Concurrency Control in DBMS | Database Management System (DBMS) - Computer Science Engineering (CSE) PDF Download
Introduction
Concurrency Control deals with interleaved execution of more than one transaction. In the next article, we will see what is serializability and how to find whether a schedule is serializable or not.
What is Transaction?
A set of logically related operations is known as transaction. The main operations of a transaction are:
- Read(A): Read operations Read(A) or R(A) reads the value of A from the database and stores it in a buffer in main memory.
- Write (A): Write operation Write(A) or W(A) writes the value back to the database from buffer.
Note: It doesn’t always need to write it to database back it just writes the changes to buffer this is the reason where dirty read comes into picture
Let us take a debit transaction from an account which consists of following operations:
R(A);
A = A - 1000;
W(A);
Assume A’s value before starting of transaction is 5000.
- The first operation reads the value of A from database and stores it in a buffer.
- Second operation will decrease its value by 1000. So buffer will contain 4000.
- Third operation will write the value from buffer to database. So A’s final value will be 4000.
But it may also be possible that transaction may fail after executing some of its operations. The failure can be because of hardware, software or power etc. For example, if debit transaction discussed above fails after executing operation 2, the value of A will remain 5000 in the database which is not acceptable by the bank. To avoid this, Database has two important operations:
- Commit: After all instructions of a transaction are successfully executed, the changes made by transaction are made permanent in the database.
- Rollback: If a transaction is not able to execute all operations successfully, all the changes made by transaction are undone.
Properties of a transaction
1. Atomicity: As a transaction is set of logically related operations, either all of them should be executed or none. A debit transaction discussed above should either execute all three operations or none. If debit transaction fails after executing operation 1 and 2 then its new value 4000 will not be updated in the database which leads to inconsistency.
2. Consistency: If operations of debit and credit transactions on same account are executed concurrently, it may leave database in an inconsistent state.
- For Example, T1 (debit of Rs. 1000 from A) and T2 (credit of 500 to A) executing concurrently, the database reaches inconsistent state.
- Let us assume Account balance of A is Rs. 5000. T1 reads A(5000) and stores the value in its local buffer space. Then T2 reads A(5000) and also stores the value in its local buffer space.
- T1 performs A = A - 1000 (5000 - 1000 = 4000) and 4000 is stored in T1 buffer space. Then T2 performs A = A + 500 (5000 + 500 = 5500) and 5500 is stored in T2 buffer space. T1 writes the value from its buffer back to database.
- A’s value is updated to 4000 in database and then T2 writes the value from its buffer back to database. A’s value is updated to 5500 which shows that the effect of debit transaction is lost and database has become inconsistent.
- To maintain consistency of database, we need concurrency control protocols which will be discussed in next article. The operations of T1 and T2 with their buffers and database have been shown in Table 1.
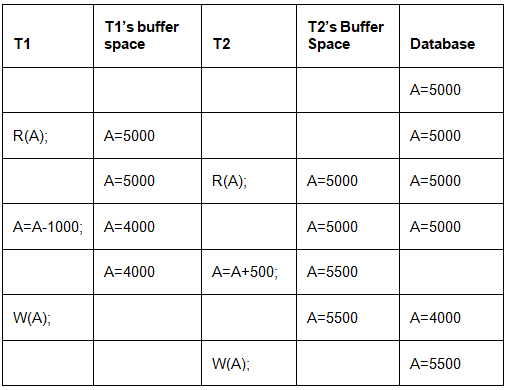 Table 1 3. Isolation: Result of a transaction should not be visible to others before transaction is committed. For example, Let us assume that A’s balance is Rs. 5000 and T1 debits Rs. 1000 from A. A’s new balance will be 4000. If T2 credits Rs. 500 to A’s new balance, A will become 4500 and after this T1 fails. Then we have to rollback T2 as well because it is using value produced by T1. So a transaction results are not made visible to other transactions before it commits.
Table 1 3. Isolation: Result of a transaction should not be visible to others before transaction is committed. For example, Let us assume that A’s balance is Rs. 5000 and T1 debits Rs. 1000 from A. A’s new balance will be 4000. If T2 credits Rs. 500 to A’s new balance, A will become 4500 and after this T1 fails. Then we have to rollback T2 as well because it is using value produced by T1. So a transaction results are not made visible to other transactions before it commits.
4. Durable: Once database has committed a transaction, the changes made by the transaction should be permanent. e.g.; If a person has credited $500000 to his account, bank can’t say that the update has been lost. To avoid this problem, multiple copies of database are stored at different locations.
What is a Schedule?
A schedule is a series of operations from one or more transactions. A schedule can be of two types:
- Serial Schedule: When one transaction completely executes before starting another transaction, the schedule is called serial schedule. A serial schedule is always consistent. example: If a schedule S has debit transaction T1 and credit transaction T2, possible serial schedules are T1 followed by T2 (T1 → T2) or T2 followed by T1 ((T2 → T1). A serial schedule has low throughput and less resource utilization.
- Concurrent Schedule: When operations of a transaction are interleaved with operations of other transactions of a schedule, the schedule is called Concurrent schedule. example: Schedule of debit and credit transaction shown in Table 1 is concurrent in nature. But concurrency can lead to inconsistency in the database. The above example of a concurrent schedule is also inconsistent.
Q. Consider the following transaction involving two bank accounts x and y: [GATE 2015]
1. read(x);
2. x := x – 50;
3. write(x);
4. read(y);
5. y := y + 50;
6. write(y);
The constraint that the sum of the accounts x and y should remain constant is that of?
(a) Atomicity
(b) Consistency
(c) Isolation
(d) Durability
Ans: (b)
Solution: As discussed in properties of transactions, consistency properties says that sum of accounts x and y should remain constant before starting and after completion of transaction. So, the correct answer is B.
|
62 videos|66 docs|35 tests
|
FAQs on Concurrency Control in DBMS - Database Management System (DBMS) - Computer Science Engineering (CSE)
| 1. What is concurrency control in DBMS? |  |
| 2. Why is concurrency control important in DBMS? | |
| 3. What are the different types of concurrency control techniques in DBMS? | |
| 4. How does two-phase locking (2PL) work as a concurrency control technique in DBMS? | |
| 5. What is optimistic concurrency control in DBMS? | |

|
4.61/5 Rating |

|
Dec 28, 2024 Last updated |

|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
ppt
,Sample Paper
,MCQs
,past year papers
,Previous Year Questions with Solutions
,Free
,Exam
,Concurrency Control in DBMS | Database Management System (DBMS) - Computer Science Engineering (CSE)
,mock tests for examination
,Extra Questions
,video lectures
,Concurrency Control in DBMS | Database Management System (DBMS) - Computer Science Engineering (CSE)
,Summary
,Semester Notes
,Viva Questions
,shortcuts and tricks
,study material
,practice quizzes
,Objective type Questions
,Important questions
,Concurrency Control in DBMS | Database Management System (DBMS) - Computer Science Engineering (CSE)
;






Concurrency Control in DBMS Free PDF Download
Importance of Concurrency Control in DBMS
Concurrency Control in DBMS Notes
Concurrency Control in DBMS Computer Science Engineering (CSE) Questions
Study Concurrency Control in DBMS on the App
|
© EduRev
|
Education Revolution
|



|




