Rank correlation, CSIR-NET Mathematical Sciences | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

In statistics, Spearman's rank correlation coefficient or Spearman's rho, named after Charles Spearman and often denoted by the Greek letter ρ (rho) or as rs, is a nonparametric measure of rank correlation (statistical dependence between the rankings of two variables). It assesses how well the relationship between two variables can be described using a monotonicfunction.
The Spearman correlation between two variables is equal to the Pearson correlation between the rank values of those two variables; while Pearson's correlation assesses linear relationships, Spearman's correlation assesses monotonic relationships (whether linear or not). If there are no repeated data values, a perfect Spearman correlation of +1 or −1 occurs when each of the variables is a perfect monotone function of the other.
Intuitively, the Spearman correlation between two variables will be high when observations have a similar (or identical for a correlation of 1) rank (i.e. relative position label of the observations within the variable: 1st, 2nd, 3rd, etc.) between the two variables, and low when observations have a dissimilar (or fully opposed for a correlation of −1) rank between the two variables.
Spearman's coefficient is appropriate for both continuous and discrete ordinal variables.[1][2] Both Spearman's ρand Kendall's τ can be formulated as special cases of a more general correlation coefficient.
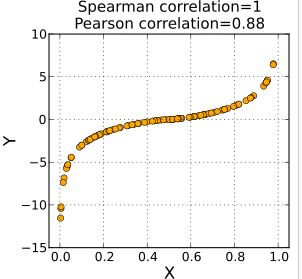
A Spearman correlation of 1 results when the two variables being compared are monotonically related, even if their relationship is not linear. This means that all data-points with greater x-values than that of a given data-point will have greater y-values as well. In contrast, this does not give a perfect Pearson correlation.
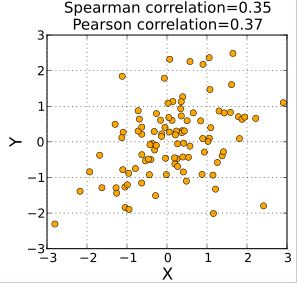
When the data are roughly elliptically distributed and there are no prominent outliers, the Spearman correlation and Pearson correlation give similar values.
Definition and calculation
The Spearman correlation coefficient is defined as the Pearson correlation coefficient between the ranked variables.[3]
For a sample of size n, the n raw scores Xi, Yi are converted to ranks rgXi, rgYi, and rs is computed from:
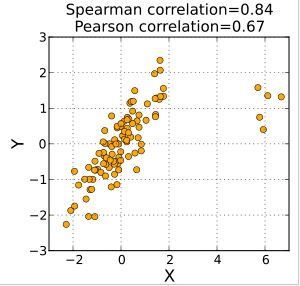
The Spearman correlation is less sensitive than the Pearson correlation to strong outliers that are in the tails of both samples. That is because Spearman's rho limits the outlier to the value of its rank.
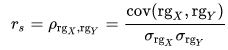 where
where
ρ denotes the usual Pearson correlation coefficient, but applied to the rank variables.
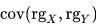 is the covariance of the rank variables.
is the covariance of the rank variables.σrgx and σrgy are the standard deviations of the rank variables.
Only if all n ranks are distinct integers, it can be computed using the popular formula
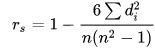 where
where
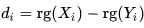 , is the difference between the two ranks of each observation.
, is the difference between the two ranks of each observation.n is the number of observations
Identical values are usually[4] each assigned fractional ranks equal to the average of their positions in the ascending order of the values, which is equivalent to averaging over all possible permutations.
If ties are present in the data set, the simplified formula above yields incorrect results: Only if in both variables all ranks are distinct, then 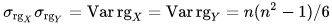 (cf. tetrahedral number Tn-1. The first equation—normalizing by the standard deviation—may even be used even when ranks are normalized to [0;1] ("relative ranks") because it is insensitive both to translation and linear scaling.
(cf. tetrahedral number Tn-1. The first equation—normalizing by the standard deviation—may even be used even when ranks are normalized to [0;1] ("relative ranks") because it is insensitive both to translation and linear scaling.
This[which?] method should also not be used in cases where the data set is truncated; that is, when the Spearman correlation coefficient is desired for the top X records (whether by pre-change rank or post-change rank, or both), the user should use the Pearson correlation coefficient formula given above.[citation needed]
The standard error of the coefficient (σ) was determined by Pearson in 1907 and Gosset in 1920. It is
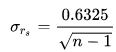
|
558 videos|198 docs
|



study material
,GATE
,GATE
,Rank correlation
,UGC NET
,shortcuts and tricks
,MCQs
,UGC NET
,Objective type Questions
,practice quizzes
,CSIR NET
,Previous Year Questions with Solutions
,Rank correlation
,Summary
,Sample Paper
,Semester Notes
,CSIR NET
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Extra Questions
,past year papers
,Exam
,video lectures
,Viva Questions
,mock tests for examination
,CSIR NET
,Rank correlation
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,ppt
,UGC NET
,GATE
,Important questions
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Free
;


Rank correlation, CSIR-NET Mathematical Sciences Free PDF Download
Importance of Rank correlation, CSIR-NET Mathematical Sciences
Rank correlation, CSIR-NET Mathematical Sciences Notes
Rank correlation, CSIR-NET Mathematical Sciences Mathematics Questions
Study Rank correlation, CSIR-NET Mathematical Sciences on the App
|
© EduRev
|
Education Revolution
|



|





