Data Warehousing


Background
A Database Management System (DBMS) stores data in organised structures such as tables and commonly uses the Entity-Relationship (ER) model during conceptual design. A DBMS is designed to support transactional applications and to ensure ACID properties (Atomicity, Consistency, Isolation, Durability). For example, a college DBMS may contain tables for Students, Faculty, Courses and so on, and it supports day-to-day operations such as enrolment or grade updates.
A Data Warehouse is a separate repository built to store very large volumes of data collected from multiple, often heterogeneous, sources such as operational DBMSs, log files and external feeds. Its primary goal is to support analysis and decision making by providing integrated historical data and tools for analytics and reporting. For example, a college may use a data warehouse to analyse how placement outcomes for the Computer Science branch have changed over the last ten years in terms of counts and salary trends.
Need of a Data Warehouse
An ordinary operational database is typically sized and tuned for transactional workloads and can store data ranging from megabytes to gigabytes for a specific purpose. Organisations that need to retain and analyse data at terabyte scale or larger use a data warehouse. A transactional database does not readily support analytical workloads because the schemas, indexing and concurrency controls are tuned for frequent short transactions. To perform effective analytics, organisations create a central data warehouse that organises and integrates historical data, enabling strategic decision making and trend analysis across time and business units.
Data Warehouse vs DBMS
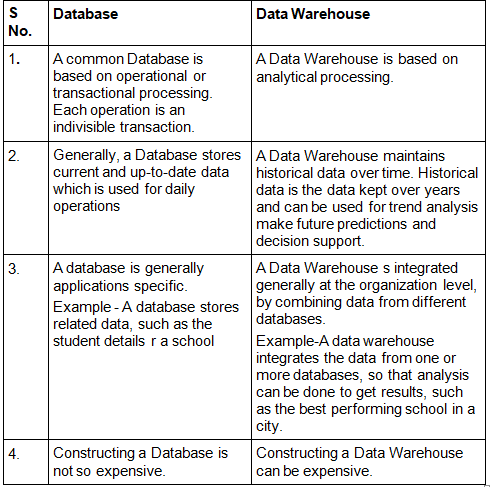
The following points highlight the typical differences between an operational DBMS (often called OLTP) and a data warehouse (often supporting OLAP):
- Primary purpose: DBMS - manage day-to-day transactions; Data warehouse - support analysis, reporting and decision support.
- Data sources: DBMS - single application or a small set of applications; Data warehouse - integrated from multiple heterogeneous sources (DBMSs, files, external feeds).
- Workload: DBMS - many short read/write transactions; Data warehouse - fewer, but complex, long-running read-intensive queries (aggregations, joins over large datasets).
- Schema design: DBMS - normalized schemas to avoid redundancy and support updates; Data warehouse - denormalised schemas (star/snowflake) to optimise query performance.
- Data volume and history: DBMS - recent/current data and smaller volumes; Data warehouse - large volumes with historical data retained for months or years.
- Updates: DBMS - frequent INSERT/UPDATE/DELETE; Data warehouse - bulk loads, periodic refreshes, mostly read operations.
- Users: DBMS - clerks, application users; Data warehouse - analysts, managers, BI tools and data scientists.
- Performance tuning: DBMS - tuned for short transactions and concurrency; Data warehouse - tuned for large scans, aggregations, indexing, partitioning and parallel processing.
Example Applications of Data Warehousing
Data warehousing is applicable wherever large amounts of historical data need to be analysed for strategic or operational insights:
- Social media websites: Platforms gather member, group and activity data and store it centrally to analyse engagement, recommend content and detect trends.
- Banking: Banks use warehouses to analyse spending patterns, detect fraud, and drive targeted offers and customer segmentation.
- Government: Public agencies analyse tax, census and service data to detect evasion, plan resources and inform policy.
- Other sectors: E-commerce, telecommunications, transportation, marketing and distribution, healthcare and retail all use data warehouses for reporting, analytics and forecasting.
Key Concepts and Components
Architectural Layers
A typical data warehouse architecture is layered. The main components are:
- Data sources: operational databases, flat files, logs, external feeds.
- Staging area: temporary storage where data is extracted and cleaned before transformation.
- ETL/ELT processes: Extract, Transform, Load (or Extract, Load, Transform) that integrate and prepare data for storage.
- Data storage: the core warehouse where cleaned, integrated, time-variant data is stored. This may be a central warehouse and/or multiple data marts.
- OLAP servers and cubes: structures allowing fast multi-dimensional analysis and pre-aggregated results.
- Metadata repository: information about data definitions, lineage, transformations and schema.
- Access tools: query tools, reporting, dashboards, visualisation and data mining tools used by analysts and managers.
ETL and Data Integration
The ETL process is central to data warehousing:
- Extract: collect data from heterogeneous sources while ensuring consistency and minimal impact on source systems.
- Transform: cleanse, validate, standardise, deduplicate and enrich data. Transformations include data type conversions, derived attributes, and conforming dimension values.
- Load: insert transformed data into the warehouse tables or data marts. Loading strategies include full refresh and incremental load.
Schemas: Star, Snowflake and Galaxy
Common logical designs for analytic schemas are:
- Star schema: a central fact table (measures) connected directly to multiple dimension tables (descriptive attributes). It is simple and optimised for query performance.
- Snowflake schema: a normalised form of the star where dimensions may be split into multiple related tables to remove redundancy.
- Galaxy (constellation) schema: multiple fact tables share dimension tables, useful for complex subject areas.
Fact tables store measures such as counts, amounts or quantitative values. Facts may be additive, semi-additive or non-additive. Dimension tables store contextual attributes such as time, product, customer, location and are used for filtering and grouping in queries.
OLTP versus OLAP
OLTP (Online Transaction Processing) systems are designed for high concurrency, low latency transactions and ensure strict consistency. OLAP (Online Analytical Processing) systems are designed for complex queries on historical data, aggregations across dimensions and interactive analysis. The data warehouse is typically the OLAP environment and pulls data from OLTP systems.
Data Loading, Refresh and Change Management
Important operational aspects include:
- Incremental loading: load only new or changed data rather than full reloads to reduce processing time.
- Change data capture (CDC): methods to identify and capture changes from source systems.
- Slowly changing dimensions (SCD): strategies to handle changes in dimension attributes over time (Type 1 overwrite, Type 2 versioning, Type 3 partial history, etc.).
- Refresh policies: near-real time, hourly, daily, weekly depending on use-case and SLA.
Performance Optimisation
Tuning a data warehouse focuses on fast analytical query response for large datasets:
- Indexing and bitmap indexes: support fast filtering on low-cardinality columns.
- Partitioning: divide large tables by range/hash/list (for example, by date) to prune scans and improve parallelism.
- Materialised views and aggregates: precomputed summaries to speed up common queries.
- Columnar storage and compression: reduce I/O for analytical scans and improve CPU efficiency.
- Parallel processing and MPP: distribute query execution across nodes for scale.
- Query rewrite and optimizer hints: let the engine use materialised aggregates automatically.
Quality, Governance and Security
For reliable analytics, warehouses need:
- Data quality: validation, deduplication and standardisation to ensure trustworthy results.
- Master data management (MDM): consistent definitions and authoritative reference data across domains.
- Metadata management: documentation of schemas, ETL logic, and data lineage for auditability.
- Security and access control: role-based access, masking of sensitive attributes and encryption at rest and in transit.
- Backup and disaster recovery: policies appropriate to the retention and availability needs of analytical data.
Design Example - College Placement Data Warehouse
This simple example demonstrates a star schema for college placement analytics.
Fact table: Placement_Fact (measures: Placed_Count, Total_Package, Average_Package)
Dimension tables:
- Student_Dim (Student_ID, Branch, Batch, Gender, Region)
- Company_Dim (Company_ID, Industry, Company_Size, Location)
- Time_Dim (Date, Month, Quarter, Year)
- Course_Dim (Course_ID, Course_Name)
Example analytical questions and corresponding SQL patterns:
- How has the average package for Computer Science changed year-on-year? - use GROUP BY on Time_Dim.Year filtered by Course_Dim.Course_Name = 'Computer Science'.
- Which companies hired the largest number of students in the last 5 years? - aggregate Placed_Count grouped by Company_Dim.Company_Name and order by sum descending.
- Distribution of packages by branch and year - GROUP BY branch and year with histogram/buckets on Average_Package.
Sample SQL (conceptual):
<code>SELECT T.Year, AVG(P.Average_Package) AS Avg_Package FROM Placement_Fact P JOIN Time_Dim T ON P.Time_Key = T.Time_Key JOIN Course_Dim C ON P.Course_Key = C.Course_Key WHERE C.Course_Name = 'Computer Science' GROUP BY T.Year ORDER BY T.Year; </code>
Practical Considerations and Tools
When implementing a data warehouse consider:
- Choice of storage: traditional RDBMS, columnar DB, cloud data warehouse (managed services) or a hybrid.
- ETL tooling: batch ETL frameworks, streaming ingestion and CDC tools depending on latency requirements.
- BI and visualisation tools: dashboards, reporting, ad-hoc query interfaces suited to business users.
- Scaling strategy: scale-up (bigger nodes) versus scale-out (distributed MPP) and use of cloud elasticity.
- Cost-performance trade-offs: compression, retention policies and level-of-detail aggregates to balance storage and query speed.
Summary
A data warehouse is a central, integrated repository designed for analysis and decision support. It complements operational DBMS systems by storing historical, time-variant data integrated from multiple sources and tuned for complex queries. Key aspects include ETL, schema design (star/snowflake), governance, and performance optimisation techniques such as partitioning, materialised views and columnar storage. Proper design and operational practices enable organisations to turn large volumes of data into reliable insights for strategic decisions.


 | Explore Courses for Computer Science Engineering (CSE) exam |
 | Get EduRev Notes directly in your Google search |