Concepts in Real Time Operating Systems - 2 | Embedded Systems (Web) - Computer Science Engineering (CSE) PDF Download
Dynamic Priority Levels
In Unix systems real-time tasks can not be assigned static priority values. Soon after a programmer sets a priority value, the operating system alters it. This makes it very difficult to schedule real-time tasks using algorithms such as RMA or EDF, since both these schedulers assume that once task priorities are assigned, it should not be altered by any other parts of the operating system. It is instructive to understand why Unix dynamically changes the priority values of tasks in the first place.
Unix uses round-robin scheduling with multilevel feedback. This scheduler arranges tasks in multilevel queues as shown in Fig. 31.4. At every preemption point, the scheduler scans the multilevel queue from the top (highest priority) and selects the task at the head of the first non-empty queue. Each task is allowed to run for a fixed time quantum (or time slice) at a time. Unix normally uses one second time slice. That is, if the running process does not block or complete within one second of its starting execution, it is preempted and the scheduler selects the next task for dispatching. Unix system however allows configuring the default one second time slice during system generation. The kernel preempts a process that does not complete within its assigned time quantum, recomputes its priority, and inserts it back into one of the priority queues depending on the recomputed priority value of the task.
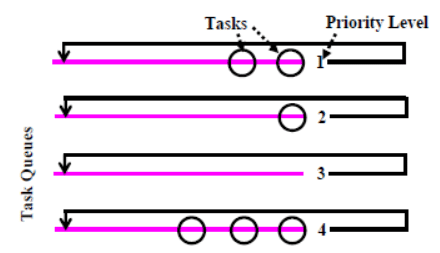
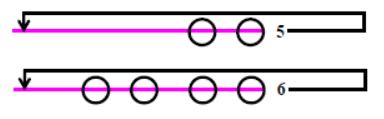
Fig. 31.4 Multi-Level Feedback Queues
Unix periodically computes the priority of a task based on the type of the task and its execution history. The priority of a task (Ti) is recomputed at the end of its j-th time slice using the following two expressions:
Pr(Ti, j) = Base(Ti) + CPU(Ti, j) + nice(Ti) …(4.1)
CPU(Ti, j) = U(Ti, j−1) / 2 + CPU(Ti, j−1) / 2 …(4.2)
where Pr(Ti, j) is the priority of the task Ti at the end of its j-th time slice; U(Ti , j) is the utilization of the task Ti for its j-th time slice, and CPU(Ti , j) is the weighted history of CPU utilization of the task Ti at the end of its j-th time slice. Base(Ti) is the base priority of the task Ti and nice(Ti) is the nice value associated with Ti. User processes can have non-negative nice values. Thus, effectively the nice value lowers the priority value of a process (i.e. being nice to the other processes).
Expr. 4.2 has been recursively defined. Unfolding the recursion, we get:
CPU(Ti, j) = U(Ti, j−1) / 2 + U(Ti, j−2) / 4 + ……(4.3)
It can be easily seen from Expr. 4.3 that, in the computation of the weighted history of CPU utilization of a task, the activity (i.e. processing or I/O) of the task in the immediately concluded interval is given the maximum weightage. If the task used up CPU for the full duration of the slice (i.e. 100% CPU utilization), then CPU(Ti, j) gets a higher value indicating a lower priority. Observe that the activities of the task in the preceding intervals get progressively lower weightage. It should be clear that CPU(Ti, j) captures the weighted history of CPU utilization of the task Ti at the end of its j-th time slice.
Now, substituting Expr 4.3 in Expr. 4.1, we get:
Pr(Ti, j) = Base(Ti) + U(Ti, j−1) / 2 + U(Ti, j−2) / 4 + … + nice(Ti) … (4.4)
The purpose of the base priority term in the priority computation expression (Expr. 4.4) is to divide all tasks into a set of fixed bands of priority levels. The values of U(Ti , j) and nice components are restricted to be small enough to prevent a process from migrating from its assigned band. The bands have been designed to optimize I/O, especially block I/O. The different priority bands under Unix in decreasing order of priorities are: swapper, block I/O, file manipulation, character I/O and device control, and user processes. Tasks performing block I/O are assigned the highest priority band. To give an example of block I/O, consider the I/O that occurs while handling a page fault in a virtual memory system. Such block I/O use DMA-based transfer, and hence make efficient use of I/O channel. Character I/O includes mouse and keyboard transfers. The priority bands were designed to provide the most effective use of the I/O channels.
Dynamic re-computation of priorities was motivated from the following consideration. Unix designers observed that in any computer system, I/O is the bottleneck. Processors are extremely fast compared to the transfer rates of I/O devices. I/O devices such as keyboards are necessarily slow to cope up with the human response times. Other devices such as printers and disks deploy mechanical components that are inherently slow and therefore can not sustain very high rate of data transfer. Therefore, effective use of the I/O channels is very important to increase the overall system throughput. The I/O channels should be kept as busy as possible for letting the interactive tasks to get good response time. To keep the I/O channels busy, any task performing I/O should not be kept waiting for CPU. For this reason, as soon as a task blocks for I/O, its priority is increased by the priority re-computation rule given in Expr. 4.4. However, if a task makes full use of its last assigned time slice, it is determined to be computation-bound and its priority is reduced. Thus the basic philosophy of Unix operating system is that the interactive tasks are made to assume higher priority levels and are processed at the earliest. This gives the interactive users good response time. This technique has now become an accepted way of scheduling soft real-time tasks across almost all available general purpose operating systems.
We can now state from the above observations that the overall effect of re-computation of priority values using Expr. 4.4 as follows:
| In Unix, I/O intensive tasks migrate to higher and higher priorities, whereas CPU-intensive tasks seek lower priority levels. |
No doubt that the approach taken by Unix is very appropriate for maximizing the average task throughput, and does indeed provide good average responses time to interactive (soft real-time) tasks. In fact, almost every modern operating system does very similar dynamic re-computation of the task priorities to maximize the overall system throughput and to provide good average response time to the interactive tasks. However, for hard real-time tasks, dynamic shifting of priority values is clearly not appropriate.
Other Deficiencies of Unix
We have so far discussed two glaring shortcomings of Unix in handling the requirements of real-time applications. We now discuss a few other deficiencies of Unix that crop up while trying to use Unix in real-time applications.
Insufficient Device Driver Support: In Unix, (remember that we are talking of the original Unix System V) device drivers run in kernel mode. Therefore, if support for a new device is to be added, then the driver module has to be linked to the kernel modules – necessitating a system generation step. As a result, providing support for a new device in an already deployed application is cumbersome.
Lack of Real-Time File Services: In Unix, file blocks are allocated as and when they are requested by an application. As a consequence, while a task is writing to a file, it may encounter an error when the disk runs out of space. In other words, no guarantee is given that disk space would be available when a task writes a block to a file. Traditional file writing approaches also result in slow writes since required space has to be allocated before writing a block. Another problem with the traditional file systems is that blocks of the same file may not be contiguously located on the disk. This would result in read operations taking unpredictable times, resulting in jitter in data access. In real-time file systems significant performance improvement can be achieved by storing files contiguously on the disk. Since the file system pre-allocates space, the times for read and write operations are more predictable.
Inadequate Timer Services Support: In Unix systems, real-time timer support is insufficient for many hard real-time applications. The clock resolution that is provided to applications is 10 milliseconds, which is too coarse for many hard real-time applications.
Unix-based Real-Time Operating Systems
We have already seen in the previous section that traditional Unix systems are not suitable for being used in hard real-time applications. In this section, we discuss the different approaches that have been undertaken to make Unix suitable for real-time applications.
Extensions To The Traditional Unix Kernel
A naive attempted in the past to make traditional Unix suitable for real-time applications was by adding some real-time capabilities over the basic kernel. These additionally implemented capabilities included real-time timer support, a real-time task scheduler built over the Unix scheduler, etc. However, these extensions do not address the fundamental problems with the Unix system that were pointed out in the last section; namely, non-preemptive kernel and dynamic priority levels. No wonder that superficial extensions to the capabilities of the Unix kernel without addressing the fundamental deficiencies of the Unix system would fall wide short of the requirements of hard real-time applications.
Host-Target Approach
Host-target operating systems are popularly being deployed in embedded applications. In this approach, the real- time application development is done on a host machine. The host machine is either a traditional Unix operating system or an Windows system. The real-time application is developed on the host and the developed application is downloaded onto a target board that is to be embedded in a real-time system. A ROM-resident small real-time kernel is used in the target board. This approach has schematically been shown in Fig. 31.5.
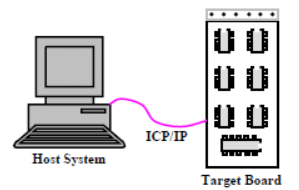
Fig. 31.5 Schematic Representation of a Host-Target System
The main idea behind this approach is that the real-time operating system running on the target board be kept as small and simple as possible. This implies that the operating system on the target board would lack virtual memory management support, neither does it support any utilities such as compilers, program editors, etc. The processor on the target board would run the real-time operating system.
The host system must have the program development environment, including compilers, editors, library, cross-compilers, debuggers etc. These are memory demanding applications that require virtual memory support. The host is usually connected to the target using a serial port or a TCP/IP connection (see Fig. 31.5). The real-time program is developed on the host. It is then cross-compiled to generate code for the target processor. Subsequently, the executable module is downloaded to the target board. Tasks are executed on the target board and the execution is controlled at the host side using a symbolic cross-debugger. Once the program works successfully, it is fused on a ROM or flash memory and becomes ready to be deployed in applications.
Commercial examples of host-target real-time operating systems include PSOS, VxWorks, and VRTX. We examine these commercial products in lesson 5. We would point out that these operating systems, due to their small size, limited functionality, and optimal design achieve much better performance figures than full-fledged operating systems. For example, the task preemption times of these systems are of the order of few microseconds compared to several hundreds of milliseconds for traditional Unix systems.
Preemption Point Approach
We have already pointed out that one of the major shortcomings of the traditional Unix V code is that during a system call, all interrupts are masked(disabled) for the entire duration of execution of the system call. This leads to unacceptable worst case task response time of the order of second, making Unix-based systems unacceptable for most hard real-time applications.
An approach that has been taken by a few vendors to improve the real-time performance of non-preemptive kernels is the introduction of preemption points in system routines. Preemption points in the execution of a system routine are the instants at which the kernel data structures are consistent. At these points, the kernel can safely be preempted to make way for any waiting higher priority real-time tasks without corrupting any kernel data structures. In this approach, when the execution of a system call reaches a preemption point, the kernel checks to see if any higher priority tasks have become ready.
If there is at least one, it preemptsthe processing of the kernel routine and dispatches the waiting highest priority task immediately. The worst-case preemption latency in this technique therefore becomes the longest time between two consecutive preemption points. As a result, the worst-case response times of tasks are now several folds lower than those for traditional operating systems without preemption points. This makes the preemption point-based operating systems suitable for use in many categories hard real-time applications, though still not suitable for applications requiring preemption latency of the order of a few micro seconds or less. Another advantage of this approach is that it involves only minor changes to be made to the kernel code. Many operating systems have taken the preemption point approach in the past, a prominent example being HP-UX.
|
47 videos|69 docs|65 tests
|

|
4.93/5 Rating |

|
Dec 25, 2024 Last updated |

|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
Viva Questions
,mock tests for examination
,shortcuts and tricks
,video lectures
,past year papers
,Semester Notes
,Free
,Concepts in Real Time Operating Systems - 2 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,Important questions
,Objective type Questions
,Extra Questions
,study material
,Previous Year Questions with Solutions
,Summary
,Exam
,practice quizzes
,Concepts in Real Time Operating Systems - 2 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,Sample Paper
,Concepts in Real Time Operating Systems - 2 | Embedded Systems (Web) - Computer Science Engineering (CSE)
,ppt
,MCQs
;






Concepts in Real Time Operating Systems - 2 Free PDF Download
Importance of Concepts in Real Time Operating Systems - 2
Concepts in Real Time Operating Systems - 2 Notes
Concepts in Real Time Operating Systems - 2 Computer Science Engineering (CSE) Questions
Study Concepts in Real Time Operating Systems - 2 on the App
|
© EduRev
|
Education Revolution
|



|




