Functional Dependency


Functional Dependency
Functional dependency is a constraint between two sets of attributes in a relation. A functional dependency X → Y holds on a relation if, for any two tuples in the relation, whenever the values of attributes in X are the same, the values of attributes in Y are also the same. In other words, X uniquely determines Y.
Simple example (STUDENT relation)
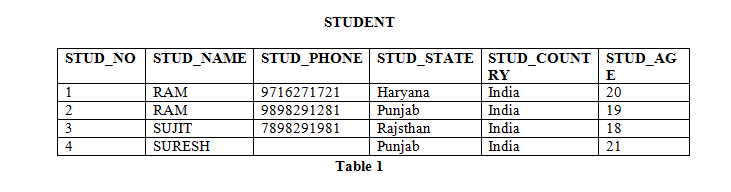
Consider a STUDENT relation with attributes such as STUD_NO, STUD_NAME, STUD_PHONE, STUD_STATE, STUD_COUNTRY, STUD_AGE. From the relation we can infer functional dependencies such as:
- STUD_NO → STUD_NAME
- STUD_NO → STUD_PHONE
- STUD_NO → STUD_STATE
- STUD_NO → STUD_COUNTRY
- STUD_NO → STUD_AGE
However, STUD_NAME → STUD_ADDR need not hold if two students share the same name but live at different addresses.
How to find functional dependencies for a relation
Functional dependencies depend on the semantics (domain and meaning) of attributes of the relation, not merely on the data instance. Typical determinations:
- If an attribute is known to be unique for each entity (for example, a student number), then that attribute functionally determines other attributes describing the entity: if STUD_NO is unique then STUD_NO → (all other student attributes) holds.
- If one attribute is a function of another by domain knowledge (for example, state determines country in a dataset where each state belongs to exactly one country), then STUD_STATE → STUD_COUNTRY holds.
- For a COURSE relation, if COURSE_NO uniquely identifies the course, then COURSE_NO → COURSE_NAME holds.
Functional dependency set (FD set)
The FD set of a relation is the set of all functional dependencies that hold on that relation (as determined by domain knowledge and constraints). Example FD set for the STUDENT relation above:
{ STUD_NO → STUD_NAME, STUD_NO → STUD_PHONE, STUD_NO → STUD_STATE, STUD_NO → STUD_COUNTRY, STUD_NO → STUD_AGE, STUD_STATE → STUD_COUNTRY }
Attribute closure
Attribute closure of an attribute set X, denoted X+, is the set of all attributes that can be functionally determined from X using a given set of functional dependencies.
Procedure to compute the closure X+ given an FD set F:
- Start with result set S = X.
- Repeatedly add any attributes Y to S for which there exists a functional dependency U → V in F with U ⊆ S and V ⊆ S ∪ V, until no more attributes can be added.
Examples using the STUDENT FD set:
(STUD_NO)+ = {STUD_NO, STUD_NAME, STUD_PHONE, STUD_STATE, STUD_COUNTRY, STUD_AGE}
(STUD_STATE)+ = {STUD_STATE, STUD_COUNTRY}
Super keys and candidate keys (using closure)
- A set of attributes X is a super key of relation R if X+ contains all attributes of R.
- X is a candidate key if X is a super key and no proper subset of X is a super key (i.e., X is minimal).
Example: If (STUD_NO)+ contains all attributes of STUDENT, then STUD_NO is a super key. If no subset of STUD_NO (there is none) is a super key, it is also a candidate key. If (STUD_NO, STUD_NAME)+ also contains all attributes but STUD_NO alone already does, then (STUD_NO, STUD_NAME) is a super key but not a candidate key.
Checking whether an FD is implied by an FD set
To check whether a functional dependency A → B is implied by an FD set F, compute A+ using F. If B ⊆ A+, then A → B is implied by F; otherwise it is not.
Worked GATE-style problems (preserve original question statements)
Q. Consider the relation scheme R = {E, F, G, H, I, J, K, L, M, M} and the set of functional dependencies {{E, F} → {G}, {F} → {I, J}, {E, H} → {K, L}, K → {M}, L → {N} on R. What is the key for R? (GATE-CS-2014)
(a) {E, F}
(b) {E, F, H}
(c) {E, F, H, K, L}
(d) {E}
Ans: (b)
Solution: Finding attribute closure of all given options, we get:
{E, F}+ = {E F G I J}
{E, F, H}+ = {E F H G I J K L M N}
{E, F, H, K, L}+ = {{E F H G I J K L M N}
{E}+ = {E}
{EFH}+ and {EFHKL}+ results in set of all attributes, but EFH is minimal. So it will be candidate key. So correct option is (b).
Prime and non-prime attributes
Prime attributes are attributes that are part of some candidate key of the relation. Non-prime attributes are attributes that are not part of any candidate key. Example: in the STUDENT relation, if STUD_NO is the candidate key, then STUD_NO is prime and other attributes are non-prime.
Another worked example and important definitions (EMPLOYEE relation)
What is Functional Dependency? A functional dependency X → Y holds if two tuples having the same value for X also have the same value for Y, i.e., X uniquely determines Y.
In an EMPLOYEE relation (example attributes: E-ID, E-NAME, E-CITY, E-STATE):
- E-ID → E-NAME holds because each E-ID corresponds to a unique E-NAME.
- E-ID → E-CITY and E-CITY → E-STATE may hold if cities uniquely determine states in the given dataset.
- E-NAME → E-ID does not hold if the same name (for example, 'John') can correspond to multiple E-IDs.
The FD set for this EMPLOYEE example might be:
{ E-ID → E-NAME, E-ID → E-CITY, E-ID → E-STATE, E-CITY → E-STATE }
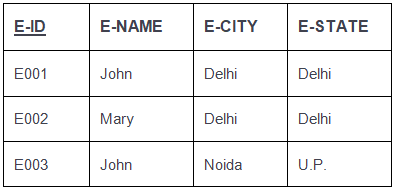
Table 1
Trivial versus non-trivial functional dependency
A functional dependency X → Y is trivial if Y ⊆ X (that is, the right-hand side is a subset of the left-hand side). Trivial FDs always hold for any relation instance.
Example: {E-ID, E-NAME} → E-ID is trivial because {E-ID} ⊆ {E-ID, E-NAME}.
Any FD that is not trivial is called non-trivial. For example, E-ID → E-NAME is non-trivial and may hold depending on semantics.
Properties of functional dependencies (Armstrong's axioms)
Let X, Y and Z be attribute sets. The following properties always hold and form a sound and complete inference system for FDs.
- Reflexivity: If Y ⊆ X then X → Y.
- Augmentation: If X → Y then XZ → YZ (for any Z).
- Transitivity: If X → Y and Y → Z then X → Z.
From these axioms we can derive useful rules such as union, decomposition and pseudo-transitivity:
- Union: If X → Y and X → Z then X → YZ.
- Decomposition: If X → YZ then X → Y and X → Z.
- Pseudo-transitivity: If X → Y and YZ → W then XZ → W.
Attribute closure: step-by-step example
Given R(E-ID, E-NAME, E-CITY, E-STATE) and FDs = { E-ID → E-NAME, E-ID → E-CITY, E-ID → E-STATE, E-CITY → E-STATE }.
Compute (E-ID)+:
Add E-ID to the set: {E-ID}.
From E-ID → E-NAME add E-NAME: {E-ID, E-NAME}.
From E-ID → E-CITY add E-CITY: {E-ID, E-NAME, E-CITY}.
From E-ID → E-STATE add E-STATE: {E-ID, E-NAME, E-CITY, E-STATE}.
No further attributes can be added, so (E-ID)+ = {E-ID, E-NAME, E-CITY, E-STATE}.
Similarly:
(E-NAME)+ = {E-NAME}
(E-CITY)+ = {E-CITY, E-STATE}
Worked closure example with R(ABCDE)
Q. Find the attribute closures of given FDs R(ABCDE) = {AB → C, B → D, C → E, D → A}
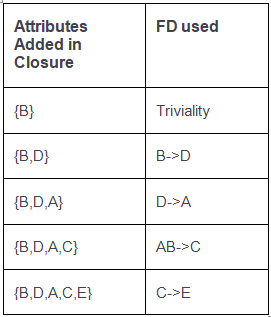
- (C, D)+: start with {C, D}; from C → E add E; from D → A add A; closure is {C, D, E, A}.
- (B, C)+: start with {B, C}; from B → D add D; from C → E add E; from D → A add A; closure is {B, C, D, E, A} (all attributes).
Candidate keys and super keys - more formal view
Candidate key: a minimal set of attributes that functionally determines every attribute in the relation.
Super key: any set of attributes that functionally determines every attribute in the relation (not necessarily minimal).
To find candidate keys using closures:
- Choose a set of attributes X.
- Compute X+ using the FD set. If X+ includes all attributes of R, X is a super key.
- If X is a super key and no proper subset of X is a super key, X is a candidate key.
Example for EMPLOYEE with FDs {E-ID → E-NAME, E-ID → E-CITY, E-ID → E-STATE, E-CITY → E-STATE}:
- (E-ID)+ = {E-ID, E-NAME, E-CITY, E-STATE} so (E-ID) is a super key and minimal, therefore a candidate key.
- (E-ID, E-NAME)+ is also a super key but not minimal (since E-ID alone suffices), so it is not a candidate key.
Canonical cover (minimal cover) and extraneous attributes
Extraneous attribute: an attribute A is extraneous in X of X → Y (with respect to FD set F) if removing A from X produces an FD that is implied by F. In that case X can be replaced by X \ {A} in the FD without changing the closure of F.
Canonical (minimal) cover of an FD set F is an equivalent set of dependencies G such that:
- Every dependency in G has a single attribute on the right-hand side.
- No FD in G contains extraneous attributes on the left-hand side.
- No FD in G can be removed without changing the closure (i.e., G is minimal).
Algorithm to compute a canonical cover (informal):
- Step 1: Split FDs so that each FD has a single attribute on the right-hand side.
- Step 2: For each FD X → A, test each attribute B in X for extraneousness by checking if (X \ {B}) → A is implied by the current FD set; if yes, remove B from X.
- Step 3: Remove redundant FDs: for each FD in the set, check whether it is implied by the remaining FDs; if yes, remove it.
- Step 4: Optionally, combine FDs with the same left-hand side into single FDs with multiple attributes on the right.
Lossless-join decomposition and dependency preservation
Functional dependencies are central to decomposition and normalization. Two desirable properties of a decomposition of R into R1 and R2 are:
- Lossless-join decomposition: The natural join of R1 and R2 yields exactly R (no spurious tuples). A sufficient and necessary condition for decomposition R → (R1, R2) to be lossless (using FDs) is that the common attributes of R1 and R2 form a super key for at least one of R1 or R2 (checked using closures).
- Dependency preservation: After decomposition, all original FDs should be enforceable by enforcing FDs locally on the decomposed relations without requiring the expensive computation of joins. A decomposition that preserves all dependencies is said to be dependency preserving.
Important exam-oriented techniques and tips
- Always use attribute closure to check whether a set of attributes is a super key or whether an FD is implied by an FD set.
- When multiple-choice questions ask for candidate keys, compute closures of minimal attribute combinations; start with attributes that do not appear on right-hand sides (they are likely part of keys).
- Use Armstrong's axioms and derived rules (union, decomposition, pseudo-transitivity) to infer new dependencies or to test implication.
- For canonical cover computations, split right-hand sides first, then remove extraneous attributes, then remove redundant FDs, and finally merge where useful.
Additional GATE-style questions (preserve original question statements)
Q. In a schema with attributes A, B, C, D and E following set of functional dependencies are given
{A → B, A → C, CD → E, B → D, E → A}
Which of the following functional dependencies is NOT implied by the above set? (GATE IT 2005)
(a) CD → AC
(b) BD → CD
(c) BC → CD
(d) AC → BC
Ans: (b)
Solution: Using FD set given in question,
(CD)+ = {C D E A B} which means CD → AC also holds true.
(BD)+ = {B D} which means BD → CD can't hold true. So this FD is not implied in the FD set.
So (B) is the required option.
Others can be checked in the same way.
Q. Consider a relation scheme R = (A, B, C, D, E, H) on which the following functional dependencies hold: {A → B, BC → D, E → C, D → A}. What are the candidate keys of R? [GATE 2005]
(a) AE, BE
(b) AE, BE, DE
(c) AEH, BEH, BCH
(d) AEH, BEH, DEH
Ans: (d)
Solution: (AE)+ = {A B E C D} which is not set of all attributes. So AE is not a candidate key.
Hence option A and B are wrong.
(AEH)+ = {A B C D E H}
(BEH)+ = {B E H C D A}
(BCH)+ = {B C H D A} which is not set of all attributes. So BCH is not a candidate key.
Hence option C is wrong.
So correct answer is D.
Summary
Functional dependencies capture semantic constraints that define how attribute values determine other attribute values. Mastery of computing attribute closures, finding candidate and super keys, deriving implied dependencies, computing canonical covers, and understanding how FDs affect normalization and decomposition (lossless-join and dependency preservation) is essential for database design and typical exam questions. Use systematic closure computations and Armstrong's axioms when solving problems.
FAQs on Functional Dependency
| 1. What is a functional dependency? |  |
| 2. How are functional dependencies useful in database design? | |
| 3. What is meant by a left-hand side and right-hand side in a functional dependency? | |
| 4. How can we represent functional dependencies in a database schema? | |
| 5. What is the difference between a functional dependency and a multivalued dependency? | |


 | Explore Courses for Computer Science Engineering (CSE) exam |
 | Get EduRev Notes directly in your Google search |