Reduced Instruction Set Computers | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE) PDF Download
Reduced Instruction Set Computers:
Instruction Execution Characteristics, Large Register Files and RISC Architecture
Instruction Execution Characteristics
The semantic gap is the difference between the operations provided in HLLs and those provided in computer architecture. . Designers responded with architectures intended to close this gap. Key features include large instruction sets, dozens of addressing modes, and various HLL statements implemented in hardware. Such complex instruction sets are intended to
- Ease the task of the compiler writer.
- Improve execution efficiency, because complex sequences of operations can be implemented in microcode.
- Provide support for even more complex and sophisticated HLLs.
The results of these studies inspired some researchers to look for a different approach: namely, to make the architecture that supports the HLL simpler, rather than more complex To understand the line of reasoning of the RISC advocates, we begin with a brief review of instruction execution characteristics. The aspects of computation of interest are as follows:
• Operations performed:
These determine the functions to be performed by the processor and its interaction with memory.
• Operands used:
The types of operands and the frequency of their use determine the memory organization for storing them and the addressing modes for accessing them.
• Execution sequencing: This determines the control and pipeline organization.
Implications
A number of groups have looked at results such as those just reported and have concluded that the attempt to make the instruction set architecture close to HLLs is not the most effective design strategy. Rather, the HLLs can best be supported by optimizing performance of the most time-consuming features of typical HLL programs.
• Generalizing from the work of a number of researchers, three elements emerge that, by and large, characterize RISC architectures.
• First, use a large number of registers or use a compiler to optimize register usage. This is intended to optimize operand referencing. The studies just discussed show that there are several references per HLL instruction and that there is a high proportion of move (assignment) statements. This suggests that performance can be improved by reducing memory references at the expense of more register references.
• Second, careful attention needs to be paid to the design of instruction pipelines. Because of the high proportion of conditional branch and procedure call instructions, a straightforward instruction pipeline will be inefficient. This manifests itself as a high proportion of instructions that are prefetched but never executed.
• Finally, a simplified (reduced) instruction set is indicated. This point is not as obvious as the others, but should become clearer in the ensuing discussion.
Use of Large Register Files:
The reason that register storage is indicated is that it is the fastest available storage device, faster than both main memory and cache. The register file will allow the most frequently accessed operands to be kept in registers and to minimize register-memory operations.
Two basic approaches are possible, one based on software and the other on hardware.
The software approach is to rely on the compiler to maximize register usage. The compiler will attempt to allocate registers to those variables that will be used the most in a given time period. This approach requires the use of sophisticated program-analysis algorithms.
The hardware approach is simply to use more registers so that more variables can be held in registers for longer periods of time. Here we will discuss the hardware approach.
Register Windows
On the face of it, the use of a large set of registers should decrease the need to access memory.
Because most operand references are to local scalars, the obvious approach is to store these in registers, and few registers reserved for global variables. The problem is that the definition of local changes with each procedure call and return, operations that occur frequently
The solution is based on two other results reported. First, a typical procedure employs only a few passed parameters and local variables. Second, the depth of procedure activation fluctuates within a relatively narrow range.
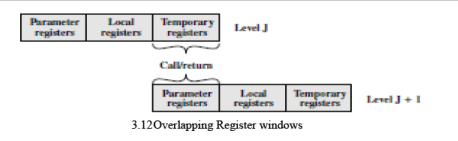
The concept is illustrated in Figure 3.12. At any time, only one window of registers is visible and is addressable as if it were the only set of registers (e.g., addresses 0 through N -1).The window is divided into three fixed-size areas. Parameter registers hold parameters passed down from the procedure that called the current procedure and hold results to be passed back up. Local registers are used for local variables, as assigned by the compiler. Temporary registers are used to exchange parameters and results with the next lower level (procedure called by current procedure).The temporary registers at one level are physically the same as the parameter registers at the next lower level. This overlap permits parameters to be passed without the actual movement of data. Keep in mind that, except for the overlap, the registers at two different levels are physically distinct. That is, the parameter and local registers at level J are disjoint from the local and temporary registers at level J + 1.
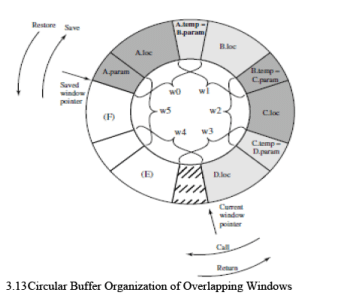
The circular organization is shown in Figure 3.13, which depicts a circular buffer of six windows. The buffer is filled to a depth of 4 (A called B; B called C; C called D) with procedure D active. The currentwindow pointer (CWP) points to the window of the currently active procedure. Register references by a machine instruction are offset by this pointer to determine the actual physical register.
The saved-window pointer (SWP) identifies the window most recently saved in memory. If procedure D now calls procedure E, arguments for E are placed in D’s temporary registers (the overlap between w3 and w4) and the CWP is advanced by one window. If procedure E then makes a call to procedure F, the call cannot be made with the current status of the buffer. This is because F’s window overlaps A’s window. If F begins to load its temporary registers, preparatory to a call, it will overwrite the pa rameter registers of A (A. in).
Thus, when CWP is incremented (modulo 6) so that it becomes equal to SWP, an interrupt occurs, and A’s window is saved. Only the first two portions (A. in and A.loc) need be saved. Then, the SWP is incremented and the call to F proceeds. A similar interrupt can occur on returns. For example, subsequent to the activation of F, when B returns to A, CWP is decremented and becomes equal to SWP. This causes an interrupt that results in the restoration of A’s window.
Global Variables
The window scheme does not address the need to store global variables, those accessed by more than one procedure. Two options suggest themselves.
First, variables declared as global in an HLL can be assigned memory locations by the compiler, and all machine instructions that reference these variables will use memory-reference operands.
An alternative is to incorporate a set of global registers in the processor. These registers would be fixed in number and available to all procedures..There is an increased hardware burden to accommodate the split in register addressing. In addition, the compiler must decide which global variables should be assigned to registers.
Large Register File versus Cache
The register file, organized into windows, acts as a small, fast buffer for holding a subset of all variables that are likely to be used the most heavily. From this point of view, the register file acts much like a cache memory, although a much faster memory. The question therefore arises as to whether it would be simpler and better to use a cache and a small traditional register file. Table 3.2 compares characteristics of the two approaches.

• The window-based register file holds all the local scalar variables (except in the rare case of window overflow) of the most recent N -1 procedure activations. The cache holds a selection of recently used scalar variables. The register file should save time, because all local scalar variables are retained.
• The cache may make more efficient use of space, because it is reacting to the situation dynamically. A register file may make inefficient use of space, because not all procedures will need the full window space allotted to them.
• The cache suffers from another sort of inefficiency: Data are read into the cache in blocks. Whereas the register file contains only those variables in use, the cache reads in a block of data, some or much of which will not be used.
• The cache is capable of handling global as well as local variables. There are usually many global scalars, but only a few of them are heavily used. A cache will dynamically discover these variables and hold them. If the window-based register file is supplemented with global registers, it too can hold some global scalars. However, it is difficult for a compiler to determine which globals will be heavily used.
• With the register file, the movement of data between registers and memory is determined by the procedure nesting depth.. Most cache memories are set associative with a small set size.
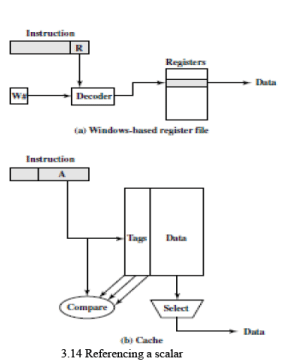
• Figure 3.14 illustrates the difference. To reference a local scalar in a window-based register file, a “virtual”register number and a window number are used. These can pass through a relatively simple decoder to select one of the physical registers. To reference a memory location in cache, a full-width memory address must be generated. The complexity of this operation depends on the addressing mode. In a set associative cache, a portion of the address is used to read a number of words and tags equal to the set size. Another portion of the address is compared with the tags, and one of the words that were read is selected. It should be clear that even if the cache is as fast as the register file, the access time will be considerably longer. Thus, from the point of view of performance, the window-based register file is superior for local scalars. Further performance improvement could be achieved by the addition of a cache for instructions only.
Reduced Instruction Set Computer:
Why CISC
CISC has richer instruction sets, which include a larger number of instructions and more complex instructions. Two principal reasons have motivated this trend: a desire to simplify compilers and a desire to improve performance.
The first of the reasons cited, compiler simplification, seems obvious. The task of the compiler writer is to generate a sequence of machine instructions for each HLL statement. If there are machine instructions that resemble HLL statements, this task is simplified.
This reasoning has been disputed by the RISC researchers. They have found that complex machine instructions are often hard to exploit because the compiler must find those cases that exactly fit the construct. The task of optimizing the generated code to minimize code size, reduce instruction execution count, and enhance pipelining is much more difficult with a complex instruction set.
The other major reason cited is the expectation that a CISC will yield smaller, faster programs. Let us examine both aspects of this assertion: that program will be smaller and that they will execute faster. There are two advantages to smaller programs. First, because the program takes up less memory, there is a savings in that resource. Second, in a paging environment, smaller programs occupy fewer pages, reducing page faults.
The problem with this line of reasoning is that it is far from certain that a CISC program will be smaller than a corresponding RISC program. Thus it is far from clear that a trend to increasingly complex instruction sets is appropriate. This has led a number of groups to pursue the opposite path.
Characteristics of Reduced Instruction Set Architectures
Although a variety of different approaches to reduced instruction set architecture have been taken, certain characteristics are common to all of them:
• One instruction per cycle
• Register-to-register operations
• Simple addressing modes
• Simple instruction formats
One machine instruction per machine cycle.A machine cycle is defined to be the time it takes to fetch two operands from registers, perform an ALU operation, and store the result in a register. Thus, RISC machine instructions should be no more complicated than, and execute about as fast as, microinstructions on CISC machines.With simple, one-cycle instructions, there is little or no need for microcode; the machine instructions can be hardwired. Such instructions should execute faster than comparable machine instructions on other machines, because it is not necessary to access a microprogram control store during instruction execution.
A second characteristic is that most operations should be register to register, with only simple LOAD and STORE operations accessing memory.This design feature simplifies the instruction set and therefore the control unit. For example, a RISC instruction set may include only one or two ADD instructions (e.g., integer add, add with carry); the VAX has 25 different ADD instructions.
This emphasis on register-to-register operations is notable for RISC designs. Contemporary CISC machines provide such instructions but also include memoryto-memory and mixed register/memory operations. Figure 13.5a illustrates the approach taken, Figure 13.5b may be a fairer comparison.
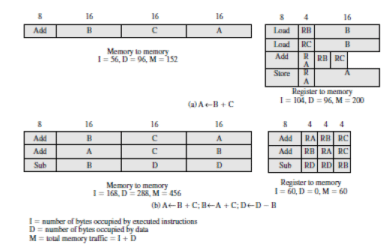
3.15 Two Comparisions of Register-to-Register and Register-to-Memory References
A third characteristic is the use of simple addressing modes. Almost all RISC instructions use simple register addressing. Several additional modes, such as displacement and PC-relative, may be included.
A final common characteristic is the use of simple instruction formats. Generally, only one or a few formats are used. Instruction length is fixed and aligned on word boundaries
These characteristics can be assessed to determine the potential performance benefits of the RISC approach.
First, more effective optimizing compilers can be developed
A second point, already noted, is that most instructions generated by a compiler are relatively simple anyway. It would seem reasonable that a control unit built specifically for those instructions and using little or no microcode could execute them faster than a comparable CISC.
A third point relates to the use of instruction pipelining. RISC researchers feel that the instruction pipelining technique can be applied much more effectively with a reduced instruction set.
A final, and somewhat less significant, point is that RISC processors are more responsive to interrupts because interrupts are checked between rather elementary operations.
CISC versus RISC Characteristics
After the initial enthusiasm for RISC machines, there has been a growing realization that (1) RISC designs may benefit from the inclusion of some CISC features and that (2) CISC designs may benefit from the inclusion of some RISC features. The result is that the more recent RISC designs, notably the PowerPC, are no longer “pure” RISC and the more recent CISC designs, notably the Pentium II and later Pentium models, do incorporate some RISC characteristics.
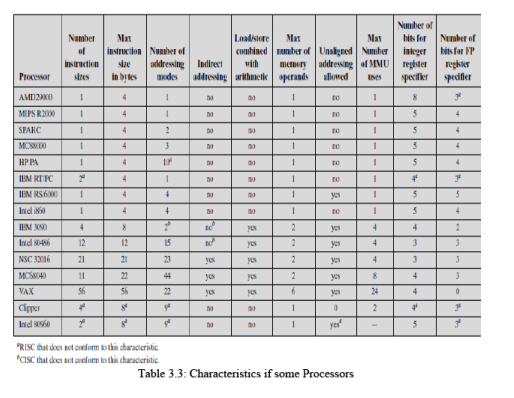
Table 3.3 lists a number of processors and compares them across a number of characteristics. For purposes of this comparison, the following are considered typical of a classic RISC:
1. A single instruction size.
2. That size is typically 4 bytes.
3. A small number of data addressing modes,typically less than five.This parameter is difficult to pin down. In the table, register and literal modes are not counted and different formats with different offset sizes are counted separately.
4. No indirect addressing that requires you to make one memory access to get the address of another operand in memory.
5. No operations that combine load/store with arithmetic (e.g., add from memory, add to memory).
6. No more than one memory-addressed operand per instruction.
7. Does not support arbitrary alignment of data for load/store operations.
8. Maximum number of uses of the memory management unit (MMU) for a data address in an instruction.
9. Number of bits for integer register specifier equal to five or more. This means that at least 32 integer registers can be explicitly referenced at a time.
10. Number of bits for floating-point register specifier equal to four or more.This means that at least 16 floating-point registers can be explicitly referenced at a time.
Items 1 through 3 are an indication of instruction decode complexity. Items 4 through 8 suggest the ease or difficulty of pipelining, especially in the presence of virtual memory requirements. Items 9 and 10 are related to the ability to take good advantage of compilers.
In the table, the first eight processors are clearly RISC architectures, the next five are clearly CISC, and the last two are processors often thought of as RISC that in fact have many CISC characteristics.
|
20 videos|86 docs|48 tests
|
FAQs on Reduced Instruction Set Computers - Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
| 1. What is a Reduced Instruction Set Computer (RISC)? |  |
| 2. How does a RISC computer differ from a Complex Instruction Set Computer (CISC)? | |
| 3. What are the advantages of using a Reduced Instruction Set Computer (RISC)? | |
| 4. Are there any disadvantages of using a Reduced Instruction Set Computer (RISC)? | |
| 5. Can RISC and CISC architectures coexist in modern computer systems? | |

|
4.84/5 Rating |

|
Dec 26, 2024 Last updated |
|
20 videos|86 docs|48 tests
|

|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
Objective type Questions
,Viva Questions
,mock tests for examination
,Reduced Instruction Set Computers | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,Free
,ppt
,Summary
,Extra Questions
,shortcuts and tricks
,Reduced Instruction Set Computers | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,Important questions
,MCQs
,Reduced Instruction Set Computers | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,Previous Year Questions with Solutions
,study material
,Sample Paper
,past year papers
,Semester Notes
,Exam
,video lectures
,practice quizzes
;






Reduced Instruction Set Computers Free PDF Download
Importance of Reduced Instruction Set Computers
Reduced Instruction Set Computers Notes
Reduced Instruction Set Computers Computer Science Engineering (CSE) Questions
Study Reduced Instruction Set Computers on the App
|
© EduRev
|
Education Revolution
|



|




