Quartiles and Percentiles - Measures of Central Tendency, Business Mathematics & Statistics | SSC CGL Tier 2 - Study Material, Online Tests, Previous Year PDF Download

Quartiles and Percentiles
At this point we can describe the results of an experiment - at least for numeric variables - using the mean (or median) and the standard deviation. That will tell us the "center" of the distribution of values and the "spread" around that center. For example, if we measure the height of US army soldiers we could say that the average height of US soldiers is 1.73 meters, with a standard deviation of 0.15 meters (the numbers are made-up). To describe the distribution in more detail we need additional descriptive measures.
Upper and Lower Quartiles
- The Lower Quartile Q1 is that number such that 25% of observations are less than it and 75% are larger, or to be more precise, at least 25% of the sorted values are less than or equal to Q1and at least 75% of the values are greater than or equal to Q1.
- The Upper Quartile Q3 is that number such that 75% of observations are less than it and 25% are larger, or to be more precise, at least 75% of the sorted values are less than or equal to Q3, and at least 25% of the values are greater than or equal to Q3.
Following this notation, the median should actually be called the "middle quartile" Q2, since it is that number such that 50% are less than it and 50% are larger.
NOTE: To find the quartiles, you must first sort your data (similar to finding the mean).
Example: Compute the upper and lower quartiles of the numbers 1, 2, 3, 4, 5, 6, 7.
The numbers are already sorted, so that it is easy to see that the median is 4 (three numbers are less than 4 and three are bigger). In other words, 4 splits our numbers up into the smaller set {1, 2, 3} and the larger set {5, 6, 7}. The quartiles, in turn, split up these sets in the middle, so that Q1 = 2 and Q3 = 6.
Note that the numbers 1, 2 are less than or equal to the lower quartile, while 2, 3, 4, 5, 6, 7 are larger than or equal to Q1. Therefore, 2 out of 7 or 28% of values are less than or equal to Q1 and 6 out of 7 = 85% are larger than Q1.
Example: Compute the upper and lower quartiles of the numbers 1, 2, 3, 4, 5.
Now the median is 3, leaving two sets {1, 2} and {4, 5}. To split these numbers in the middle does not work, so it is not immediately clear what the quartiles are.
- If Q1= 1, then one value out of 5 is less than or equal to Q1, or 20%. That's not correct, so Q1 must be bigger than 1.
- If Q1 = 2, then two values out of 5 are less than or equal to Q1, or 40%. Similarly, 4 values out of 5 , or 80%, are larger than or equal to Q1 so that the lower quartile is 2.
Similarly, the upper quartile can be shown to be 4.
For larger data sets, the quartiles can be selected as follows:
For Lower Quartile;
- Sort all observations in ascending order
- Compute the position L1 = 0.25 * N, where N is the total number of observations.
- If L1 is a whole number, the lower quartile is midway between the L1-th value and the next one.
- If L1 is not a whole number, change it by rounding up to the nearest integer. The value at that position is the lower quartile.
For Upper Quartile;
- Sort all observations in ascending order
- Compute the position L3 = 0.75 * N, where N is the total number of observations.
- If L3 is a whole number, the lower quartile is midway between the L3-th value and the next one.
- If L3 is not a whole number, change it by rounding up to the nearest integer. The value at that position is the lower quartile.
Examples: Find the quartiles for the values 1, 2, 3, 4, 5, 6, 7 and also for the values 1, 2, 3, 4, 5 using this new method.
For the set 1, 2, 3, 4, 5, 6, 7 we have N = 7. Thus:
- L1 = 0.25 * 7 = 1.75, which gets rounded up to 2. Thus, I take the number in the 2nd position to be the lower quartile
- L3 = 0.75 * 7 = 5.25, which gets rounded up to 6. Thus, I take the 6th number (i.e. 6) to be the upper quartile.
For the set 1, 2, 3, 4, 5 we have N = 5. Thus:
- L1 = 0.25 * 5 = 1.25, which gets rounded up to 2. Thus, I again take the number in the 2nd position to be the lower quartile
- L3 = 0.75 * 5 = 3.75, which gets rounded up to 4. Thus, I take the 4th number (i.e. 4) to be the upper quartile.
Percentiles
Quartiles are useful and they help to describe the distribution of values as we will see later. However, we often want to know how one particular data value compares to the rest of the data. For example, when taking standardized test scores such as SAT scores, I want to know not only my own score, but also how my score ranks in relation to all scores. Percentiles are perfect for this situation.
The K-th Percentile is that number such that K % of all data values are less and (100 - K) % are larger than it, or to be more precise, at least K% of the sorted values are less than or equal to it and at least (100 - K) % of the values are greater than or equal to it.
Note: The lower quartile is the same as the 25th percentile, the median is the same as the 50th percentile, and the upper quartile is the same as the 75th percentile.
To find the K-th Percentile:
- Sort all observations in ascending order
- Compute the position L = (K/100) * N, where N is the total number of observations.
- If L is a whole number, the K-th percentile is the value midway between the L-th value and the next one.
- If L is not a whole number, change it by rounding up to the nearest integer. The value at that position is the K-th percentile.
Example: Consider the following cotinine levels of 40 smokers:
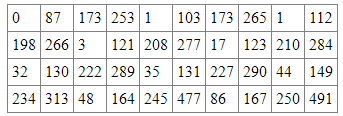
Find the quartiles and the 40th percentile.
First note that before we start our computations we must sort the data - computing percentiles for non-sorted data is the most common mistake (so please avoid it). Here is the same data again, this time sorted:
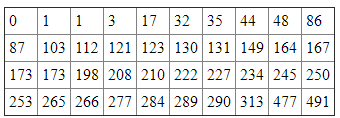
Now we can do our calculations, where N = 40 (number of values in our data set).
- Lower Quartile: 0.25 * 40 = 10, so we need to take the value midway between the 10th value, which is 86, and the 11th value, which is 87. Hence, the lower quartile is 86.5
- Upper Quartile: 0.75 * 40 = 30, so we need to take the value midway between the 30th value, which is 250, and the 31st value, which is 253. Hence, the upper quartile is (250 + 253) / 2 = 251.5
- 40th Percentile: 0.4 * 40 = 16, so the 40th percentile is (130 + 131) / 2 = 130.5
But for percentiles another question is usually asked: given a particular value, find that percentile that corresponds to this value. In other words, determine how many values are less and how many values are larger than the particular value.
To find the percentile that corresponds to a particular data value x is:
- percentile value of x = (number of values less than x) / (total number of values) * 100
Example: Suppose you took part in the above study of cotinine levels, and your personal continine level was 245. What is the percentile value of 245, and how many people in the study had a higher cotinine level that you?
First note that in our sorted data the value 245 is in 29th position (I must use the sorted data, of course). Therefore, according to our formula:
- percentile value of 245 = 29/40 * 100 = 72.5
Thus, by definition of percentiles, 72.5% of values are less than245, while (100 - 72.5) = 27.5% are larger than 245.
Using Excel to find Percentiles
Of course Excel can be used to find percentiles, and therefore upper and lower quartiles (which are just the 25th and 75th percentile, respectively).
The Excel function to compute percentiles is "= percentile(RANGE, K)", where RANGE is a range of cells and K is the percentile to compute as a decimal number between 0 and 1. The data does not have to be sorted, Excel can handle it automatically.
The Excel function to compute the rank of a value x in a data set as a percentage of the data set (in other words, the percentile value of x) is "=percentrank(RANGE, X)". The data does not have to be sorted, Excel can handle it automatically.
For example, the function "=percentile(A1:A10, 0.40)" computes the 40th percentile of the values in the cells A1 to A10.
|
1335 videos|1432 docs|834 tests
|
FAQs on Quartiles and Percentiles - Measures of Central Tendency, Business Mathematics & Statistics - SSC CGL Tier 2 - Study Material, Online Tests, Previous Year
| 1. What are quartiles and how are they calculated? |  |
| 2. How do quartiles help in analyzing data? | |
| 3. What is the significance of percentiles in statistics? | |
| 4. How are percentiles calculated? | |
| 5. Can quartiles and percentiles be used interchangeably? | |



Objective type Questions
,mock tests for examination
,Business Mathematics & Statistics | SSC CGL Tier 2 - Study Material
,Online Tests
,Online Tests
,Previous Year
,Business Mathematics & Statistics | SSC CGL Tier 2 - Study Material
,past year papers
,study material
,video lectures
,MCQs
,Previous Year
,Business Mathematics & Statistics | SSC CGL Tier 2 - Study Material
,shortcuts and tricks
,Important questions
,Quartiles and Percentiles - Measures of Central Tendency
,Sample Paper
,Extra Questions
,practice quizzes
,Online Tests
,Quartiles and Percentiles - Measures of Central Tendency
,Exam
,Viva Questions
,Summary
,Semester Notes
,Previous Year
,Previous Year Questions with Solutions
,ppt
,Free
,Quartiles and Percentiles - Measures of Central Tendency
;






Quartiles and Percentiles - Measures of Central Tendency, Business Mathematics & Statistics Free PDF Download
Importance of Quartiles and Percentiles - Measures of Central Tendency, Business Mathematics & Statistics
Quartiles and Percentiles - Measures of Central Tendency, Business Mathematics & Statistics Notes
Quartiles and Percentiles - Measures of Central Tendency, Business Mathematics & Statistics SSC CGL Questions
Study Quartiles and Percentiles - Measures of Central Tendency, Business Mathematics & Statistics on the App
|
© EduRev
|
Education Revolution
|



|





