Real Time Task Scheduling - 1 | Embedded Systems (Web) - Computer Science Engineering (CSE) PDF Download

Real-Time Task Scheduling
In the last Chapter we defined a real-time task as one that has some constraints associated with it. Out of the three broad classes of time constraints we discussed, deadline constraint on tasks is the most common. In all subsequent discussions we therefore implicitly assume only deadline constraints on real-time tasks, unless we mention otherwise. Real-time tasks get generated in response to some events that may either be external or internal to the system. For example, a task might get generated due to an internal event such as a clock interrupt occurring every few milliseconds to periodically poll the temperature of a chemical plant. Another task might get generated due to an external event such as the user pressing a switch. When a task gets generated, it is said to have arrived or got released. Every real-time system usually consists of a number of real-time tasks. The time bounds on different tasks may be different. We had already pointed out that the consequences of a task missing its time bounds may also vary from task to task. This is often expressed as the criticality of a task.
In the last Chapter, we had pointed out that appropriate scheduling of tasks is the basic mechanism adopted by a real-time operating system to meet the time constraints of a task. Therefore, selection of an appropriate task scheduling algorithm is central to the proper functioning of a real-time system. In this Chapter we discuss some fundamental task scheduling techniques that are available. An understanding of these techniques would help us not only to satisfactorily design a real-time application, but also understand and appreciate the features of modern commercial real-time operating systems discussed in later chapters. This chapter is organized as follows. We first introduce some basic concepts and terminologies associated with task scheduling. Subsequently, we discuss two major classes of task schedulers: clock-driven and event-driven. Finally, we explain some important issues that must be considered while developing practical applications.
Basic Terminologies
In this section we introduce a few important concepts and terminologies which would be useful in understanding the rest of this Chapter.
Task Instance: Each time an event occurs, it triggers the task that handles this event to run. In other words, a task is generated when some specific event occurs. Real-time tasks therefore normally recur a large number of times at different instants of time depending on the event occurrence times. It is possible that real-time tasks recur at random instants. However, most real-time tasks recur with certain fixed periods. For example, a temperature sensing task in a chemical plant might recur indefinitely with a certain period because the temperature is sampled periodically, whereas a task handling a device interrupt might recur at random instants. Each time a task recurs, it is called an instance of the task. The first time a task occurs, it is called the first instance of the task. The next occurrence of the task is called its second instance, and so on. The jth instance of a task Ti would be denoted as Ti(j). Each instance of a real-time task is associated with a deadline by which it needs to complete and produce results. We shall at times refer to task instances as processes and use these two terms interchangeably when no confusion arises.
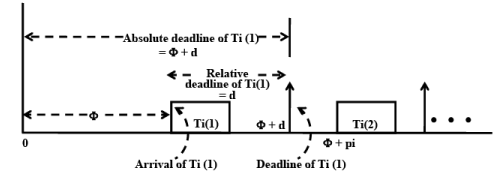
Fig. 29.1 Relative and Absolute Deadlines of a Task
Relative Deadline versus Absolute Deadline: The absolute deadline of a task is the absolute time value (counted from time 0) by which the results from the task are expected. Thus, absolute deadline is equal to the interval of time between the time 0 and the actual instant at which the deadline occurs as measured by some physical clock. Whereas, relative deadline is the time interval between the start of the task and the instant at which deadline occurs. In other words, relative deadline is the time interval between the arrival of a task and the corresponding deadline. The difference between relative and absolute deadlines is illustrated in Fig. 29.1. It can be observed from Fig. 29.1 that the relative deadline of the task Ti(1) is d, whereas its absolute deadline is φ + d.
Response Time: The response time of a task is the time it takes (as measured from the task arrival time) for the task to produce its results. As already remarked, task instances get generated due to occurrence of events. These events may be internal to the system, such as clock interrupts, or external to the system such as a robot encountering an obstacle.
| The response time is the time duration from the occurrence of the event generating the task to the time the task produces its results. |
For hard real-time tasks, as long as all their deadlines are met, there is no special advantage of completing the tasks early. However, for soft real-time tasks, average response time of tasks is an important metric to measure the performance of a scheduler. A scheduler for soft realtime tasks should try to execute the tasks in an order that minimizes the average response time of tasks.
Task Precedence: A task is said to precede another task, if the first task must complete before the second task can start. When a task Ti precedes another task Tj, then each instance of Ti precedes the corresponding instance of Tj. That is, if T1 precedes T2, then T1(1) precedes T2(1), T1(2) precedes T2(2), and so on. A precedence order defines a partial order among tasks. Recollect from a first course on discrete mathematics that a partial order relation is reflexive, antisymmetric, and transitive. An example partial ordering among tasks is shown in Fig. 29.2. Here T1 precedes T2, but we cannot relate T1 with either T3 or T4. We shall later use task precedence relation to develop appropriate task scheduling algorithms.
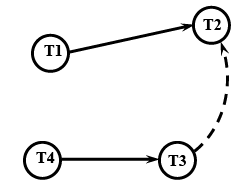
Fig. 29.2 Precedence Relation among Tasks
Data Sharing: Tasks often need to share their results among each other when one task needs to share the results produced by another task; clearly, the second task must precede the first task. In fact, precedence relation between two tasks sometimes implies data sharing between the two tasks (e.g. first task passing some results to the second task). However, this is not always true. A task may be required to precede another even when there is no data sharing. For example, in a chemical plant it may be required that the reaction chamber must be filled with water before chemicals are introduced. In this case, the task handling filling up the reaction chamber with water must complete, before the task handling introduction of the chemicals is activated. It is therefore not appropriate to represent data sharing using precedence relation. Further, data sharing may occur not only when one task precedes the other, but might occur among truly concurrent tasks, and overlapping tasks. In other words, data sharing among tasks does not necessarily impose any particular ordering among tasks. Therefore, data sharing relation among tasks needs to be represented using a different symbol. We shall represent data sharing among two tasks using a dashed arrow. In the example of data sharing among tasks represented in Fig. 29.2, T2 uses the results of T3, but T2 and T3 may execute concurrently. T2 may even start executing first, after sometimes it may receive some data from T3, and continue its execution, and so on.
Types of Real-Time Tasks
Based on the way real-time tasks recur over a period of time, it is possible to classify them into three main categories: periodic, sporadic, and aperiodic tasks. In the following, we discuss the important characteristics of these three major categories of real-time tasks.
Periodic Task: A periodic task is one that repeats after a certain fixed time interval. The precise time instants at which periodic tasks recur are usually demarcated by clock interrupts. For this reason, periodic tasks are sometimes referred to as clock-driven tasks. The fixed time interval after which a task repeats is called the period of the task. If Ti is a periodic task, then the time from 0 till the occurrence of the first instance of Ti (i.e. Ti(1)) is denoted by φi, and is called the phase of the task. The second instance (i.e. Ti(2)) occurs at φi + pi. The third instance (i.e. Ti(3)) occurs at φi + 2 ∗ pi and so on. Formally, a periodic task Ti can be represented by a 4 tuple (φi, pi, ei, di) where pi is the period of task, ei is the worst case execution time of the task, and di is the relative deadline of the task. We shall use this notation extensively in future discussions.
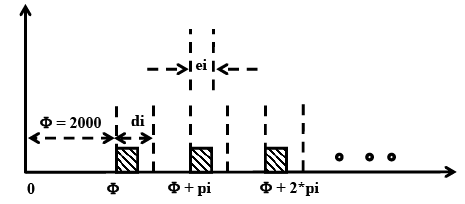
Fig. 29.3 Track Correction Task (2000mSec; pi; ei; di) of a Rocket
To illustrate the above notation to represent real-time periodic tasks, let us consider the track correction task typically found in a rocket control software. Assume the following characteristics of the track correction task. The track correction task starts 2000 milliseconds after the launch of the rocket, and recurs periodically every 50 milliseconds then on. Each instance of the task requires a processing time of 8 milliseconds and its relative deadline is 50 milliseconds. Recall that the phase of a task is defined by the occurrence time of the first instance of the task. Therefore, the phase of this task is 2000 milliseconds. This task can formally be represented as (2000 mSec, 50 mSec, 8 mSec, 50 mSec). This task is pictorially shown in Fig. 29.3. When the deadline of a task equals its period (i.e. pi=di), we can omit the fourth tuple. In this case, we can represent the task as Ti= (2000 mSec, 50 mSec, 8 mSec). This would automatically mean pi=di=50 mSec. Similarly, when φi = 0, it can be omitted when no confusion arises. So, Ti = (20mSec; 100mSec) would indicate a task with φi = 0, pi=100mSec, ei=20mSec, and di=100mSec. Whenever there is any scope for confusion, we shall explicitly write out the parameters Ti = (pi=50 mSecs, ei = 8 mSecs, di = 40 mSecs), etc.
A vast majority of the tasks present in a typical real-time system are periodic. The reason for this is that many activities carried out by real-time systems are periodic in nature, for example monitoring certain conditions, polling information from sensors at regular intervals to carry out certain action at regular intervals (such as drive some actuators). We shall consider examples of such tasks found in a typical chemical plant. In a chemical plant several temperature monitors, pressure monitors, and chemical concentration monitors periodically sample the current temperature, pressure, and chemical concentration values which are then communicated to the plant controller. The instances of the temperature, pressure, and chemical concentration monitoring tasks normally get generated through the interrupts received from a periodic timer. These inputs are used to compute corrective actions required to maintain the chemical reaction at a certain rate. The corrective actions are then carried out through actuators.
Sporadic Task: A sporadic task is one that recurs at random instants. A sporadic task Ti can be is represented by a three tuple:
Ti = (ei, gi, di)
where ei is the worst case execution time of an instance of the task, gi denotes the minimum separation between two consecutive instances of the task, di is the relative deadline. The minimum separation (gi) between two consecutive instances of the task implies that once an instance of a sporadic task occurs, the next instance cannot occur before gi time units have elapsed. That is, gi restricts the rate at which sporadic tasks can arise. As done for periodic tasks, we shall use the convention that the first instance of a sporadic task Ti is denoted by Ti(1) and the successive instances by Ti(2), Ti(3), etc.
Many sporadic tasks such as emergency message arrivals are highly critical in nature. For example, in a robot a task that gets generated to handle an obstacle that suddenly appears is a sporadic task. In a factory, the task that handles fire conditions is a sporadic task. The time of occurrence of these tasks can not be predicted.
The criticality of sporadic tasks varies from highly critical to moderately critical. For example, an I/O device interrupt, or a DMA interrupt is moderately critical. However, a task handling the reporting of fire conditions is highly critical.
Aperiodic Task: An aperiodic task is in many ways similar to a sporadic task. An aperiodic task can arise at random instants. However, in case of an aperiodic task, the minimum separation gi between two consecutive instances can be 0. That is, two or more instances of an aperiodic task might occur at the same time instant. Also, the deadline for an aperiodic tasks is expressed as either an average value or is expressed statistically. Aperiodic tasks are generally soft real-time tasks.
It is easy to realize why aperiodic tasks need to be soft real-time tasks. Aperiodic tasks can recur in quick succession. It therefore becomes very difficult to meet the deadlines of all instances of an aperiodic task. When several aperiodic tasks recur in a quick succession, there is a bunching of the task instances and it might lead to a few deadline misses. As already discussed, soft real-time tasks can tolerate a few deadline misses. An example of an aperiodic task is a logging task in a distributed system. The logging task can be started by different tasks running on different nodes. The logging requests from different tasks may arrive at the logger almost at the same time, or the requests may be spaced out in time. Other examples of aperiodic tasks include operator requests, keyboard presses, mouse movements, etc. In fact, all interactive commands issued by users are handled by aperiodic tasks.
Task Scheduling
Real-time task scheduling essentially refers to determining the order in which the various tasks are to be taken up for execution by the operating system. Every operating system relies on one or more task schedulers to prepare the schedule of execution of various tasks it needs to run. Each task scheduler is characterized by the scheduling algorithm it employs. A large number of algorithms for scheduling real-time tasks have so far been developed. Real-time task scheduling on uniprocessors is a mature discipline now with most of the important results having been worked out in the early 1970’s. The research results available at present in the literature are very extensive and it would indeed be grueling to study them exhaustively. In this text, we therefore classify the available scheduling algorithms into a few broad classes and study the characteristics of a few important ones in each class.
A Few Basic Concepts
Before focusing on the different classes of schedulers more closely, let us first introduce a few important concepts and terminologies which would be used in our later discussions.
Valid Schedule: A valid schedule for a set of tasks is one where at most one task is assigned to a processor at a time, no task is scheduled before its arrival time, and the precedence and resource constraints of all tasks are satisfied.
Feasible Schedule: A valid schedule is called a feasible schedule, only if all tasks meet their respective time constraints in the schedule.
Proficient Scheduler: A task scheduler sch1 is said to be more proficient than another scheduler sch2, if sch1 can feasibly schedule all task sets that sch2 can feasibly schedule, but not vice versa. That is, sch1 can feasibly schedule all task sets that sch2 can, but there exists at least one task set that sch2 can not feasibly schedule, whereas sch1 can. If sch1 can feasibly schedule all task sets that sch2 can feasibly schedule and vice versa, then sch1 and sch2 are called equally proficient schedulers.
Optimal Scheduler: A real-time task scheduler is called optimal, if it can feasibly schedule any task set that can be feasibly scheduled by any other scheduler. In other words, it would not be possible to find a more proficient scheduling algorithm than an optimal scheduler. If an optimal scheduler can not schedule some task set, then no other scheduler should be able to produce a feasible schedule for that task set.
Scheduling Points: The scheduling points of a scheduler are the points on time line at which the scheduler makes decisions regarding which task is to be run next. It is important to note that a task scheduler does not need to run continuously, it is activated by the operating system only at the scheduling points to make the scheduling decision as to which task to be run next. In a clock-driven scheduler, the scheduling points are defined at the time instants marked by interrupts generated by a periodic timer. The scheduling points in an event-driven scheduler are determined by occurrence of certain events.
Preemptive Scheduler: A preemptive scheduler is one which when a higher priority task arrives, suspends any lower priority task that may be executing and takes up the higher priority task for execution. Thus, in a preemptive scheduler, it can not be the case that a higher priority task is ready and waiting for execution, and the lower priority task is executing. A preempted lower priority task can resume its execution only when no higher priority task is ready.
Utilization: The processor utilization (or simply utilization) of a task is the average time for which it executes per unit time interval. In notations: for a periodic task Ti, the utilization ui = ei/pi, where ei is the execution time and pi is the period of Ti. For a set of periodic tasks {Ti}: the total utilization due to all tasks U = i=1∑n ei/pi. It is the objective of any good scheduling algorithm to feasibly schedule even those task sets that have very high utilization, i.e. utilization approaching 1. Of course, on a uniprocessor it is not possible to schedule task sets having utilization more than 1.
Jitter: Jitter is the deviation of a periodic task from its strict periodic behavior. The arrival time jitter is the deviation of the task from arriving at the precise periodic time of arrival. It may be caused by imprecise clocks, or other factors such as network congestions. Similarly, completion time jitter is the deviation of the completion of a task from precise periodic points. The completion time jitter may be caused by the specific scheduling algorithm employed which takes up a task for scheduling as per convenience and the load at an instant, rather than scheduling at some strict time instants. Jitters are undesirable for some applications.
Classification of Real-Time Task Scheduling Algorithms
Several schemes of classification of real-time task scheduling algorithms exist. A popular scheme classifies the real-time task scheduling algorithms based on how the scheduling points are defined. The three main types of schedulers according to this classification scheme are: clock-driven, event-driven, and hybrid.
| The clock-driven schedulers are those in which the scheduling points are determined by the interrupts received from a clock. In the event-driven ones, the scheduling points are defined by certain events which precludes clock interrupts. The hybrid ones use both clock interrupts as well as event occurrences to define their scheduling points. |
A few important members of each of these three broad classes of scheduling algorithms are the following:
1. Clock Driven
- Table-driven
- Cyclic
2. Event Driven
- Simple priority-based
- Rate Monotonic Analysis (RMA)
- Earliest Deadline First (EDF)
3. Hybrid
- Round-robin
Important members of clock-driven schedulers that we discuss in this text are table-driven and cyclic schedulers. Clock-driven schedulers are simple and efficient. Therefore, these are frequently used in embedded applications. We investigate these two schedulers in some detail in Sec. 2.5.
Important examples of event-driven schedulers are Earliest Deadline First (EDF) and Rate Monotonic Analysis (RMA). Event-driven schedulers are more sophisticated than clock-driven schedulers and usually are more proficient and flexible than clock-driven schedulers. These are more proficient because they can feasibly schedule some task sets which clock-driven schedulers cannot. These are more flexible because they can feasibly schedule sporadic and aperiodic tasks in addition to periodic tasks, whereas clock-driven schedulers can satisfactorily handle only periodic tasks. Event-driven scheduling of real-time tasks in a uniprocessor environment was a subject of intense research during early 1970’s, leading to publication of a large number of research results. Out of the large number of research results that were published, the following two popular algorithms are the essence of all those results: Earliest Deadline First (EDF), and Rate Monotonic Analysis (RMA). If we understand these two schedulers well, we would get a good grip on real-time task scheduling on uniprocessors. Several variations to these two basic algorithms exist.
Another classification of real-time task scheduling algorithms can be made based upon the type of task acceptance test that a scheduler carries out before it takes up a task for scheduling. The acceptance test is used to decide whether a newly arrived task would at all be taken up for scheduling or be rejected. Based on the task acceptance test used, there are two broad categories of task schedulers:
- Planning-based
- Best effort
In planning-based schedulers, when a task arrives the scheduler first determines whether the task can meet its dead- lines, if it is taken up for execution. If not, it is rejected. If the task can meet its deadline and does not cause other already scheduled tasks to miss their respective deadlines, then the task is accepted for scheduling. Otherwise, it is rejected. In best effort schedulers, no acceptance test is applied. All tasks that arrive are taken up for scheduling and best effort is made to meet its deadlines. But, no guarantee is given as to whether a task’s deadline would be met.
A third type of classification of real-time tasks is based on the target platform on which the tasks are to be run. The different classes of scheduling algorithms according to this scheme are:
- Uniprocessor
- Multiprocessor
- Distributed
Uniprocessor scheduling algorithms are possibly the simplest of the three classes of algorithms. In contrast to uniprocessor algorithms, in multiprocessor and distributed scheduling algorithms first a decision has to be made regarding which task needs to run on which processor and then these tasks are scheduled. In contrast to multiprocessors, the processors in a distributed system do not possess shared memory. Also in contrast to multiprocessors, there is no global upto-date state information available in distributed systems. This makes uniprocessor scheduling algorithms that assume central state information of all tasks and processors to exist unsuitable for use in distributed systems. Further in distributed systems, the communication among tasks is through message passing. Communication through message passing is costly. This means that a scheduling algorithm should not incur too much communication over- head. So carefully designed distributed algorithms are normally considered suitable for use in a distributed system. In the following sections, we study the different classes of schedulers in more detail.
|
47 videos|69 docs|65 tests
|
FAQs on Real Time Task Scheduling - 1 - Embedded Systems (Web) - Computer Science Engineering (CSE)
| 1. What is real-time task scheduling? |  |
| 2. How does real-time task scheduling work? | |
| 3. What are the challenges in real-time task scheduling? | |
| 4. What is the difference between preemptive and non-preemptive real-time task scheduling? | |
| 5. What are the advantages of real-time task scheduling? | |



Viva Questions
,Free
,Objective type Questions
,past year papers
,video lectures
,Summary
,Important questions
,MCQs
,shortcuts and tricks
,ppt
,Sample Paper
,Exam
,Real Time Task Scheduling - 1 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,Extra Questions
,Previous Year Questions with Solutions
,practice quizzes
,study material
,Real Time Task Scheduling - 1 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,mock tests for examination
,Semester Notes
,Real Time Task Scheduling - 1 | Embedded Systems (Web) - Computer Science Engineering (CSE)
;


Real Time Task Scheduling - 1 Free PDF Download
Importance of Real Time Task Scheduling - 1
Real Time Task Scheduling - 1 Notes
Real Time Task Scheduling - 1 Computer Science Engineering (CSE) Questions
Study Real Time Task Scheduling - 1 on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!