Notes: Semaphores

Semaphores in Process Synchronization
Semaphore was proposed by Dijkstra (1965). It is a fundamental technique to manage concurrent processes or threads using a single integer value called a semaphore. A semaphore is a shared variable (or abstract data type) that is typically used to solve the critical-section problem and to achieve process synchronization in a multiprogramming environment.
Types of semaphores
- Binary semaphore
Also called a mutex lock in informal usage. It can take only two values: 0 and 1. Its value is commonly initialised to 1. Binary semaphores are used to implement mutual exclusion where only one process or thread may enter the critical section at a time. - Counting semaphore
Its value can range over an unrestricted integer domain (positive, zero or negative in some implementations). A counting semaphore is used to control access to a resource that has multiple identical instances (for example, N identical buffers or N identical hardware devices).
Operations on a semaphore
Semaphores are manipulated by two atomic operations commonly named P and V (terms introduced by Dijkstra). Alternative names are wait (or down) for P, and signal (or up) for V.
Standard semantics (textbook, Dijkstra-style):
- P (wait / down): atomically decrement the semaphore value. If the resulting value is negative, the invoking process is blocked and placed in the semaphore's waiting queue.
- V (signal / up): atomically increment the semaphore value. If the resulting value is non-positive (i.e., there are blocked processes), wake up one waiting process.
Atomicity of P and V means that the read-modify-write sequence on the semaphore variable is indivisible: no other process can interleave its own operations on that semaphore while the operation is in progress.

Notes about P and V operations
- Synonyms: P operation is also called wait, sleep, or down. V operation is also called signal, wake-up, or up.
- Atomicity and initialisation: Both operations must be atomic. A binary semaphore is typically initialised to 1; a counting semaphore is initialised to the number of available resources.
- Use with critical sections: A critical section is surrounded by P before entry and V after exit to enforce mutual exclusion or to coordinate access to shared resources. The critical section of a process lies between the P and V operations for that process.
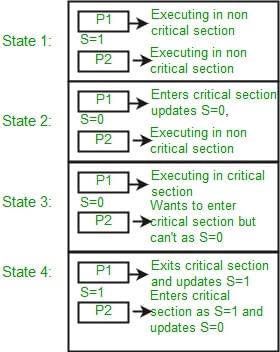
Mutual exclusion using a binary semaphore
Consider two processes P1 and P2 and a binary semaphore s initialised to 1. A process executes P(s) before entering its critical section and V(s) after leaving it. If P1 executes P(s) and reduces s to 0, P2 executing P(s) will block until P1 executes V(s) and restores s to 1. In this way mutual exclusion is achieved using a binary semaphore.
Mutex versus Semaphore
Both mutexes and semaphores are synchronization primitives provided by operating systems (or libraries) to coordinate multiple threads or processes. They serve related but distinct purposes. Understanding the differences is important when designing concurrent programs.
Conceptual distinction
- Mutex (mutual exclusion object): A mutex is a locking mechanism used to enforce exclusive access to a resource. Ownership is associated with a mutex: the thread that acquires (locks) the mutex is the only one allowed to release (unlock) it. Mutexes prevent multiple threads from entering a critical section simultaneously. They are primarily for mutual exclusion.
- Semaphore: A semaphore is primarily a signalling mechanism. It can be used to both achieve mutual exclusion (binary semaphore) and to count resources (counting semaphore). A semaphore does not necessarily enforce ownership semantics: any thread that performs V can potentially wake another thread that performs P.
Illustration: producer-consumer (single buffer vs multiple buffers)
Consider a producer and a consumer sharing a buffer of 4096 bytes.
- Using a mutex: A single mutex ensures that at most one thread (producer or consumer) accesses the whole buffer at any time. When the producer fills the buffer the consumer must wait until the producer releases the mutex; when the consumer is reading the buffer the producer waits.
- Using a counting semaphore: If the 4 KB buffer is divided into four 1 KB sub-buffers (multiple identical resources), a counting semaphore initialised to 4 can be used to track available sub-buffers. The producer and consumer can operate on different sub-buffers concurrently, increasing parallelism compared with a single mutex.
Common misconceptions
Although a binary semaphore and a mutex can be implemented in similar ways, they are conceptually different. A mutex implies ownership and is a locking mechanism. A semaphore is a signalling/counting mechanism. For example, a thread holding a mutex must be the one to release it; a semaphore's V operation may be invoked by a different context to signal availability. Because of ownership semantics, a mutex is often preferred for pure mutual exclusion; using a binary semaphore to mimic a mutex can lead to subtle issues such as priority inversion unless handled carefully.
General Questions
Q.1. Can a thread acquire more than one lock (Mutex)?
Ans: Yes, it is possible that a thread is in need of more than one resource, hence the locks. If any lock is not available the thread will wait (block) on the lock.
Q.2. Can a mutex be locked more than once?
Ans: A mutex is a lock. Only one state (locked/unlocked) is associated with it. However, a recursive mutex can be locked more than once (POSIX compliant systems), in which a count is associated with it, yet retains only one state (locked/unlocked). The programmer must unlock the mutex as many number times as it was locked.
Q.3. What happens if a non-recursive mutex is locked more than once.
Ans: Deadlock. If a thread that had already locked a mutex, tries to lock the mutex again, it will enter into the waiting list of that mutex, which results in a deadlock. It is because no other thread can unlock the mutex. An operating system implementer can exercise care in identifying the owner of the mutex and return if it is already locked by a same thread to prevent deadlocks.
Q.4. Are binary semaphore and mutex same?
Ans: No. We suggest treating them separately, as it is explained in signaling vs locking mechanisms. But a binary semaphore may experience the same critical issues (Example: priority inversion) associated with a mutex. We will cover these in a later article. A programmer can prefer mutex rather than creating a semaphore with count 1.
Q.5. What is a mutex and critical section?
Ans: Some operating systems use the same word critical section in the API. Usually a mutex is a costly operation due to protection protocols associated with it. At last, the objective of mutex is atomic access. There are other ways to achieve atomic access like disabling interrupts which can be much faster but ruins responsiveness. The alternate API makes use of disabling interrupts.
Q.6. What are events?
Ans: The semantics of mutex, semaphore, event, critical section, etc... are same. All are synchronization primitives. Based on their cost in using them they are different. We should consult the OS documentation for exact details.
Q.7. Can we acquire mutex/semaphore in an Interrupt Service Routine?
Ans: An ISR will run asynchronously in the context of current running thread. It is not recommended to query (blocking call) the availability of synchronization primitives in an ISR. The ISR are meant be short, the call to mutex/semaphore may block the current running thread. However, an ISR can signal a semaphore or unlock a mutex.
Q.8. What we mean by "thread blocking on mutex/semaphore" when they are not available?
Ans: Every synchronization primitive has a waiting list associated with it. When the resource is not available, the requesting thread will be moved from the running list of processors to the waiting list of the synchronization primitive. When the resource is available, the higher priority thread on the waiting list gets the resource (more precisely, it depends on the scheduling policies).
Q.9. Is it necessary that a thread must block always when resource is not available?
Ans: Not necessary. If the design is sure 'what has to be done when resource is not available', the thread can take up that work (a different code branch). To support application requirements the OS provides non-blocking API. For example POSIX pthread_mutex_trylock() API. When the mutex is not available the function returns immediately whereas the API pthread_mutex_lock() blocks the thread till the resource is available.
Lock Variable Synchronization Mechanism
A lock variable is a simple software-based synchronization mechanism that can be implemented in user mode without kernel support. It typically uses busy waiting (spin-waiting). It can be used with more than two processes, but it has important limitations.
- It is implemented in user mode and does not require operating-system support (software-only solution).
- It uses busy waiting: a process repeatedly tests the lock variable while waiting, keeping the CPU busy.
- It can be used for more than two processes, but correctness and progress are not guaranteed in all timing scenarios.
Conventionally, Lock = 0 implies the critical section is vacant (initial value), and Lock = 1 implies the critical section is occupied. A simple pseudo-code structure is:
// Producer-consumer style buffer (illustrative) char buffer[SIZE]; int count = 0, start = 0, end = 0; struct lock l; // initialize lock variable lock_init(&l); void put(char c) { // entry section lock_acquire(&l); // critical section begins while (count == SIZE) { lock_release(&l); lock_acquire(&l); } count++; buffer[start] = c; start++; if (start == SIZE) { start = 0; } // critical section ends // exit section lock_release(&l); } char get() { char c; // entry section lock_acquire(&l); // critical section begins while (count == 0) { lock_release(&l); lock_acquire(&l); } count--; c = buffer[end]; end++; if (end == SIZE) { end = 0; } // critical section ends // exit section lock_release(&l); return c; }

Formal observation and failure mode
The lock-variable approach appears simple but can fail to guarantee mutual exclusion under realistic CPU instruction interleavings. To see why, consider an assembly-level sequence of operations that implement the "test-and-set" style check using separate instructions:
- Load Lock, R0 ; (store the value of Lock into register R0)
- CMP R0, #0 ; (compare the value in R0 with 0)
- JNZ Step 1 ; (jump to step 1 if R0 is not 0)
- Store #1, Lock ; (set Lock to 1 - enter critical section)
- Store #0, Lock ; (set Lock to 0 - exit critical section)
Consider two processes P1 and P2 competing for the critical section with initial Lock = 0. A problematic interleaving is:
- P1 executes step 1 and gets pre-empted before completing the remaining steps.
- P2 executes steps 1, 2, 3 and 4, enters the critical section and then is pre-empted.
- P1 resumes, executes steps 2, 3 and 4 based on the old value read into R0, and also enters the critical section.
In this sequence P1 used a stale value of the lock read earlier and so both P1 and P2 can be in the critical section simultaneously. This violates mutual exclusion. The essence of the problem is that the read-modify-write is not atomic: separate instructions allow interleavings that break correctness.
Why lock-variable methods are insufficient
- Non-atomic test-and-set implemented as multiple instructions allows race conditions under pre-emption or concurrent execution on multiple processors.
- Busy waiting wastes CPU cycles and is undesirable on single-processor systems where blocked tasks should be suspended rather than spinning.
- Lock-variable solutions do not by themselves guarantee progress or bounded waiting under all scheduling behaviours.
Evaluation criteria for synchronization algorithms
Any synchronization mechanism is judged by three primary properties:
- Mutual exclusion: At most one process is in the critical section at any time.
- Progress: If no process is in the critical section and some processes wish to enter it, the selection of the next process cannot be postponed indefinitely.
- Bounded waiting: There exists a bound on the number of times other processes are allowed to enter their critical sections after a process has made a request to enter and before that request is granted.
Mutual exclusion is often considered the most important property; however, progress and bounded waiting are essential for fairness and liveness.
Summary and practical notes
- Use mutexes when you require ownership semantics and simple mutual exclusion-only the thread that locked should unlock.
- Use counting semaphores to manage access to multiple identical resources or to implement producer-consumer buffers with multiple slots.
- Prefer atomic hardware primitives (for example, test-and-set, compare-and-swap, or fetch-and-add) or OS-provided primitives for implementing locks and semaphores; these avoid the race conditions of simple lock-variable implementations.
- Avoid blocking in ISRs: Interrupt Service Routines should be short and must not perform blocking waits. ISRs may signal semaphores or release mutexes but should not call blocking acquisition functions.
- Consider priority inversion and other concurrency hazards: Use appropriate priority inheritance protocols or the OS's synchronization features to handle real-time constraints.
FAQs on Notes: Semaphores
| 1. What are semaphores in process synchronization? |  |
| 2. How do semaphores work in process synchronization? | |
| 3. What are the types of semaphores in process synchronization? | |
| 4. What is the purpose of using semaphores in process synchronization? | |
| 5. Can semaphores be used for interprocess communication? | |


 | Explore Courses for Computer Science Engineering (CSE) exam |
 | Get EduRev Notes directly in your Google search |