Computer Science Engineering (CSE) Exam > Computer Science Engineering (CSE) Notes > Database Management System (DBMS) > Indexing in Databases
Indexing in Databases | Database Management System (DBMS) - Computer Science Engineering (CSE) PDF Download

Indexing is a way to optimize the performance of a database by minimizing the number of disk accesses required when a query is processed. It is a data structure technique which is used to quickly locate and access the data in a database.
Indexes are created using a few database columns.
- The first column is the Search key that contains a copy of the primary key or candidate key of the table. These values are stored in sorted order so that the corresponding data can be accessed quickly.
Note: The data may or may not be stored in sorted order. - The second column is the Data Reference or Pointer which contains a set of pointers holding the address of the disk block where that particular key value can be found.
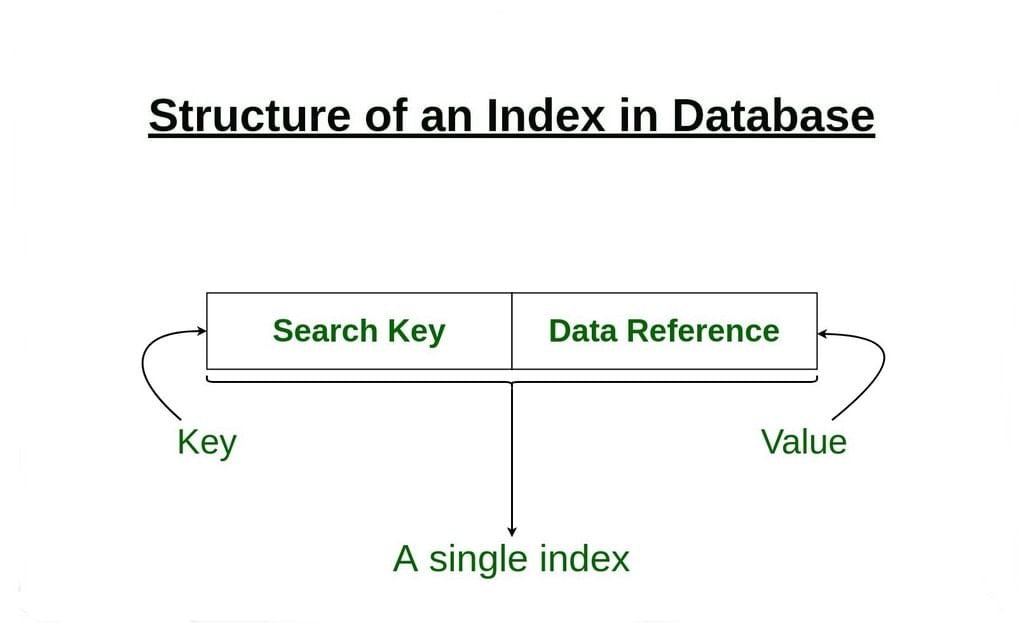
The indexing has various attributes:
- Access Types: This refers to the type of access such as value based search, range access, etc.
- Access Time: It refers to the time needed to find particular data element or set of elements.
- Insertion Time: It refers to the time taken to find the appropriate space and insert a new data.
- Deletion Time: Time taken to find an item and delete it as well as update the index structure.
- Space Overhead: It refers to the additional space required by the index.
In general, there are two types of file organization mechanism which are followed by the indexing methods to store the data:
- Sequential File Organization or Ordered Index File: In this, the indices are based on a sorted ordering of the values. These are generally fast and a more traditional type of storing mechanism. These Ordered or Sequential file organization might store the data in a dense or sparse format:
- Dense Index:
(i) For every search key value in the data file, there is an index record.
(ii) This record contains the search key and also a reference to the first data record with that search key value.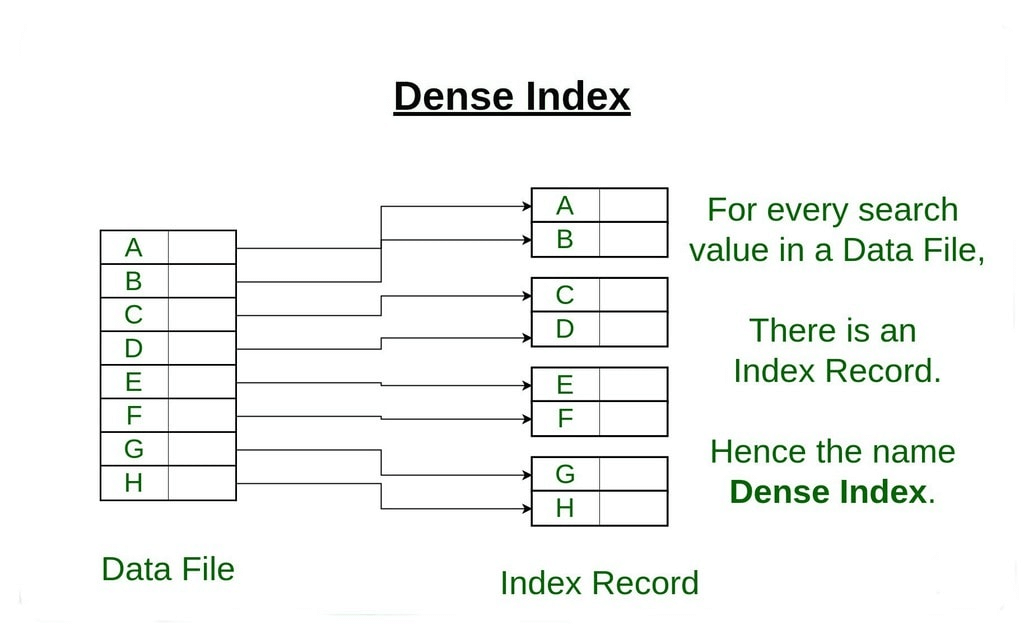
- Sparse Index:
(i) The index record appears only for a few items in the data file. Each item points to a block as shown.
(ii) To locate a record, we find the index record with the largest search key value less than or equal to the search key value we are looking for.
(iii) We start at that record pointed to by the index record, and proceed along with the pointers in the file (that is, sequentially) until we find the desired record.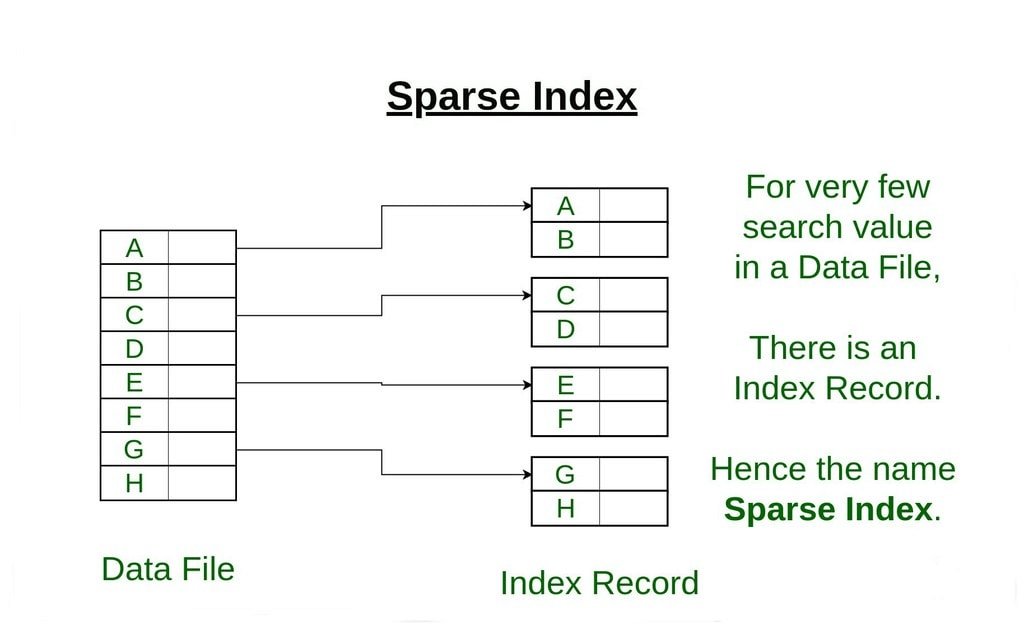
- Dense Index:
- Hash File organization: Indices are based on the values being distributed uniformly across a range of buckets. The buckets to which a value is assigned is determined by a function called a hash function.
There are primarily three methods of indexing:- Clustered Indexing
- Non-Clustered or Secondary Indexing
- Multilevel Indexing
(i) Clustered Indexing
When more than two records are stored in the same file these types of storing known as cluster indexing. By using the cluster indexing we can reduce the cost of searching reason being multiple records related to the same thing are stored at one place and it also gives the frequent joing of more than two tables(records).
Clustering index is defined on an ordered data file. The data file is ordered on a non-key field. In some cases, the index is created on non-primary key columns which may not be unique for each record. In such cases, in order to identify the records faster, we will group two or more columns together to get the unique values and create index out of them. This method is known as the clustering index. Basically, records with similar characteristics are grouped together and indexes are created for these groups.
For example, students studying in each semester are grouped together. i.e. 1st Semester students, 2nd semester students, 3rd semester students etc. are grouped.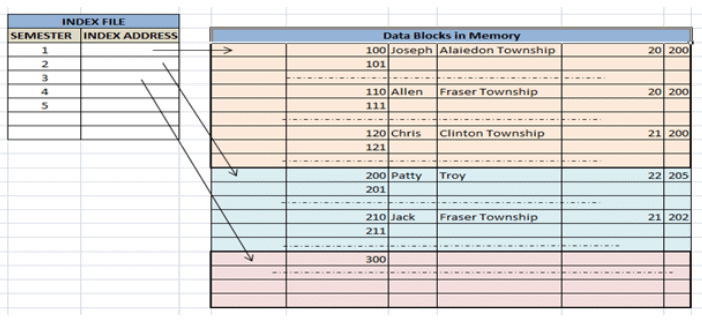 Clustered index sorted according to first name (Search key)
Clustered index sorted according to first name (Search key)
(a) Primary Indexing: This is a type of Clustered Indexing wherein the data is sorted according to the search key and the primary key of the database table is used to create the index. It is a default format of indexing where it induces sequential file organization. As primary keys are unique and are stored in a sorted manner, the performance of the searching operation is quite efficient.
(ii) Non-clustered or Secondary Indexing
A non clustered index just tells us where the data lies, i.e. it gives us a list of virtual pointers or references to the location where the data is actually stored. Data is not physically stored in the order of the index. Instead, data is present in leaf nodes. For eg. the contents page of a book. Each entry gives us the page number or location of the information stored. The actual data here(information on each page of the book) is not organized but we have an ordered reference(contents page) to where the data points actually lie. We can have only dense ordering in the non-clustered index as sparse ordering is not possible because data is not physically organized accordingly.
It requires more time as compared to the clustered index because some amount of extra work is done in order to extract the data by further following the pointer. In the case of a clustered index, data is directly present in front of the index. (iii) Multilevel Indexing
(iii) Multilevel Indexing
With the growth of the size of the database, indices also grow. As the index is stored in the main memory, a single-level index might become too large a size to store with multiple disk accesses. The multilevel indexing segregates the main block into various smaller blocks so that the same can stored in a single block. The outer blocks are divided into inner blocks which in turn are pointed to the data blocks. This can be easily stored in the main memory with fewer overheads.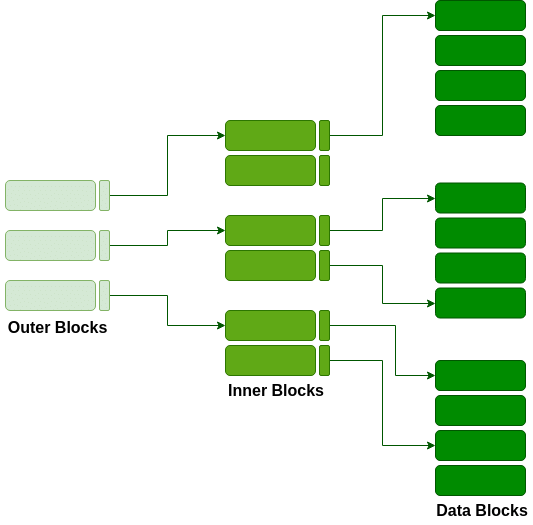
The document Indexing in Databases | Database Management System (DBMS) - Computer Science Engineering (CSE) is a part of the Computer Science Engineering (CSE) Course Database Management System (DBMS).
All you need of Computer Science Engineering (CSE) at this link: Computer Science Engineering (CSE)
|
63 videos|93 docs|37 tests
|
FAQs on Indexing in Databases - Database Management System (DBMS) - Computer Science Engineering (CSE)
| 1. What is indexing in databases? |  |
Ans. Indexing in databases is a technique used to improve the speed and efficiency of data retrieval operations. It involves creating a separate data structure, called an index, which contains a subset of the data from the main database table. This index allows for faster searching and sorting of data based on specific columns or fields.
| 2. Why is indexing important in databases? | |
Ans. Indexing is important in databases because it significantly improves the performance of data retrieval operations. By creating indexes on frequently queried columns, the database can quickly locate the desired data without having to scan the entire table. This leads to faster query execution times and enhances the overall efficiency of the database system.
| 3. How does indexing work in databases? | |
Ans. Indexing works by creating a separate data structure, known as an index, which contains a subset of the data from the main database table. This index is typically stored in a separate file or memory structure. When a query is executed, the database engine uses the index to quickly locate the relevant data based on the specified search criteria. This avoids the need for a full table scan and significantly speeds up the data retrieval process.
| 4. What are the different types of indexes in databases? | |
Ans. There are several types of indexes commonly used in databases, including:
1. B-tree index: This is the most common type of index, suitable for range queries and equality searches.
2. Hash index: This type of index is efficient for exact match queries but not suitable for range queries.
3. Bitmap index: It is suitable for columns with a small number of distinct values and is commonly used in data warehousing.
4. Clustered index: This type of index determines the physical order of data in a table and is particularly useful for improving the performance of frequently used queries.
5. Non-clustered index: Unlike clustered indexes, non-clustered indexes do not determine the physical order of data and are typically used for improving query performance on columns that are not frequently updated.
| 5. How can I create an index in a database? | |
Ans. To create an index in a database, you need to use specific SQL statements or commands provided by the database management system (DBMS) you are using. Generally, you would use the CREATE INDEX statement followed by the name of the index, the table name, and the column(s) on which the index is to be created. The DBMS will then create the index and associate it with the specified table, improving the performance of data retrieval operations on the indexed column(s).
About this Document

4.87/5
Rating

Sep 21, 2025
Last updated
Related Exams
Document Description: Indexing in Databases for Computer Science Engineering (CSE) 2025 is part of Database Management System (DBMS) preparation.
The notes and questions for Indexing in Databases have been prepared according to the Computer Science Engineering (CSE) exam syllabus. Information about Indexing in Databases covers topics
like and Indexing in Databases Example, for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises and tests below for Indexing in Databases.
Introduction of Indexing in Databases in English is available as part of our Database Management System (DBMS)
for Computer Science Engineering (CSE) & Indexing in Databases in Hindi for Database Management System (DBMS) course.
Download more important topics related with notes, lectures and mock test series for Computer Science Engineering (CSE)
Exam by signing up for free. Computer Science Engineering (CSE): Indexing in Databases | Database Management System (DBMS) - Computer Science Engineering (CSE)
Description
Full syllabus notes, lecture & questions for Indexing in Databases | Database Management System (DBMS) - Computer Science Engineering (CSE) - Computer Science Engineering (CSE) | Plus excerises question with solution to help you revise complete syllabus for Database Management System (DBMS) | Best notes, free PDF download
Information about Indexing in Databases
In this doc you can find the meaning of Indexing in Databases defined & explained in the simplest way possible. Besides explaining types of
Indexing in Databases theory, EduRev gives you an ample number of questions to practice Indexing in Databases tests, examples and also practice Computer Science Engineering (CSE)
tests

Related Searches
Exam
,Indexing in Databases | Database Management System (DBMS) - Computer Science Engineering (CSE)
,video lectures
,MCQs
,mock tests for examination
,practice quizzes
,study material
,Important questions
,Viva Questions
,Indexing in Databases | Database Management System (DBMS) - Computer Science Engineering (CSE)
,ppt
,Indexing in Databases | Database Management System (DBMS) - Computer Science Engineering (CSE)
,Extra Questions
,Objective type Questions
,Summary
,Previous Year Questions with Solutions
,Sample Paper
,past year papers
,Free
,Semester Notes
,shortcuts and tricks
;


Additional Information about Indexing in Databases for Computer Science Engineering (CSE) Preparation
Indexing in Databases Free PDF Download
The Indexing in Databases is an invaluable resource that delves deep into the core of the Computer Science Engineering (CSE) exam.
These study notes are curated by experts and cover all the essential topics and concepts, making your preparation more efficient and effective.
With the help of these notes, you can grasp complex subjects quickly, revise important points easily,
and reinforce your understanding of key concepts. The study notes are presented in a concise and easy-to-understand manner,
allowing you to optimize your learning process. Whether you're looking for best-recommended books, sample papers, study material,
or toppers' notes, this PDF has got you covered. Download the Indexing in Databases now and kickstart your journey towards success in the Computer Science Engineering (CSE) exam.
Importance of Indexing in Databases
The importance of Indexing in Databases cannot be overstated, especially for Computer Science Engineering (CSE) aspirants.
This document holds the key to success in the Computer Science Engineering (CSE) exam.
It offers a detailed understanding of the concept, providing invaluable insights into the topic.
By knowing the concepts well in advance, students can plan their preparation effectively.
Utilize this indispensable guide for a well-rounded preparation and achieve your desired results.
Indexing in Databases Notes
Indexing in Databases Notes offer in-depth insights into the specific topic to help you master it with ease.
This comprehensive document covers all aspects related to Indexing in Databases.
It includes detailed information about the exam syllabus, recommended books, and study materials for a well-rounded preparation.
Practice papers and question papers enable you to assess your progress effectively.
Additionally, the paper analysis provides valuable tips for tackling the exam strategically.
Access to Toppers' notes gives you an edge in understanding complex concepts.
Whether you're a beginner or aiming for advanced proficiency, Indexing in Databases Notes on EduRev are your ultimate resource for success.
Indexing in Databases Computer Science Engineering (CSE) Questions
The "Indexing in Databases Computer Science Engineering (CSE) Questions" guide is a valuable resource for all aspiring students preparing for the
Computer Science Engineering (CSE) exam. It focuses on providing a wide range of practice questions to help students gauge
their understanding of the exam topics. These questions cover the entire syllabus, ensuring comprehensive preparation.
The guide includes previous years' question papers for students to familiarize themselves with the exam's format and difficulty level.
Additionally, it offers subject-specific question banks, allowing students to focus on weak areas and improve their performance.
Study Indexing in Databases on the App
Students of Computer Science Engineering (CSE) can study Indexing in Databases alongwith tests & analysis from the EduRev app,
which will help them while preparing for their exam. Apart from the Indexing in Databases,
students can also utilize the EduRev App for other study materials such as previous year question papers, syllabus, important questions, etc.
The EduRev App will make your learning easier as you can access it from anywhere you want.
The content of Indexing in Databases is prepared as per the latest Computer Science Engineering (CSE) syllabus.
|
© EduRev
|
Education Revolution
|



|






Signup on EduRev and stay on top of your study goals
10M+ students crushing their study goals daily