Field Programmable Gate Arrays & Applications - 2 | Embedded Systems (Web) - Computer Science Engineering (CSE) PDF Download
Antifuse Based
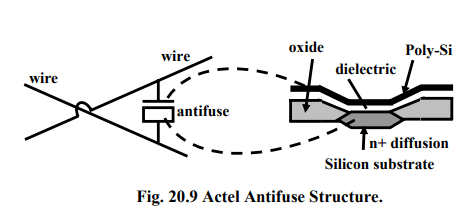
The antifuse based cell is the highest density interconnect by being a true cross point. Thus the designer has a much larger number of interconnects so logic modules can be smaller and more efficient. Place and route software also has a much easier time. These devices however are only one-time programmable and therefore have to be thrown out every time a change is made in the design. The Antifuse has an inherently low capacitance and resistance such that the fastest parts are all Antifuse based. The disadvantage of the antifuse is the requirement to integrate the fabrication of the antifuses into the IC process, which means the process will always lag the SRAM process in scaling. Antifuses are suitable for FPGAs because they can be built using modified CMOS technology. As an example, Actel’s antifuse structure is depicted in Fig. 20.9. The figure shows that an antifuse is positioned between two interconnect wires and physically consists of three sandwiched layers: the top and bottom layers are conductors, and the middle layer is an insulator. When unprogrammed, the insulator isolates the top and bottom layers, but when programmed the insulator changes to become a low-resistance link. It uses Poly-Si and n+ diffusion as conductors and ONO as an insulator, but other antifuses rely on metal for conductors, with amorphous silicon as the middle layer.
EEPROM Based
The EEPROM/FLASH cell in FPGAs can be used in two ways, as a control device as in an SRAM cell or as a directly programmable switch. When used as a switch they can be very efficient as interconnect and can be reprogrammable at the same time. They are also non-volatile so they do not require an extra PROM for loading. They, however, do have their detractions. The EEPROM process is complicated and therefore also lags SRAM technology.
Logic Block and Routing Techniques
Crosspoint FPGA: consist of two types of logic blocks. One is transistor pair tiles in which transistor pairs run in parallel lines as shown in figure below:
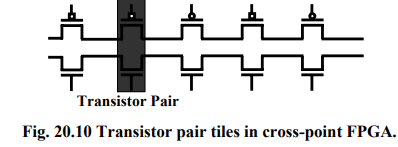
second type of logic blocks are RAM logic which can be used to implement random access memory.
Plessey FPGA: Basic building block here is 2-input NAND gate which is connected to each other to implement desired function.
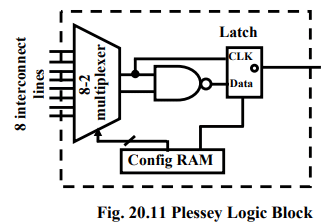
Both Crosspoint and Plessey are fine grain logic blocks. Fine grain logic blocks have an advantage in high percentage usage of logic blocks but they require large number of wire segments and programmable switches which occupy lot of area.
Actel Logic Block: If inputs of a multiplexer are connected to a constant or to a signal, it can be used to implement different logic functions. For example a 2-input multiplexer with inputs a and b, select, will implement function ac + bc´. If b=0 then it will implement ac, and if a=0 it will implement bc´.
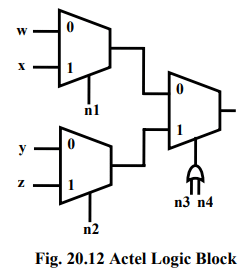
Typically an Actel logic block consists of multiple number of multiplexers and logic gates.
xilinix logic block
In Xilinx logic block Look up table is used to implement any number of different functionality. The input lines go into the input and enable of lookup table. The output of the lookup table gives the result of the logic function that it implements. Lookup table is implemented using SRAM
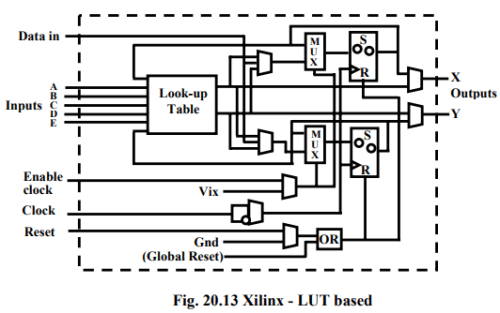
A k-input logic function is implemented using 2^k * 1 size SRAM. Number of different possible functions for k input LUT is 2^2^k. Advantage of such an architecture is that it supports implementation of so many logic functions, however the disadvantage is unusually large number of memory cells required to implement such a logic block in case number of inputs is large. Fig. 20.13 shows 5-input LUT based implementation of logic block LUT based design provides for better logic block utilization. A k-input LUT based logic block can be implemented in number of different ways with tradeoff between performance and logic density.
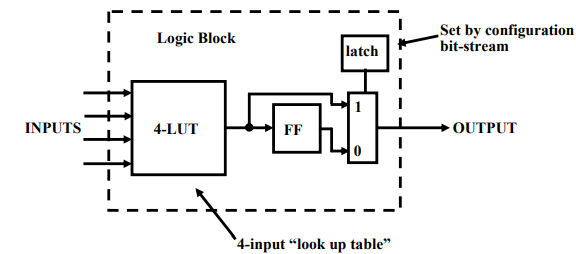
An n-lut can be shown as a direct implementation of a function truth-table. Each of the latch holds the value of the function corresponding to one input combination. For Example: 2-lut shown in figure below implements 2 input AND and OR functions.

Altera Logic Block
Altera's logic block has evolved from earlier PLDs. It consists of wide fan in (up to 100 input) AND gates feeding into an OR gate with 3-8 inputs. The advantage of large fan in AND gate based implementation is that few logic blocks can implement the entire functionality thereby reducing the amount of area required by interconnects. On the other hand disadvantage is the low density usage of logic blocks in a design that requires fewer input logic. Another disadvantage is the use of pull up devices (AND gates) that consume static power. To improve power manufacturers provide low power consuming logic blocks at the expense of delay. Such logic blocks have gates with high threshold as a result they consume less power. Such logic blocks can be used in non-critical paths. Altera, Xilinx are coarse grain architecture.
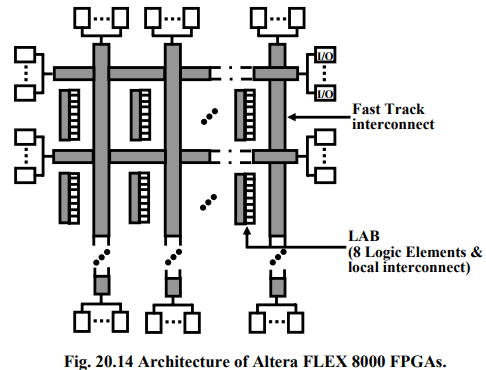
Example: Altera’s FLEX 8000 series consists of a three-level hierarchy. However, the lowest level of the hierarchy consists of a set of lookup tables, rather than an SPLD like block, and so the FLEX 8000 is categorized here as an FPGA. It should be noted, however, that FLEX 8000 is a combination of FPGA and CPLD technologies. FLEX 8000 is SRAM-based and features a four-input LUT as its basic logic block. Logic capacity ranges from about 4000 gates to more than 15,000 for the 8000 series. The overall architecture of FLEX 8000 is illustrated in Fig. 20.14.
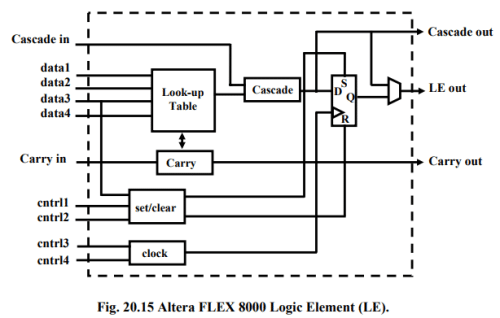
The basic logic block, called a Logic Element (LE) contains a four-input LUT, a flip-flop, and special-purpose carry circuitry for arithmetic circuits. The LE also includes cascade circuitry that allows for efficient implementation of wide AND functions. Details of the LE are illustrated in Fig. 20.15.
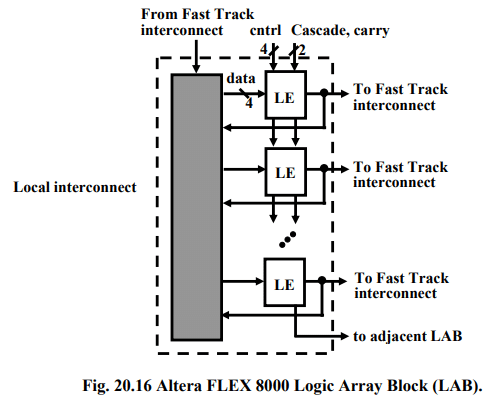
In the FLEX 8000, LEs are grouped into sets of 8, called Logic Array Blocks (LABs, a term borrowed from Altera’s CPLDs). As shown in Fig. 20.16, each LAB contains local interconnect and each local wire can connect any LE to any other LE within the same LAB. Local interconnect also connects to the FLEX 8000’s global interconnect, called FastTrack. All FastTrack wires horizontal wires are identical, and so interconnect delays in the FLEX 8000 are more predictable than FPGAs that employ many smaller length segments because there are fewer programmable switches in the longer path
FPGA Design
Flow One of the most important advantages of FPGA based design is that users can design it using CAD tools provided by design automation companies. Generic design flow of an FPGA includes following steps:
System Design
At this stage designer has to decide what portion of his functionality has to be implemented on FPGA and how to integrate that functionality with rest of the system.
I/O integration with rest of the system
Input Output streams of the FPGA are integrated with rest of the Printed Circuit Board, which allows the design of the PCB early in design process. FPGA vendors provide extra automation software solutions for I/O design process.
Design Description
Designer describes design functionality either by using schematic editors or by using one of the various Hardware Description Languages (HDLs) like Verilog or VHDL.
Synthesis
Once design has been defined CAD tools are used to implement the design on a given FPGA. Synthesis includes generic optimization, slack optimizations, power optimizations followed by placement and routing. Implementation includes Partition, Place and route. The output of design implementation phase is bit-stream file.
Design Verification
Bit stream file is fed to a simulator which simulates the design functionality and reports errors in desired behavior of the design. Timing tools are used to determine maximum clock frequency of the design. Now the design is loading onto the target FPGA device and testing is done in real environment.
Hardware design and development
The process of creating digital logic is not unlike the embedded software development process. A description of the hardware's structure and behavior is written in a high-level hardware description language (usually VHDL or Verilog) and that code is then compiled and downloaded prior to execution. Of course, schematic capture is also an option for design entry, but it has become less popular as designs have become more complex and the language-based tools have improved. The overall process of hardware development for programmable logic is shown in Fig. 20.17 and described in the paragraphs that follow. Perhaps the most striking difference between hardware and software design is the way a developer must think about the problem. Software developers tend to think sequentially, even when they are developing a multithreaded application. The lines of source code that they write are always executed in that order, at least within a given thread. If there is an operating system it is used to create the appearance of parallelism, but there is still just one execution engine. During design entry, hardware designers must think-and program-in parallel. All of the input signals are processed in parallel, as they travel through a set of execution engines-each one a series of macrocells and interconnections-toward their destination output signals. Therefore, the statements of a hardware description language create structures, all of which are "executed" at the very same time. Version 2
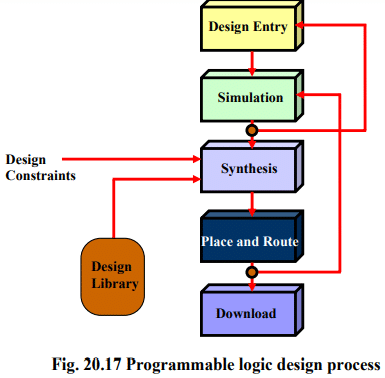
Typically, the design entry step is followed or interspersed with periods of functional simulation. That's where a simulator is used to execute the design and confirm that the correct outputs are produced for a given set of test inputs. Although problems with the size or timing of the hardware may still crop up later, the designer can at least be sure that his logic is functionally correct before going on to the next stage of development. Compilation only begins after a functionally correct representation of the hardware exists. This hardware compilation consists of two distinct steps. First, an intermediate representation of the hardware design is produced. This step is called synthesis and the result is a representation called a netlist. The netlist is device independent, so its contents do not depend on the particulars of the FPGA or CPLD; it is usually stored in a standard format called the Electronic Design Interchange Format (EDIF). The second step in the translation process is called place & route. This step involves mapping the logical structures described in the netlist onto actual macrocells, interconnections, and input and output pins. This process is similar to the equivalent step in the development of a printed circuit board, and it may likewise allow for either automatic or manual layout optimizations. The result of the place & route process is a bitstream. This name is used generically, despite the fact that each CPLD or FPGA (or family) has its own, usually proprietary, bitstream format. Suffice it to say that the bitstream is the binary data that must be loaded into the FPGA or CPLD to cause that chip to execute a particular hardware design. Increasingly there are also debuggers available that at least allow for single-stepping the hardware design as it executes in the programmable logic device. But those only complement a simulation environment that is able to use some of the information generated during the place & route step to provide gate-level simulation. Obviously, this type of integration of device-specific information into a generic simulator requires a good working relationship between the chip and simulation tool vendors.
|
47 videos|69 docs|65 tests
|
FAQs on Field Programmable Gate Arrays & Applications - 2 - Embedded Systems (Web) - Computer Science Engineering (CSE)
| 1. What is a Field Programmable Gate Array (FPGA)? |  |
| 2. What are the advantages of using Field Programmable Gate Arrays? | |
| 3. What are some common applications of Field Programmable Gate Arrays? | |
| 4. How do Field Programmable Gate Arrays differ from Application-Specific Integrated Circuits (ASICs)? | |
| 5. How can one program and configure a Field Programmable Gate Array? | |

|
4.81/5 Rating |

|
Dec 22, 2024 Last updated |

|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
shortcuts and tricks
,ppt
,Field Programmable Gate Arrays & Applications - 2 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,practice quizzes
,Exam
,Extra Questions
,past year papers
,study material
,Objective type Questions
,Field Programmable Gate Arrays & Applications - 2 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,Field Programmable Gate Arrays & Applications - 2 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,mock tests for examination
,Sample Paper
,Free
,Semester Notes
,Previous Year Questions with Solutions
,Summary
,video lectures
,Viva Questions
,MCQs
,Important questions
;






Field Programmable Gate Arrays & Applications - 2 Free PDF Download
Importance of Field Programmable Gate Arrays & Applications - 2
Field Programmable Gate Arrays & Applications - 2 Notes
Field Programmable Gate Arrays & Applications - 2 Computer Science Engineering (CSE) Questions
Study Field Programmable Gate Arrays & Applications - 2 on the App
|
© EduRev
|
Education Revolution
|



|




