B - Tree


Introduction
B-Tree is a height-balanced search tree optimised for systems that read and write large blocks of data (for example, secondary storage such as disks). Unlike balanced binary search trees (AVL, Red-Black), which assume data resides in main memory, a B-Tree organises keys so that each node corresponds to a disk block and stores many keys. The principal goal is to reduce the number of disk accesses: most fundamental operations (search, insert, delete, find-min, find-max) require O(h) node accesses where h is the tree height. By allowing each node to hold many keys, a B-Tree is a "fat" tree with small height, so the number of expensive disk reads is minimised.
Time Complexity of B-Tree
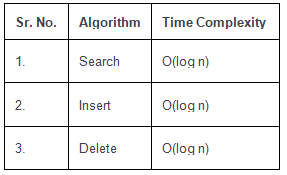
If n is the total number of keys stored in a B-Tree of minimum degree t, the height h grows logarithmically with n, typically expressed as h = O(log_t n). Therefore, the cost of search, insertion and deletion in terms of node (disk block) accesses is O(h), which is O(log n) when t is treated as a constant determined by disk block size.
Properties of B-Tree
- All leaves are at the same level (the tree is height-balanced).
- A B-Tree is defined by its minimum degree t (t ≥ 2). The value of t depends on the node size chosen to match a disk block or page size.
- Every node except the root must contain at least t - 1 keys. The root must contain at least one key unless the tree is empty.
- Every node may contain at most 2t - 1 keys.
- The number of children of an internal node is equal to the number of its keys plus one. Thus an internal node with k keys has k + 1 children.
- All keys within a node are stored in sorted order. The children are arranged so that the subtree between two keys contains all keys between those two separator keys.
- A B-Tree grows and shrinks from the root: splits may propagate upward (causing the tree to grow in height) and merges may cause the root to be replaced (reducing height).
- When t is fixed, the time complexity of search, insert and delete in terms of node accesses is O(log n); more precisely the number of node accesses is O(h), with h = Θ(log_t n).
Example
The following diagram is a B-Tree of minimum order 5 (that is, t = 5). In practice nodes typically contain many more keys because node size is chosen to fit a disk block or page.
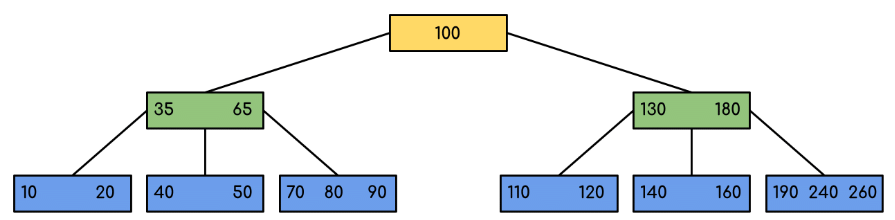
Note that all leaf nodes are at the same level and each non-leaf node with k keys has k + 1 children.
Interesting Facts
- The minimum possible height of a B-Tree with n keys (when internal nodes are as full as possible) can be expressed by a formula; see the placeholder below for a precise expression in terms of n and the maximum number of children per node.
- The maximum possible height of a B-Tree with n keys (when non-root nodes have the minimum number of children) can be expressed by a formula; see the placeholders below for the expressions in terms of n and the minimum number of children per non-root node.
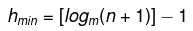
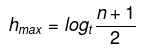
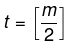
Traversal in B-Tree
Traversal in a B-Tree follows the same ordering principle as an inorder traversal of a binary search tree, extended to nodes that can hold many keys. For a node with keys k1 < k2 < ... < km and children c0, c1, ..., cm, the traversal order is:
- Recursively traverse c0, then output k1, recursively traverse c1, then output k2, and so on, finally recursively traverse cm.
Search Operation in B-Tree
Searching for a key k begins at the root. For each visited node, perform a binary search (or linear scan) among the node's keys to find the smallest index i such that k ≤ key[i]. If key[i] = k, return the node (and index). Otherwise recurse into child c[i] (the child that lies immediately before the first key greater than k). If a leaf is reached and k is not found there, the key is not present.
Because each node contains many keys, searching within a node uses an in-node search (binary search is common) and the overall number of node visits is bounded by the tree height h.
Search Example
The diagram below illustrates searching for a specific key (for example, 120). The images show the node-by-node decisions that limit which subtree must contain the key.
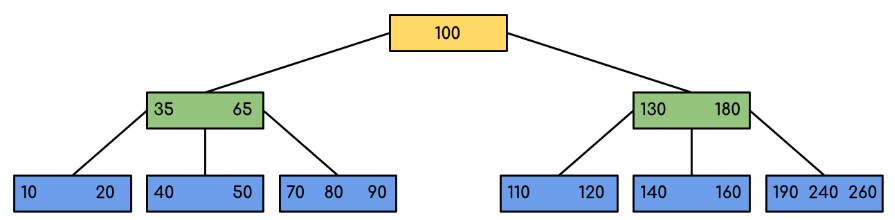
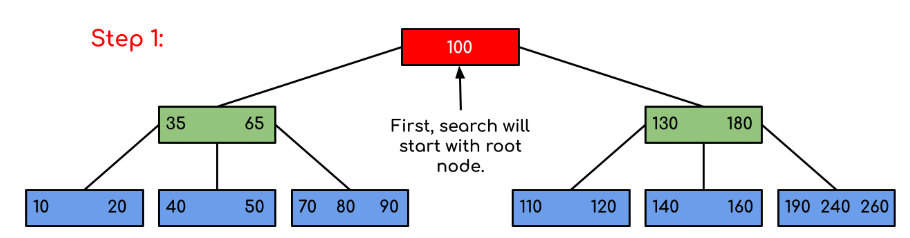
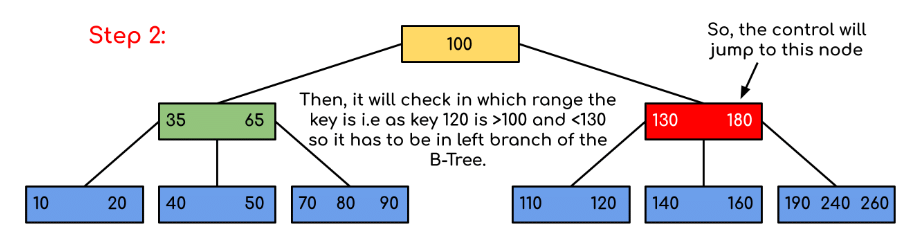
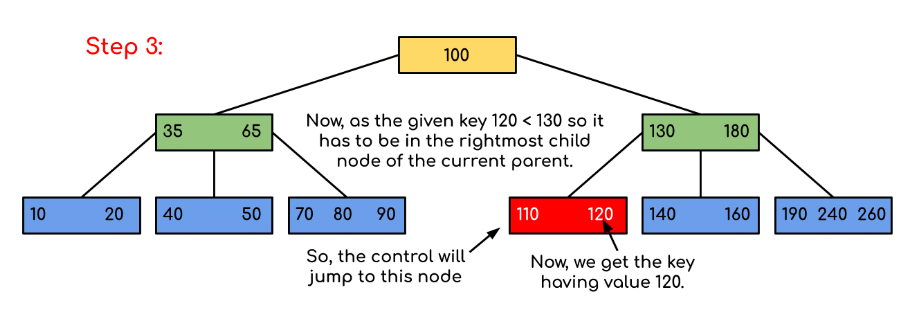
In the example, the search quickly narrows the candidate subtree at each visited node by comparing against separator keys. If the key equals a separator key it is found immediately; otherwise the appropriate child pointer is followed.
Insert Operation in B-Tree
A new key is always inserted into a leaf. The insertion algorithm used in textbooks (for example, CLRS) is proactive: it splits any full node that would be traversed before descending into it. Splitting a full child ensures that when the algorithm reaches the leaf where the new key belongs, that leaf has space for the new key and no backtracking is necessary. The split operation moves the median key of a full child up into its parent and splits the remaining keys and children into two nodes.
Split example
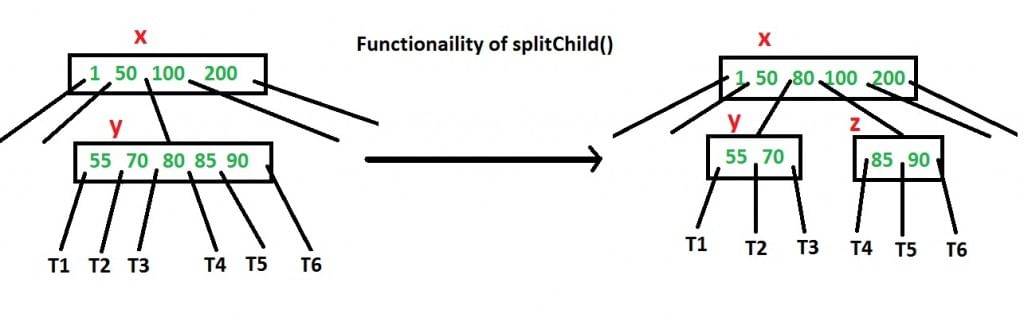
The operation commonly used is splitChild(x, i), which splits the i-th child y of node x (which must be full) into two nodes and moves the median key from y into x.
Insertion algorithm (proactive)
- Set the current node x to the root.
- While x is not a leaf:
Find the child y of x that must be followed for the new key k. If y is full, split it using splitChild(x, indexOf(y)). After the split decide whether to descend to the left or right half of the split child according to the comparison with the moved-up key. Set x to the chosen child and continue.
- When x is a leaf, insert k into the keys of x in sorted order. Because full children are split pre-emptively, the leaf x has room for the new key.
This proactive approach ensures the algorithm performs at most one top-to-leaf traversal and never needs to backtrack to split nodes.
Insertion Example (t = 3)
Consider inserting the sequence 10, 20, 30, 40, 50, 60, 70, 80, 90 into an initially empty B-Tree with minimum degree t = 3. The maximum keys per node are 2t - 1 = 5.
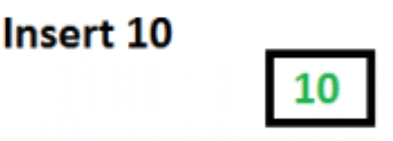
After inserting 10 the root contains a single key.

After inserting 20, 30, 40 and 50 the root fills up but remains a single node because it can contain up to 5 keys.
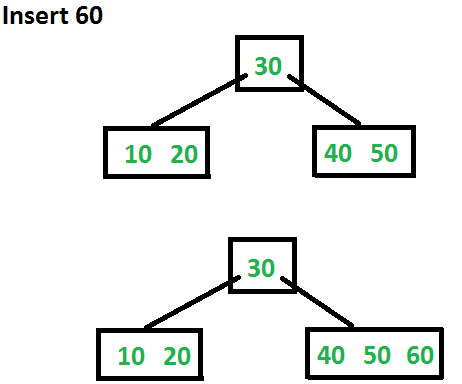
Inserting 60 requires splitting the full root. The root is split, the middle key moves up to form a new root, and 60 is placed in the appropriate child.
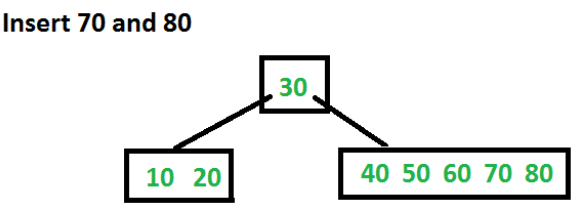
Insertions of 70 and 80 proceed by placing them in the appropriate leaf nodes without further splits.
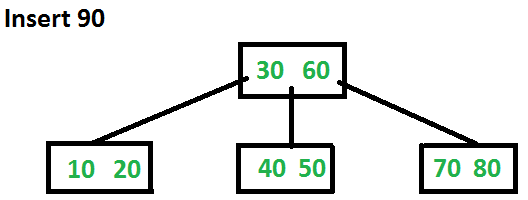
Inserting 90 forces another split at a leaf, and the median key moves up into the parent, demonstrating how splits propagate upward only when necessary.
Delete Operation in B-Tree
Deletion is more involved than insertion because keys can be removed from internal nodes as well as leaves, and after deletion nodes must still satisfy the B-Tree invariants. The deletion procedure is usually defined so that every recursive call descends to a node that has at least t keys (one more than the minimum of t - 1), thereby avoiding the need to backtrack except in one special case. If the root ever becomes keyless as an internal node, it is deleted and its single child becomes the new root (reducing height).
Deletion cases
- If the key k is present in node x and x is a leaf, simply remove k from x.
- If k is present in an internal node x:
Case 2a: If the child y that precedes k (left child) has at least t keys, find the predecessor k' of k (the largest key in the subtree rooted at y), replace k by k' in x, and recursively delete k' from the subtree rooted at y. The predecessor can be found and deleted in a single downward pass.
Case 2b: Otherwise, if the child z that follows k (right child) has at least t keys, find the successor k' of k (the smallest key in the subtree rooted at z), replace k by k' in x, and recursively delete k' from z.
Case 2c: Otherwise, if both y and z have only t - 1 keys, merge k and all keys and children of z into y. After the merge y contains 2t - 1 keys, the pointer to z is removed from x and z is freed. Then recurse to delete k from the merged node y.
- If k is not present in internal node x, determine the child c that must contain k (if it exists). If c has only t - 1 keys, the algorithm ensures before descending that c will have at least t keys by applying one of the following operations:
Case 3a: If an immediate sibling of c has at least t keys, transfer a key from the sibling through the parent into c. Concretely, move a key from x down into c, move the appropriate sibling key up into x, and shift the child pointers so c gains one child. After the transfer c has at least t keys and recursion proceeds into c.
Case 3b: If both immediate siblings of c have only t - 1 keys, merge c with one sibling by moving a key from x into the merged node. After the merge the merged node has at least t keys, and recursion proceeds into it.
Most deletions remove keys from leaves; by ensuring that the child we descend into has at least t keys, the deletion algorithm performs a single downward pass except for replacing a deleted internal key with a predecessor or successor (cases 2a and 2b), which involves a downward search for the predecessor or successor.
Deletion illustrations
The following figures illustrate the typical cases for deletion: movement of keys between siblings and parent, merging two children with a parent key, and the reduction of height when the root loses its only key.
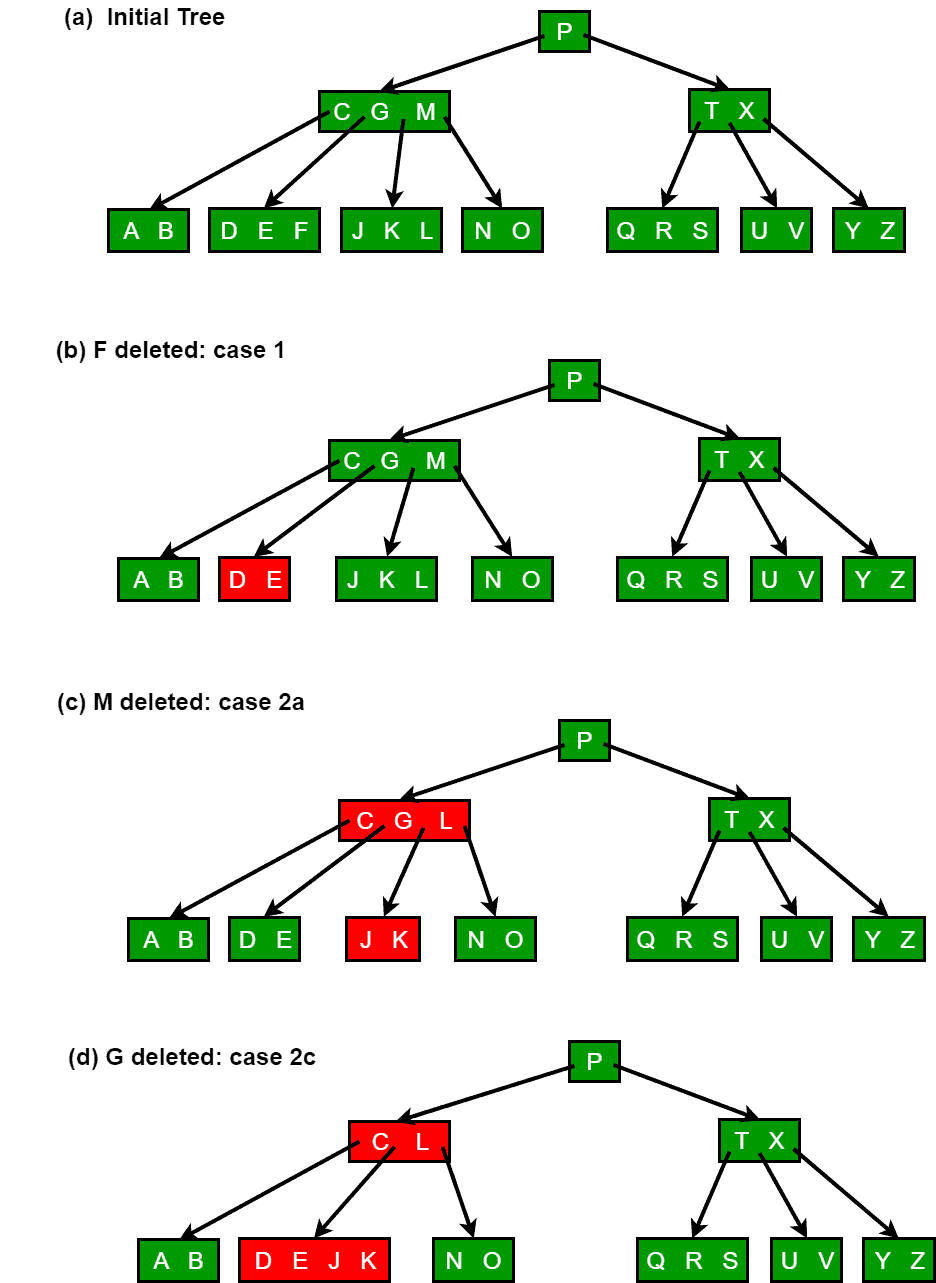
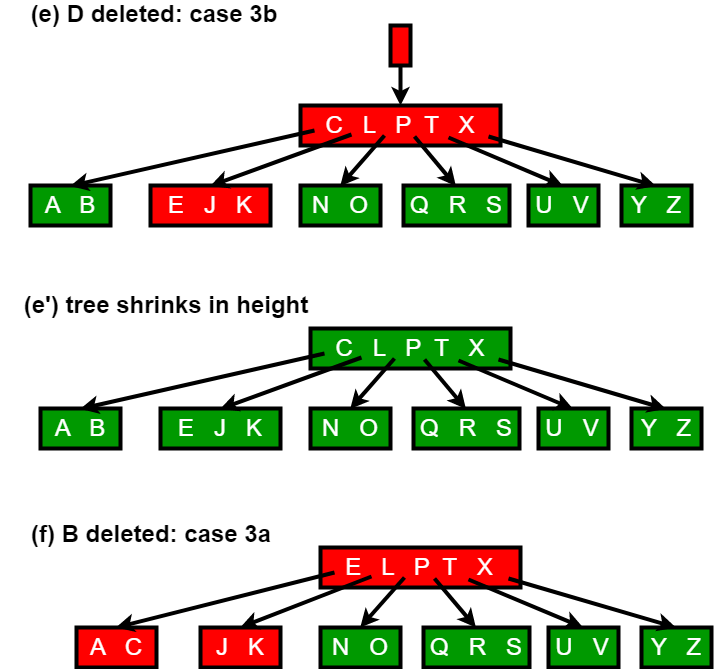
Implementation notes and applications
- In practice, node size is chosen to match a disk block or filesystem page; this makes each node access a single disk I/O and maximises the number of keys per I/O.
- B-Trees are widely used in database indexes and file systems because they provide efficient range queries, ordered iteration (via inorder traversal), and stable performance for large data sets on secondary storage.
- Within each node, keys are usually searched with binary search; for very large node capacity, techniques such as keyed binary search, interpolation search, or in-node small indexes may be used.
- Variants: B+-Tree (all actual records stored in leaves; internal nodes store only keys and child pointers) is a very common practical variant used in databases and file systems because it makes range scans efficient and allows leaf chaining.
Summary
A B-Tree organises large sets of keys to minimise disk accesses by storing many keys in each node. It is parameterised by a minimum degree t, which controls the minimum and maximum keys per node. Search, insert and delete take time proportional to the height h, which is logarithmic in the number of keys. Correct handling of node splitting (on insertion) and borrowing/merging (on deletion) maintains the B-Tree invariants and ensures efficient performance on secondary storage.
FAQs on B - Tree
| 1. What is a B-Tree? |  |
| 2. How does the insert operation work in a B-Tree? | |
| 3. What is the complexity of the insert operation in a B-Tree? | |
| 4. How does the delete operation work in a B-Tree? | |
| 5. What is the complexity of the delete operation in a B-Tree? | |


 | Explore Courses for Computer Science Engineering (CSE) exam |
 | Get EduRev Notes directly in your Google search |