Rounding of Data, Business Mathematics & Statistics | Business Mathematics and Statistics - B Com PDF Download

Rounding and suppression to anonymise statistics
HESA data is collected for statistical research purposes, but student and staff data can be 'Personal Data' in its raw form and this needs to be protected from unauthorised exposure.
If you've obtained data from HESA it is your responsibility to apply our specified disclosure control to your research outputs. This page is intended to help clarify how our rounding and suppression strategy works. If you're using published HESA data this page explains why you might notice missing data or figures that don't add up.
The basics
Our Standard Rounding Methodology is used in all HESA publications and must be used by other users of HESA data too. It is a condition of the Agreement for the Supply of Information Services (the licence to use HESA data) that any permitted outputs from research using HESA data must apply the rounding methodology. This would include research papers, internal reports or presentation slides - anything that displays the results of research on the raw data.
There are three aspects to the rounding methodology:
- Counts of people are rounded to the nearest multiple of 5.
- Percentages (like % of students who are disabled) are not published if they are fractions of a small group of people (fewer than 22.5).
This includes percentage change calculations ([New-Old]/Old) where either the old or new number is less than 22.5. - Averages (like average age or average salary) are not published if they are averages of a small group of people (7 or fewer).
These rules only apply to data about people. They do not apply to data about finances, areas, volumes etc.
The rules are applied after any calculations (sums, averages, percentages etc.) have been done so that changes to the data don't compound each other to give even more inaccurate results. This sometimes means numbers in tables don't appear to add up.
The full methodology, published in our data definitions and included in all our data supply contracts, is as follows:
- All numbers are rounded to the nearest multiple of 5
- Any number lower than 2.5 is rounded to 0
- Halves are always rounded upwards (e.g. 2.5 is rounded to 5)
- Percentages based on fewer than 22.5 individuals are suppressed
- Averages based on 7 or fewer individuals are suppressed
- The above requirements apply to headcounts, FPE and FTE data
- Financial data is not rounded
Example
Here is a fictional table prepared from raw data
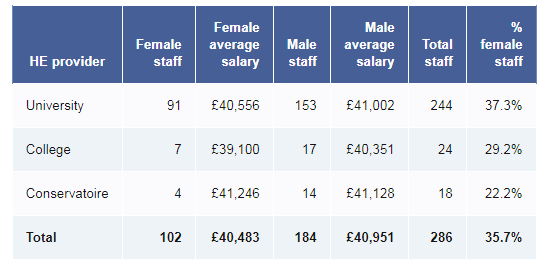
This is how the data should appear after rounding and suppression have been applied. Hover your mouse pointer over the underlined figures for a description of what has changed:
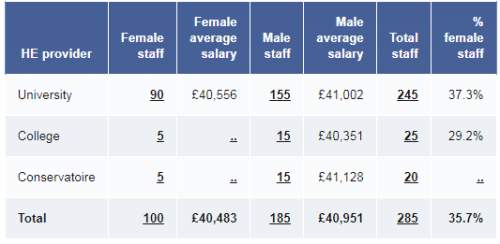
- All the counts of individuals have been rounded to the nearest multiple of 5.
- The total staff number for College doesn't match the sum of female and male staff because the real sum (24) is rounded independently of the constituent parts.
- Average salaries of female staff at College and Conservatoire are suppressed because there are 7 or fewer people in these groups.
- The percentage of female staff at Conservatoire is suppressed because there are fewer than 22.5 staff overall.
Rationale
The purpose of the rounding methodology is to reduce the risk of identifying individuals from published figures.
Rounding of all figures, even very large ones, to the nearest 5 prevents multiple tables being used to identify small numbers. For example one table might show 134 students studying French at a university. Another table might be restricted to UK domicile students and show 133 students. The two tables would identify that there's exactly one foreign student on that course but rounding the numbers obscures this potentially personal information.
Our rounding methodology is applied to our own publications, but also to outputs from other researchers. Consistently rounding all numbers is easy to understand and easy to apply in any situation. It is also easy to spot so that readers can see it has been applied.
Percentages are suppressed for small groups to prevent percentages from giving away the real un-rounded figures in a table. For example the rounded figures in the table below could only match the percentages for one set of original un-rounded data: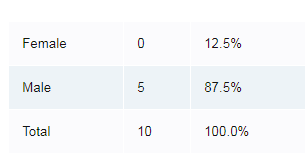
The only un-rounded figures that could give these percentages are: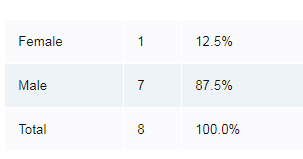
Suppressing percentages where the Total is less than 22.5 (rounding to 20) reduces this risk significantly, but doesn't eliminate it completely. We have to balance the small risk of working out real un-rounded figures against being able to publish useful statistics.
Averages are suppressed only for much smaller groups of 7 people or fewer. An average salary for one person will be that person's actual salary. In a small group of people some of them could work out the salary of another member by calculating backwards from their own salaries. The more people in the group, the less plausible this scenario becomes. By suppressing averages based on groups of 7 or fewer (anything rounded to 0 or 5) this eliminates the most likely chances of working out someone's personal information.
|
124 videos|176 docs
|
FAQs on Rounding of Data, Business Mathematics & Statistics - Business Mathematics and Statistics - B Com
| 1. What is rounding of data in business mathematics and statistics? |  |
| 2. Why is rounding of data important in business mathematics and statistics? | |
| 3. How is rounding of data performed in business mathematics and statistics? | |
| 4. Are there any limitations or considerations when rounding data in business mathematics and statistics? | |
| 5. Can rounding of data affect statistical analysis and decision-making in business? | |



Rounding of Data
,Extra Questions
,study material
,Rounding of Data
,shortcuts and tricks
,Sample Paper
,Summary
,Rounding of Data
,video lectures
,mock tests for examination
,Free
,Semester Notes
,Business Mathematics & Statistics | Business Mathematics and Statistics - B Com
,Business Mathematics & Statistics | Business Mathematics and Statistics - B Com
,Previous Year Questions with Solutions
,Business Mathematics & Statistics | Business Mathematics and Statistics - B Com
,MCQs
,Viva Questions
,practice quizzes
,Exam
,Objective type Questions
,ppt
,Important questions
,past year papers
;


Rounding of Data, Business Mathematics & Statistics Free PDF Download
Importance of Rounding of Data, Business Mathematics & Statistics
Rounding of Data, Business Mathematics & Statistics Notes
Rounding of Data, Business Mathematics & Statistics B Com Questions
Study Rounding of Data, Business Mathematics & Statistics on the App
|
© EduRev
|
Education Revolution
|



|





