Testing Embedded Systems - 1 | Embedded Systems (Web) - Computer Science Engineering (CSE) PDF Download

Testing Embedded Systems
Introduction
What is testing?
- Testing is an organized process to verify the behavior, performance, and reliability of a device or system against designed specifications.
- It ensures a device or system to be as defect-free as possible.
- Expected behavior, performance, and reliability must be both formally described and measurable.
Verification vs. Testing [1]
- Verification or debugging is the process of removing defects ("bugs") in the design phase to ensure that the synthesized design, when manufactured will behave as expected.
- Testing is a manufacturing step to ensure that the manufactured device is defect free.
- Testing is one of the detective measures, and verification one of the corrective measures of quality.
| Verification | Testing |
| Verifies the correctness of design. | Verifies correctness of manufactured system. |
| Performed by simulation, hardware emulation, or formal methods. | Two-part process: 1. Test generation: software process executed once during design. 2. Test application: electrical tests applied to hardware. |
| Performed once prior to manufacturing. | Test a pplication performed on every manufactured device. |
| Responsible for quality of design. | Responsible for quality of devices. |
What is an "embedded system"?
Embedded systems are electronically controlled system where hardware and software are combined [2-3]. These are computers incorporated in consumer products or other devices to perform application-specific functions. The enduser is usually not even aware of their existence. Embedded systems can contain a variety of computing devices, such as microcontrollers, application-specific integrated circuits, and digital signal processors. Most systems used in real life as power plant system, medical instrument system, home appliances, air traffic control station, routers and firewalls, telecommunication exchanges, robotics and industrial automation, smart cards, personal digital assistant (PDA) and cellular phone are example of embedded system.
Real-Time System
Most, if not all, embedded systems are "real-time". The terms "real-time" and "embedded" are often used interchangeably. A real-time system is one in which the correctness of a computation not only depends on its logical correctness, but also on the time at which the result is produced.
- In hard real time systems if the timing constraints of the system are not met, system crash could be the consequence. For example, in mission-critical application where failure is not an option, time deadlines must be followed.
- In case of soft real time systems no catastrophe will occur if deadline fails and the time limits are negotiable.
In spite of the progress of hardware/software codesign, hardware and software in embedded system are usually considered separately in the design process. There is a strong interaction between hardware and software in their failure mechanisms and diagnosis, as in other aspects of system performance. System failures often involve defects in both hardware and software. Software does not “break” in the traditional sense, however it can perform inappropriately due to faults in the underlying hardware, as well as specification or design flaws in either the hardware or the software. At the same time, the software can be exploited to test for and respond to the presence of faults in the underlying hardware. It is necessary to understand the importance of the testing of embedded system, as its functions have been complicated. However the studies related to embedded system test are not adequate.
2. Embedded Systems Testing
Test methodologies and test goals differ in the hardware and software domains. Embedded software development uses specialized compilers and development software that offer means for debugging. Developers build application software on more powerful computers and eventually test the application in the target processing environment.
In contrast, hardware testing is concerned mainly with functional verification and self-test after chip is manufactured. Hardware developers use tools to simulate the correct behavior of circuit models. Vendors design chips for self-test which mainly ensures proper operation of circuit models after their implementation. Test engineers who are not the original hardware developers test the integrated system.
This conventional, divided approach to software and hardware development does not address the embedded system as a whole during the system design process. It instead focuses on these two critical issues of testing separately. New problems arise when developers integrate the components from these different domains.
In theory, unsatisfactory performance of the system under test should lead to a redesign. In practice, a redesign is rarely feasible because of the cost and delay involved in another complete design iteration. A common engineering practice is to compensate for problems within the integrated system prototype by using software patches. These changes can unintentionally affect the behavior of other parts in the computing system.
At a higher abstraction level, executable specification languages provide an excellent means to assess embedded-systems designs. Developers can then test system-level prototypes with either formal verification techniques or simulation. A current shortcoming of many approaches is, however, that the transition from testing at the system level to testing at the implementation level is largely ad hoc. To date, system testing at the implementation level has received attention in the research community only as coverification, which simulates both hardware and software components conjointly. Coverification runs simulations of specifications on powerful computer systems. Commercially available coverification tools link hardware simulators and software debuggers in the implementation phase of the design process.
Since embedded systems are frequently employed in mobile products, they are exposed to vibration and other environmental stresses that can cause them to fail. Some embedded systems, such as those in automotive applications, are exposed to extremely harsh environments. These applications are preparing embedded systems to meet new and more stringent requirements of safety and reliability is a significant challenge for designers. Critical applications and applications with high availability requirements are the main candidates for on-line testing.
Faults in Embedded Systems
Incorrectness in hardware systems may be described in different terms as defect, error and faults. These three terms are quite bit confusing. We will define these terms as follows [1]:
Defect: A defect in a hardware system is the unintended difference between the implemented hardware and its intended design. This may be a process defects, material defects, age defects or package effects.
Error: A wrong output signal produced by a defective system is called an error. An error is an “effect” whose cause is some “defect”. Errors induce failures, that is, a deviation from appropriate system behavior. If the failure can lead to an accident, it is a hazard.
Fault: A representation of a “defect” at the abstraction level is called a fault. Faults are physical or logical defects in the design or implementation of a device.
Hardware Fault Model (Gate Level Fault Models)
As the complexity and integration of hardware are increasing with technology, defects are too numerous and very difficult to analyze. A fault model helps us to identify the targets for testing and analysis of failure. Further, the effectiveness of the model in terms of its relation to actual failures should be established by experiments. Faults in a digital system can be classified into three groups: design, fabrication, and operational faults. Design faults are made by human designers or CAD software (simulators, translators, or layout generators), and occur during the design process.
These faults are not directly related to the testing process. Fabrication defects are due to an imperfect manufacturing process. Defects on hardware itself, bad connections, bridges, improper semiconductor doping and irregular power supply are the examples of physical faults. Physical faults are also called as defect-oriented faults. Operational or logical faults are occurred due to environmental disturbances during normal operation of embedded system. Such disturbances include electromagnetic interference, operator mistakes, and extremes of temperature and vibration. Some design defects and manufacturing faults escape detection and combine with wearout and environmental disturbances to cause problems in the field.
Hardware faults are classified as stuck-at faults, bridging faults, open faults, power disturbance faults, spurious current faults, memory faults, transistor faults etc. The most commonly used fault model is that of the “stuck-at fault model” [1]. This is modeled by having a line segment stuck at logic 0 or 1 (stuck-at 1 or stuck-at 0).
Stuck-at Fault: This is due to the flaws on hardware, and they represent faults of the signal lines. A signal line is the input or output of a logic gate. Each connecting line can have two types of faults: stuck-at-0 (s-a-0) or stuck-at-1 (s-a-1). In general several stuck-at faults can be simultaneously present in the circuit. A circuit with n lines can have 3n –1 possible stuck line combinations as each line can be one of the three states: s-a-0, s-a-1 or fault free. Even a moderate value of n will give large number of multiple stuck-at faults. It is a common practice, therefore to model only single stuck-at faults. An n-line circuit can have at most 2n single stuckat faults. This number can be further reduced by fault collapsing technique.
Single stuck-at faults is characterized by the following properties:
- Fault will occur only in one line.
- The faulty line is permanently set to either 0 or 1.
- The fault can be at an input or output of a gate.
- Every fan-out branch is to be considered as a separate line.
Figure 38.1 gives an example of a single stuck-at fault. A stuck-at-1 fault as marked at the output of OR gate implies that the faulty signal remains 1 irrespective of the input state of the OR gate.
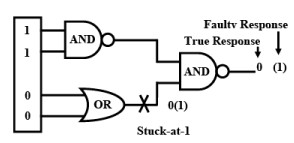
Fig. 38.1 An example of a stuck-at fault
Bridging faults: These are due to a short between a group of signal. The logic value of the shorted net may be modeled as 1-dominant (OR bridge), 0-dominant (AND bridge), or intermediate, depending upon the technology in which the circuit is implemented.
Stuck-Open and Stuck-Short faults: MOS transistor is considered as an ideal switch and two types of faults are modeled. In stuck-open fault a single transistor is permanently stuck in the open state and in stuck-short fault a single transistor is permanently shorted irrespective of its gate voltage. These are caused by bad connection of signal line.
Power disturbance faults: These are caused by inconsistent power supplies and affect the whole system.
Spurious current faults: that exposed to heavy ion affect whole system. Operational faults are usually classified according to their duration:
Permanent faults exist indefinitely if no corrective action is taken. These are mainly manufacturing faults and are not frequently occur due to change in system operation or environmental disturbances.
Intermittent faults appear, disappear, and reappear frequently. They are difficult to predict, but their effects are highly correlated. Most of these faults are due to marginal design or manufacturing steps. These faults occur under a typical environmental disturbance.
Transient faults appear for an instant and disappear quickly. These are not correlated with each other. These are occurred due random environmental disturbances. Power disturbance faults and spurious current faults are transient faults.
3.2 Software-Hardware Covalidation Fault Model
A design error is a difference between the designer’s intent and an executable specification of the design. Executable specifications are often expressed using high-level hardware-software languages. Design errors may range from simple syntax errors confined to a single line of a design description, to a fundamental misunderstanding of the design specification which may impact a large segment of the description. A design fault describes the behavior of a set of design errors, allowing a large set of design errors to be modeled by a small set of design faults. The majority of covalidation fault models are behavioral-level fault models. Existing covalidation fault models can be classified by the style of behavioral description upon which the models are based. Many different internal behavioral formats are possible [8]. The covalidation fault models currently applied to hardware-software designs have their origins in either the hardware [9] or the software [10] domains.
3.2.1 Textual F ault Models
A textual fault model is one, which is applied directly to the original textual behavioral description. The simplest textual fault model is the statement coverage metric introduced in software testing [10] which associates a potential fault with each line of code, and requires that each statement in the description be executed during testing. This coverage metric is accepted as having limited accuracy in part because fault effect observation is ignored. Mutation analysis is a textual fault model which was originally developed in the field of software test, and has also been applied to hardware validation. A mutant is a version of a behavioral description which differs from the original by a single potential design error. A mutation operator is a function which is applied to the original program to generate a mutant.
3.2.2 Control-Dataflow Fault Models
A number of fault models are based on the traversal of paths through the contol data flow graph (CDFG) representing the system behavior. In order to apply these fault models to a hardwaresoftware design, both hardware and software components must be converted into a CDFG description. Applying these fault models to the CDFG representing a single process is a well understood task. Existing CDFG fault models are restricted to the testing of single processes. The earliest control-dataflow fault models include the branch coverage and path coverage [10] models used in software testing.
The branch coverage metric associates potential faults with each direction of each conditional in the CDFG. The branch coverage metric has been used for behavioral validation for coverage evaluation and test generation [11, 12]. The path coverage metric is a more demanding metric than the branch coverage metric because path coverage reflects the number of controlflow paths taken. The assumption is that an error is associated with some path through the control flow graph and all control paths must be executed to guarantee fault detection.
Many CDFG fault models consider the requirements for fault activation without explicitly considering fault effect observability. Researchers have developed observability-based behavioral fault models [13, 14] to alleviate this weakness.
3.2.3 State Machine Fault Models
Finite state machines (FSMs) are the classic method of describing the behavior of a sequential system and fault models have been defined to be applied to state machines. The commonly used fault models are state coverage which requires that all states be reached, and transition coverage which requires that all transitions be traversed. State machine transition tours, paths covering each transition of the machine, are applied to microprocessor validation [15]. The most significant problem with the use of state machine fault models is the complexity resulting from the state space size of typical systems. Several efforts have been made to alleviate this problem by identifying a subset of the state machine which is critical for validation [16].
3.2.4 Application-Specific Fault Models
A fault model which is designed to be generally applicable to arbitrary design types may not be as effective as a fault model which targets the behavioral features of a specific application. To justify the cost of developing and evaluating an application-specific fault model, the market for the application must be very large and the fault modes of the application must be well understood. For this reason, application-specific fault models are seen in microprocessor test and validation [17,18].
3.3 Interface Faults
To manage the high complexity of hardware-software design and covalidation, efforts have been made to separate the behavior of each component from the communication architecture [19]. Interface covalidation becomes more significant with the onset of core-based design methodologies which utilize pre-designed, pre-verified cores. Since each core component is preverified, the system covalidation problem focuses on the interface between the components. A case study of the interface-based covalidation of an image compression system has been presented [20].
Testing of Embedded Core-Based System-on-Chips (SOCs)
The system-on-chip test is a single composite test comprised of the individual core tests of each core, the UDL tests, and interconnect tests. Each individual core or UDL test may involve surrounding components. Certain operational constraints (e.g., safe mode, low power mode, bypass mode) are often required which necessitates access and isolation modes.
In a core-based system-on-chip [5], the system integrator designs the User Defined Logic (UDL) and assembles the pre-designed cores provided by the core vendor. A core is typically hardware description of standard IC e.g., DSP, RISC processor, or DRAM core. Embedded cores represent intellectual property (IP) and in order to protect IP, core vendors do not release the detailed structural information to the system integrator. Instead a set of test pattern is provided by the core vendor that guarantees a specific fault coverage. Though the cores are tested as part of overall system performance by the system integrator, the system integrator deals the core as a black box. These test patterns must be applied to the cores in a given order, using a specific clock strategy.
The core internal test developed by a core provider need to be adequately described, ported and ready for plug and play, i.e., for interoperability, with the system chip test. For an internal test to accompany its corresponding core and be interoperable, it needs to be described in an commonly accepted, i.e., standard, format. Such a standard format is currently being developed by IEEE PI 500 and referred to as standardization of a core test description language [22].
In SOCs cores are often embedded in several layers of user-defined or other core-based logic, and direct physical access to its peripheries is not available from chip I/Os. Hence, an electronic access mechanism is needed. This access mechanism requires additional logic, such as a wrapper around the core and wiring, such as a test access mechanism to connect core peripheries to the test sources and sinks. The wrapper performs switching between normal mode and the test mode(s) and the wiring is meant to connect the wrapper which surrounds the core to the test source and sink. The wrapper can also be utilized for core isolation. Typically, a core needs to be isolated from its surroundings in certain test modes. Core isolation is often required on the input side, the output side, or both.
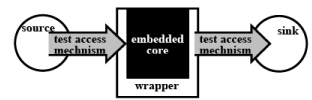
Fig. 38. 2 Overview of the three elements in an embedded-core test approach:
(1) test pattern source, (2) test access mechanism, and (3) core test wrapper [5].
A conceptual architecture for testing embedded-core-based SOCs is shown in Figure 38.2 It consists of three structural elements:
1. Test Pattern Source and Sink
The test pattern source generates the test stimuli for the embedded core, and the test pattern sink compares the response(s) to the expected response(s). Test pattern source as well as sink can be implemented either off-chip by external Automatic Test Equipment (ATE), on-chip by Built-In Self-Test (or Embedded ATE), or as a combination of both. Source and sink do not need to be of the same type, e.g., the source of an embedded core can be implemented off-chip, while the sink of the same core is implemented on-chip. The choice for a certain type of source or sink is determined by (1) The type of circuitry in the core, (2) The type of pre-defined tests that come with the core and (3) Quality and Cost considerations. The type of circuitry of a certain core and the type of predefined tests that come with the core determine which implementation options are left open for test pattern source and sink. The actual choice for a particular source or sink is in general determined by quality and cost considerations. On-chip sources and sinks provide better accuracy and performance related defect coverage, but at the same time increase the silicon area and hence might reduce manufacturing yield.
2. Test Access Mechanism
The test access mechanism takes care of on-chip test pattern transport. It can be used (1) to transport test stimuli from the test pattern source to the core-under-test, and (2) to transport test responses from the core-under-test to the test pattern sink. The test access mechanism is by definition, implemented on-chip. Although for one core often the same type of' test access mechanism is used for both stimulus as well as response transportation, this is not required and various combinations may co-exist. Designing a test access mechanism involves making a tradeoff between the transport capacity (bandwidth) of the mechanism and the test application cost it induces. The bandwidth is limited by the bandwidth of source and sink and the amount of silicon area one wants to spend on the test access mechanism itself.
3. Core Test Wrapper
The core test wrapper forms the interface between the embedded core and its system chip environment. It connects the core terminals both to the rest of the IC, as well as to the test access mechanism. By definition, the core test wrapper is implemented on-chip. The core test wrapper should have the following mandatory modes.
- Normal operation (i.e., non-test) mode of' the core. In this mode, the core is connected to its system-IC environment and the wrapper is transparent.
- Core test mode. In this mode the test access mechanism is connected to the core, such that test stimuli can be applied at the core's inputs and responses can be observed at the core's outputs.
- Interconnect test mode. In this mode the test access mechanism is connected to the interconnect wiring and logic, such that test stimuli can be applied at the core's outputs and responses can be observed at the core's inputs.
Apart from these mandatory modes, a core test wrapper might have several optional modes, e.g., a detach mode to disconnect the core from its system chip environment and the test access mechanism, or a bypass mode for the test access mechanisms. Depending on the implementation of the test access mechanism, some of the above modes may coincide. For example, if the test access mechanism uses existing functionality, normal operation and core test mode may coincide.
Pre-designed cores have their own internal clock distribution system. Different cores have different clock propagation delays, which might result in clock skew for inter-core communication. The system-IC designer should take care of this clock skew issue in the functional communication between cores. However, clock skew might also corrupt the data transfer over the test access mechanism, especially if this mechanism is shared by multiple cores. The core test wrapper is the best place to have provisions for clock skew prevention in the test access paths between the cores.
In addition to the test integration and interdependence issues, the system chip composite test requires adequate test scheduling. Effective test scheduling for SOCs is challenging because it must address several conflicting goals: (1) total SOC testing time minimization, (2) power dissipation, (3) precedence constraints among tests and (4) area overhead constraints [2]. Also, test scheduling is necessary to run intra-core and inter-core tests in certain order not to impact the initialization and final contents of individual cores.
5. On-Line Te sting
On-line testing addresses the detection of operational faults, and is found in computers that support critical or high-availability applications [23]. The goal of on-line testing is to detect fault effects, that is, errors, and take appropriate corrective action. On-line testing can be performed by external or internal monitoring, using either hardware or software; internal monitoring is referred to as self-testing. Monitoring is internal if it takes place on the same substrate as the circuit under test (CUT); nowadays, this usually means inside a single IC—a system-on-a-chip (SOC).
There are four primary parameters to consider in the design of an on-line testing scheme:
- Error coverage (EC): This is defined as the fraction of all modeled errors that are detected, usually expressed in percent. Critical and highly available systems require very good error detection or error coverage to minimize the impact of errors that lead to system failure.
- Error latency (EL): This is the difference between the first time the error is activated and the first time it is detected. EL is affected by the time taken to perform a test and by how often tests are executed. A related parameter is fault latency (FL), defined as the difference between the onset of the fault and its detection. Clearly, FL ≥ EL, so when EL is difficult to determine, FL is often used instead.
- Space redundancy (SR): This is the extra hardware or firmware needed to perform on-line testing.
- Time redundancy (TR): This is the extra time needed to perform on-line testing.
An ideal on-line testing scheme would have 100% error coverage, error latency of 1 clock cycle, no space redundancy, and no time redundancy. It would require no redesign of the CUT, and impose no functional or structural restrictions on the CUT. To cover all of the fault types described earlier, two different modes of on-line testing are employed: concurrent testing which takes place during normal system operation, and non-concurrent testing which takes place while normal operation is temporarily suspended. These operating modes must often be overlapped to provide a comprehensive on-line testing strategy at acceptable cost.
|
50 videos|69 docs|65 tests
|
FAQs on Testing Embedded Systems - 1 - Embedded Systems (Web) - Computer Science Engineering (CSE)
| 1. What is an embedded system? |  |
| 2. What are the advantages of testing embedded systems? | |
| 3. What are some challenges in testing embedded systems? | |
| 4. What are the different testing techniques used for embedded systems? | |
| 5. What is the role of automated testing in embedded systems? | |



Previous Year Questions with Solutions
,Summary
,practice quizzes
,Viva Questions
,past year papers
,Objective type Questions
,Important questions
,Extra Questions
,Semester Notes
,Sample Paper
,Exam
,Testing Embedded Systems - 1 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,ppt
,Testing Embedded Systems - 1 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,MCQs
,Free
,Testing Embedded Systems - 1 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,mock tests for examination
,shortcuts and tricks
,study material
,video lectures
;


Testing Embedded Systems - 1 Free PDF Download
Importance of Testing Embedded Systems - 1
Testing Embedded Systems - 1 Notes
Testing Embedded Systems - 1 Computer Science Engineering (CSE) Questions
Study Testing Embedded Systems - 1 on the App
|
© EduRev
|
Education Revolution
|



|





