variables which would not be found by other means.
- Reduction in dimensionality can also help in analysis where number of variables is more than the number of observations, for example, in discriminant analysis and regression analysis. In such cases, principal component analysis is helpful by reducing the dimensionality of data.
- Multiple regression can be dangerous if independent variables are highly correlated. Principal component analysis is the most practical technique to solve the problem. Regression analysis can be carried out using principal components as regressors in place of original variables. This is known as principal component regression
SPSS Syntax for Principal Component Analysis
matrix.
read x
/file='c:\princomp.dat'
/field=1 to 80
/size={17,4}.
compute x1=sscp(x).
compute x2=csum(x).
compute x3=nrow(x).
compute x4=x2/x3.
compute x5=t(x4)*x4.
compute x6=(x1-(x3*x5))/16.
call eigen(x6,a, λ ).
compute P=x*a. print x.
print x1.
print x2.
print x3.
print x4.
print x5.
print x6.
print a.
print λ.
print P.
end matrix.
OUTPUT from SPSS
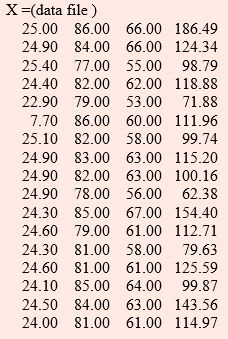
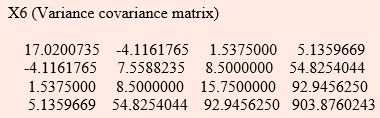


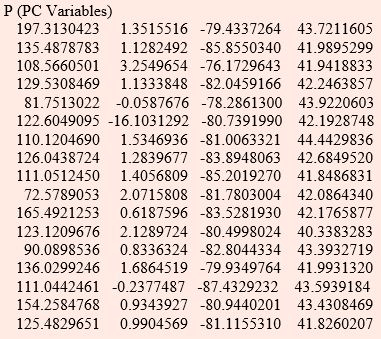
SAS Commands for Principal Components Analysis
data test;
input x1 x2 x3 x4;
cards;
:
.
;
proc princomp cov;
var x1 x2 x3 x4;
run;
2. FACTOR ANALYSIS The essential purpose of factor analysis is to describe, if possible, the covariance relationships among many variables in terms of a few underlying, but unobservable, random quantities called factors. Under the factor model assuming linearity, each response variate is represented as a linear function of a small number of unobservable common factors and a single latent specific factor. The common factors generate the covariances among the observable responses while the specific terms contribute only to the variances of their particular response. Basically the factor model is motivated by the following argument - Suppose variables can be grouped by their correlations, i.e., all variables within a particular group are highly correlated among themselves but have relatively small correlations with variables in a different group. It is conceivable that each group of variables represents a single underlying construct, or factor, that is responsible for the observed correlations. For example, for an individual, marks in different subjects may be governed by aptitudes (common factors) and individual variations (specific factors) and interest may lie in obtaining scores on unobservable aptitudes (common factors) from observable data on marks in different subjects.
The Factor Model Suppose observations are made on p variables, x1, x2,…,xp. The factor analysis model assumes that there are m underlying factors (m<p) f1, f2,…,fm and each observed variables is a linear function of these factors together with a residual variate, so that
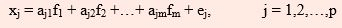
where aj1, aj2,…,ajm are called factor loadings i.e. ajk is loading of jth variable on kth factor. ej 's are called specific factors.
The proportion of the variance of the jth variable contributed by the m common factors is called the jth communality and the proportion due to the specific factors is called the uniqueness, or specific variance.
Factor analysis involves:
- Deciding number of common factors (m)
- Estimating factor loadings (aji)
- Calculating factor scores (fi)
Methods of Estimation
Factor analysis is done in two parts, first solution is obtained by placing some restrictions and then final solution is obtained by rotating this solution. There are two most popular methods available in literature for parameter estimation, the principal component (and the related principal factor) method and the maximum likelihood method. The solution from either method can be rotated in order to simplify the interpretation of factors i.e. either factor loadings are close to unity or close to zero. The most popular method for orthogonal rotation is Varimax Rotation Method. In some specific situations, oblique rotations are also used. It is always prudent to try more than one method of solution. If the factor model is appropriate for the problem at hand, the solutions should be consistent with one another. The estimation and rotation methods require iterative calculations that must be done on a computer. If variables are uncorrelated factor analysis will not be useful. In these circumstances, the specific factors play the dominant role, whereas the major aim of the factor analysis is to determine a few important common factors.
Number of factors is theoretically given by rank of population variance-covariance matrix. However, in practice, number of common factors retained in the model is increased until a suitable proportion of total variance is explained. Another convention, frequently encountered in computer packages is to set m equal to the number of eigen values greater than one.
As in principal component analysis, principal factor method for factor analysis depends upon unit of measurement. If units are changed, the solution will change. However, in this approach estimated factor loadings for a given factor do not change as the number of factors is increased. In contrast to this, in maximum likelihood method, the solution does not change if units of measurements are changed. However, in this method the solution changes if number of common factors is changed.
Example 2.1: In a consumer - preference study, a random sample of customers were asked to rate several attributes of a new product. The response on a 5-point semantic differential scale were tabulated and the attribute correlation matrix constructed is as given below:
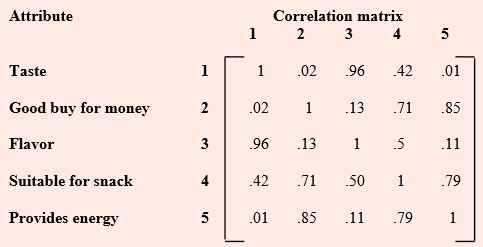
It is clear from the correlation matrix that variables 1 and 3 and variables 2 and 5 form groups. Variable 4 is closer to the (2,5) group than (1,3) group. Observing the results, one can expect that the apparent linear relationships between the variables can be explained in terms of, at most, two or three common factors.
Solution from SAS package.
Initial Factor Method: Principal Components
Prior Communality Estimates: ONE
Eigenvalues of the Correlation Matrix: Total = 5 Average = 1
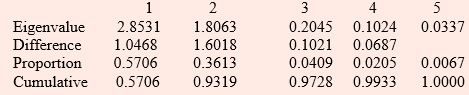

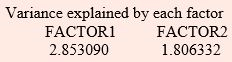

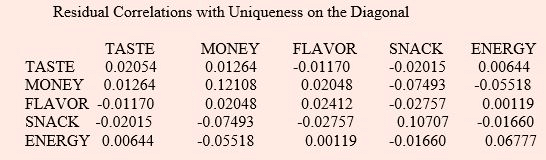


Initial Factor Method: Maximum Likelihood
Eigenvalues of the Weighted Reduced Correlation Matrix:
Total = 84.5563187
Average = 16.9112637


Variance explained by each factor
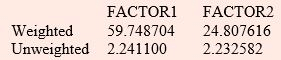
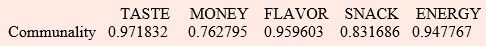
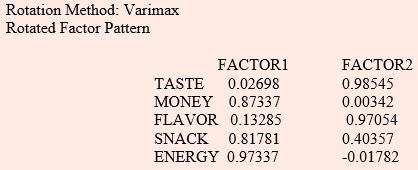
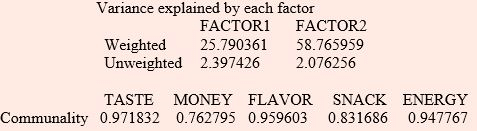
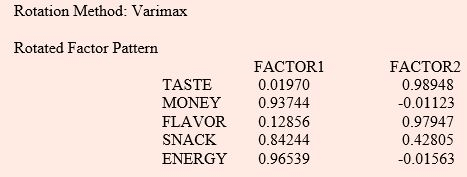
It can be seen that two factor model with factor loadings shown above is providing a good fit to the data as the first two factors explains 93.2% of the total standardized sample
variance, i.e., 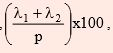 where p is the number of variables. It can also be seen from the results that there is no clear-cut distinction between factor loadings for the two factors before rotation.
where p is the number of variables. It can also be seen from the results that there is no clear-cut distinction between factor loadings for the two factors before rotation.
SAS Commands for Factor Analysis
title ‘Factor Analysis’;
data consumer (type=corr);
_type_=’CORR’;
Input name$ taste money flavour snack energy;

method = prin nfact=2 rotate = varimax preplot plot;
var taste money flavour snack energy;
run;
SPSS Steps for Factor Analysis
File → New → Data → Define Variables → Statistics → Data reduction → Factor → Variables (mark variables and click ‘4’ to enter variables in the box) → Descriptives → Statistics ( univariate descriptives ,initial solution) → Corrlation matrix ( coefficients) → Extraction → Method (principal components or maximum likelihood) → Extract (Number of factors as 2) → Display (Unrotated factor solution) → Continue → Rotation → Method (varimax) → Display (loading plots) → Continue → Scores → Display factor score coefficient matrix → Continue → OK.
univariate descriptives ,initial solution) → Corrlation matrix ( coefficients) → Extraction → Method (principal components or maximum likelihood) → Extract (Number of factors as 2) → Display (Unrotated factor solution) → Continue → Rotation → Method (varimax) → Display (loading plots) → Continue → Scores → Display factor score coefficient matrix → Continue → OK.
|
558 videos|198 docs
|
FAQs on Principal component analysis and Factor Analysis, CSIR-NET Mathematical Sciences - Mathematics for IIT JAM, GATE, CSIR NET, UGC NET
| 1. What is the difference between Principal Component Analysis (PCA) and Factor Analysis? |  |
| 2. How does Principal Component Analysis work? | |
| 3. What are the applications of Principal Component Analysis? | |
| 4. When should I use Factor Analysis instead of Principal Component Analysis? | |
| 5. What are the limitations of Principal Component Analysis? | |



practice quizzes
,study material
,GATE
,Summary
,ppt
,past year papers
,Sample Paper
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Principal component analysis and Factor Analysis
,shortcuts and tricks
,MCQs
,video lectures
,CSIR NET
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Exam
,Extra Questions
,CSIR NET
,Objective type Questions
,mock tests for examination
,Principal component analysis and Factor Analysis
,Viva Questions
,CSIR NET
,GATE
,UGC NET
,Free
,UGC NET
,Previous Year Questions with Solutions
,GATE
,Important questions
,Semester Notes
,Principal component analysis and Factor Analysis
,UGC NET
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
;


Principal component analysis and Factor Analysis, CSIR-NET Mathematical Sciences Free PDF Download
Importance of Principal component analysis and Factor Analysis, CSIR-NET Mathematical Sciences
Principal component analysis and Factor Analysis, CSIR-NET Mathematical Sciences Notes
Principal component analysis and Factor Analysis, CSIR-NET Mathematical Sciences Mathematics Questions
Study Principal component analysis and Factor Analysis, CSIR-NET Mathematical Sciences on the App
|
© EduRev
|
Education Revolution
|



|





