Real Time Task Scheduling - 3 | Embedded Systems (Web) - Computer Science Engineering (CSE) PDF Download
Event-driven Scheduling – An Introduction
The clock-driven schedulers are those in which the scheduling points are determined by the interrupts received from a clock. In the event-driven ones, the scheduling points are defined by certain events which precludes clock interrupts. The hybrid ones use both clock interrupts as well as event occurrences to define their scheduling points Cyclic schedulers are very efficient. However, a prominent shortcoming of the cyclic schedulers is that it becomes very complex to determine a suitable frame size as well as a feasible schedule when the number of tasks increases. Further, in almost every frame some processing time is wasted (as the frame size is larger than all task execution times) resulting in sub-optimal schedules. Event-driven schedulers overcome these shortcomings.
Further, eventdriven schedulers can handle aperiodic and sporadic tasks more proficiently. On the flip side, event-driven schedulers are less efficient as they deploy more complex scheduling algorithms. Therefore, event-driven schedulers are less suitable for embedded applications as these are required to be of small size, low cost, and consume minimal amount of power. It should now be clear why event-driven schedulers are invariably used in all moderate and large-sized applications having many tasks, whereas cyclic schedulers are predominantly used in small applications. In event-driven scheduling, the scheduling points are defined by task completion and task arrival events. This class of schedulers is normally preemptive, i.e., when a higher priority task becomes ready, it preempts any lower priority task that may be running.
Types of Event Driven Schedulers
We discuss three important types of event-driven schedulers:
- Simple priority-based
- Rate Monotonic Analysis (RMA)
- Earliest Deadline First (EDF)
The simplest of these is the foreground-background scheduler, which we discuss next. In section 3.4, we discuss EDF and in section 3.5, we discuss RMA.
Foreground-Background Scheduler
A foreground-background scheduler is possibly the simplest priority-driven preemptive scheduler. In foreground-background scheduling, the real-time tasks in an application are run as fore- ground tasks. The sporadic, aperiodic, and non-real-time tasks are run as background tasks. Among the foreground tasks, at every scheduling point the highest priority task is taken up for scheduling. A background task can run when none of the foreground tasks is ready. In other words, the background tasks run at the lowest priority.
Let us assume that in a certain real-time system, there are n foreground tasks which are denoted as: T1,T2,...,Tn. As already mentioned, the foreground tasks are all periodic. Let TB be the only background task. Let eB be the processing time requirement of TB. In this case, the completion time (ctB) for the background task is given by:
ctB = eB / (1−i=1∑ n ei / pi) … (3.1/2.7)
This expression is easy to interpret. When any foreground task is executing, the background task waits. The average CPU utilization due to the foreground task Ti is ei/pi, since ei amount of processing time is required over every pi period. It follows that all foreground tasks together would result in CPU utilization of i=1∑ n ei / pi. Therefore, the average time available for execution of the background tasks in every unit of time is 1−i=1∑ n ei / pi. Hence, Expr. 2.7 follows easily. We now illustrate the applicability of Expr. 2.7 through the following three simple examples.
Examples
Example 1: Consider a real-time system in which tasks are scheduled using foregroundbackground scheduling. There is only one periodic foreground task Tf : (φf =0, pf =50 msec, ef =100 msec, df =100 msec) and the background task be TB = (eB =1000 msec). Compute the completion time for background task.
Solution: By using the expression (2.7) to compute the task completion time, we have
ctB = 1000 / (1−50/100) = 2000 msec
So, the background task TB would take 2000 milliseconds to complete.
Example 2: In a simple priority-driven preemptive scheduler, two periodic tasks T1 and T2 and a background task are scheduled. The periodic task T1 has the highest priority and executes once every 20 milliseconds and requires 10 milliseconds of execution time each time. T2 requires 20 milliseconds of processing every 50 milliseconds. T3 is a background task and requires 100 milliseconds to complete. Assuming that all the tasks start at time 0, determine the time at which T3 will complete.
Solution: The total utilization due to the foreground tasks: i=1∑ 2 ei / pi = 10/20 + 20/50 =90/100.
This implies that the fraction of time remaining for the background task to execute is given by:
1−i=1∑2 ei / pi = 10/100.
Therefore, the background task gets 1 millisecond every 10 milliseconds. Thus, the background task would take 10∗(100/1) = 1000 milliseconds to complete.
Example 3: Suppose in Example 1, an overhead of 1 msec on account of every context switch is to be taken into account. Compute the completion time of TB.

Fig. 30.1 Task Schedule for Example 3
Solution: The very first time the foreground task runs (at time 0), it incurs a context switching overhead of 1 msec. This has been shown as a shaded rectangle in Fig. 30.1. Subsequently each time the foreground task runs, it preempts the background task and incurs one context switch. On completion of each instance of the foreground task, the background task runs and incurs another context switch. With this observation, to simplify our computation of the actual completion time of TB, we can imagine that the execution time of every foreground task is increased by two context switch times (one due to itself and the other due to the background task running after each time it completes). Thus, the net effect of context switches can be imagined to be causing the execution time of the foreground task to increase by 2 context switch times, i.e. to 52 milliseconds from 50 milliseconds. This has pictorially been shown in Fig. 30.1.
Now, using Expr. 2.7, we get the time required by the background task to complete:
1000/(1−52/100) = 2083.4 milliseconds
In the following two sections, we examine two important event-driven schedulers: EDF (Earliest Deadline First) and RMA (Rate Monotonic Algorithm). EDF is the optimal dynamic priority real-time task scheduling algorithm and RMA is the optimal static priority real-time task scheduling algorithm.
Earliest Deadline First (EDF) Scheduling
In Earliest Deadline First (EDF) scheduling, at every scheduling point the task having the shortest deadline is taken up for scheduling. This basic principles of this algorithm is very intuitive and simple to understand. The schedulability test for EDF is also simple. A task set is schedulable under EDF, if and only if it satisfies the condition that the total processor utilization due to the task set is less than 1. For a set of periodic real-time tasks {T1, T2, …, Tn}, EDF schedulability criterion can be expressed as:
i=1∑ n ei / pi = i=1∑ n ui ≤ 1 … (3.2/2.8)
where ui is average utilization due to the task Ti and n is the total number of tasks in the task set. Expr. 3.2 is both a necessary and a sufficient condition for a set of tasks to be EDF schedulable.
EDF has been proven to be an optimal uniprocessor scheduling algorithm. This means that, if a set of tasks is not schedulable under EDF, then no other scheduling algorithm can feasibly schedule this task set. In the simple schedulability test for EDF (Expr. 3.2), we assumed that the period of each task is the same as its deadline. However, in practical problems the period of a task may at times be different from its deadline. In such cases, the schedulability test needs to be changed. If pi > di, then each task needs ei amount of computing time every min(pi, di) duration of time. Therefore, we can rewrite Expr. 3.2 as:
i=1∑ n ei / min(pi, di) ≤ 1 … (3.3/2.9)
However, if pi < di, it is possible that a set of tasks is EDF schedulable, even when the task set fails to meet the Expr 3.3. Therefore, Expr 3.3 is conservative when pi < di, and is not a necessary condition, but only a sufficient condition for a given task set to be EDF schedulable.
Example 4: Consider the following three periodic real-time tasks to be scheduled using EDF on a uniprocessor: T1 = (e1=10, p1=20), T2 = (e2=5, p2=50), T3 = (e3=10, p3=35). Determine whether the task set is schedulable.
Solution: The total utilization due to the three tasks is given by:
i=1∑ 3 ei / pi = 10/20 + 5/50 + 10/35 = 0.89
This is less than 1. Therefore, the task set is EDF schedulable. Though EDF is a simple as well as an optimal algorithm, it has a few shortcomings which render it almost unusable in practical applications. The main problems with EDF are discussed in Sec. 3.4.3. Next, we discuss the concept of task priority in EDF and then discuss how EDF can be practically implemented.
Is EDF Really a Dynamic Priority Scheduling Algorithm?
We stated in Sec 3.3 that EDF is a dynamic priority scheduling algorithm. Was it after all correct on our part to assert that EDF is a dynamic priority task scheduling algorithm? If EDF were to be considered a dynamic priority algorithm, we should be able determine the precise priority value of a task at any point of time and also be able to show how it changes with time. If we reflect on our discussions of EDF in this section, EDF scheduling does not require any priority value to be computed for any task at any time. In fact, EDF has no notion of a priority value for a task. Tasks are scheduled solely based on the proximity of their deadline. However, the longer a task waits in a ready queue, the higher is the chance (probability) of being taken up for scheduling. So, we can imagine that a virtual priority value associated with a task keeps increasing with time until the task is taken up for scheduling. However, it is important to understand that in EDF the tasks neither have any priority value associated with them, nor does the scheduler perform any priority computations to determine the schedulability of a task at either run time or compile time.
Implementation of EDF
A naive implementation of EDF would be to maintain all tasks that are ready for execution in a queue. Any freshly arriving task would be inserted at the end of the queue. Every node in the queue would contain the absolute deadline of the task. At every preemption point, the entire queue would be scanned from the beginning to determine the task having the shortest deadline. However, this implementation would be very inefficient. Let us analyze the complexity of this scheme. Each task insertion will be achieved in O(1) or constant time, but task selection (to run next) and its deletion would require O(n) time, where n is the number of tasks in the queue.
A more efficient implementation of EDF would be as follows. EDF can be implemented by maintaining all ready tasks in a sorted priority queue. A sorted priority queue can efficiently be implemented by using a heap data structure. In the priority queue, the tasks are always kept sorted according to the proximity of their deadline. When a task arrives, a record for it can be inserted into the heap in O(log2 n) time where n is the total number of tasks in the priority queue. At every scheduling point, the next task to be run can be found at the top of the heap. When a task is taken up for scheduling, it needs to be removed from the priority queue.
This can be achieved in O(1) time. A still more efficient implementation of the EDF can be achieved as follows under the assumption that the number of distinct deadlines that tasks in an application can have are restricted. In this approach, whenever task arrives, its absolute deadline is computed from its release time and its relative deadline. A separate FIFO queue is maintained for each distinct relative deadline that tasks can have. The scheduler inserts a newly arrived task at the end of the corresponding relative deadline queue. Clearly, tasks in each queue are ordered according to their absolute deadlines. To find a task with the earliest absolute deadline, the scheduler only needs to search among the threads of all FIFO queues. If the number of priority queues maintained by the scheduler is Q, then the order of searching would be O(1). The time to insert a task would also be O(1).
Shortcomings of EDF
In this subsection, we highlight some of the important shortcomings of EDF when used for scheduling real-time tasks in practical applications.
Transient Overload Problem: Transient overload denotes the overload of a system for a very short time. Transient overload occurs when some task takes more time to complete than what was originally planned during the design time. A task may take longer to complete due to many reasons. For example, it might enter an infinite loop or encounter an unusual condition and enter a rarely used branch due to some abnormal input values. When EDF is used to schedule a set of periodic real-time tasks, a task overshooting its completion time can cause some other task(s) to miss their deadlines. It is usually very difficult to predict during program design which task might miss its deadline when a transient overload occurs in the system due to a low priority task overshooting its deadline.
The only prediction that can be made is that the task (tasks) that would run immediately after the task causing the transient overload would get delayed and might miss its (their) respective deadline(s). However, at different times a task might be followed by different tasks in execution. However, this lead does not help us to find which task might miss its deadline. Even the most critical task might miss its deadline due to a very low priority task overshooting its planned completion time. So, it should be clear that under EDF any amount of careful design will not guarantee that the most critical task would not miss its deadline under transient overload. This is a serious drawback of the EDF scheduling algorithm.
Resource Sharing Problem: When EDF is used to schedule a set of real-time tasks, unacceptably high overheads might have to be incurred to support resource sharing among the tasks without making tasks to miss their respective deadlines.
Efficient Implementation Problem: The efficient implementation that we discussed in Sec. 3.4.2 is often not practicable as it is difficult to restrict the number of tasks with distinct deadlines to a reasonable number. The efficient implementation that achieves O(1) overhead assumes that the number of relative deadlines is restricted. This may be unacceptable in some situations. For a more flexible EDF algorithm, we need to keep the tasks ordered in terms of their deadlines using a priority queue. Whenever a task arrives, it is inserted into the priority queue. The complexity of insertion of an element into a priority queue is of the order log2 n, where n is the number of tasks to be scheduled. This represents a high runtime overhead, since most real-time tasks are periodic with small periods and strict deadlines.
Rate Monotonic Algorithm(RMA)
We had already pointed out that RMA is an important event-driven scheduling algorithm. This is a static priority algorithm and is extensively used in practical applications. RMA assigns priorities to tasks based on their rates of occurrence. The lower the occurrence rate of a task, the lower is the priority assigned to it. A task having the highest occurrence rate (lowest period) is accorded the highest priority. RMA has been proved to be the optimal static priority real-time task scheduling algorithm.
In RMA, the priority of a task is directly proportional to its rate (or, inversely proportional to its period). That is, the priority of any task Ti is computed as: priority = k / pi, where pi is the period of the task Ti and k is a constant. Using this simple expression, plots of priority values of tasks under RMA for tasks of different periods can be easily obtained. These plots have been shown in Fig. 30.10(a) and Fig. 30.10(b). It can be observed from these figures that the priority of a task increases linearly with the arrival rate of the task and inversely with its period.
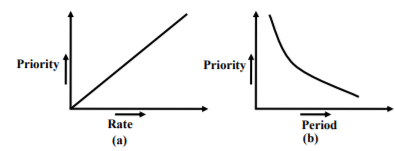
Fig. 30.2 Priority Assignment to Tasks in RMA
Schedulability Test for RMA
An important problem that is addressed during the design of a uniprocessor-based real-time system is to check whether a set of periodic real-time tasks can feasibly be scheduled under RMA. Schedulability of a task set under RMA can be determined from a knowledge of the worst-case execution times and periods of the tasks. A pertinent question at this point is how can a system developer determine the worst-case execution time of a task even before the system is developed. The worst-case execution times are usually determined experimentally or through simulation studies.
The following are some important criteria that can be used to check the schedulability of a set of tasks set under RMA.
|
47 videos|69 docs|65 tests
|
FAQs on Real Time Task Scheduling - 3 - Embedded Systems (Web) - Computer Science Engineering (CSE)
| 1. What is real-time task scheduling? |  |
| 2. What are the key challenges in real-time task scheduling? | |
| 3. How does real-time task scheduling differ from general-purpose task scheduling? | |
| 4. What are some common real-time task scheduling algorithms? | |
| 5. How can real-time task scheduling impact system performance? | |

|
4.67/5 Rating |

|
Dec 25, 2024 Last updated |

|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
Important questions
,study material
,shortcuts and tricks
,ppt
,Viva Questions
,video lectures
,Real Time Task Scheduling - 3 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,Sample Paper
,Real Time Task Scheduling - 3 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,mock tests for examination
,MCQs
,past year papers
,Previous Year Questions with Solutions
,Summary
,Real Time Task Scheduling - 3 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,Semester Notes
,Objective type Questions
,practice quizzes
,Free
,Exam
,Extra Questions
;






Real Time Task Scheduling - 3 Free PDF Download
Importance of Real Time Task Scheduling - 3
Real Time Task Scheduling - 3 Notes
Real Time Task Scheduling - 3 Computer Science Engineering (CSE) Questions
Study Real Time Task Scheduling - 3 on the App
|
© EduRev
|
Education Revolution
|



|




