The Fork & Join Constructs

Fork and Join Constructs in Concurrency
Fork
The fork instruction creates a new concurrent execution (a child) from the point where it is executed. The original execution that invoked the fork is called the parent. The fork instruction typically takes a single parameter, a label (L), which is the entry point for the child execution. After a fork:
- The child begins execution at the statement labelled L.
- The parent continues execution with the statement immediately following the fork instruction.
- Both parent and child execute concurrently (interleaved or in parallel, depending on the implementation).
In formal or simplified fork/join languages, the fork is often represented as a system call or language primitive such as fork L or spawn L. The fork operation must be implemented so that the two executions have separate control flows, and any shared variables are handled according to the memory model (shared memory, message passing, etc.).
Join
The join instruction is used to recombine multiple concurrent computations into a single continuation. A common pattern uses an integer variable, called a count, that is initialised to the number of concurrently running computations that must synchronise (the fan-in count). The usual semantics are:
- Each concurrent computation that reaches the join executes join count. The join operation performs an atomic decrement of the count variable.
- If the value of count after the decrement is greater than zero, the process that executed the join terminates (or returns to the runtime), having only signalled its completion.
- If the value of count after the decrement becomes zero, that process is the last arriving computation and it continues execution with the next statement after the join point; thus the concurrent flows have been recombined into a single continuation.
This behaviour implements a simple synchronisation/fan-in: exactly one of the arriving computations continues past the join. The join operation must be atomic on the count variable to avoid race conditions. An alternative synchronisation pattern is for the parent to wait explicitly for all children (for example using wait or a barrier), but the single-continuation join described above is common in structured fork/join formalisms.
Precedence Graphs and Fork/Join
A precedence graph (also called a dependency or partial order graph) represents ordering constraints among statements or tasks. Nodes denote statements or tasks (S1, S2, ...). A directed edge from node A to node B means A must complete before B begins.
When mapping a fork/join program to a precedence graph:
- Sequential statements produce a linear chain of edges (S1 → S2 → S3).
- A fork creates branching: one edge from the fork to the child's starting label, and another edge to the continuation in the parent.
- A join causes several branches to converge: the join point is reachable only after all required branches complete (modelled by incoming edges from the last statements of each branch to the join continuation).
Conversely, when constructing a fork/join program from a precedence graph, the goal is to introduce forks to create parallel branches for independent subgraphs and joins (or appropriate counters) to recombine them where the graph enforces a common successor.
Good practices and implementation notes
- Initialise the count variable to the number of concurrent computations that must be joined before the continuation can run.
- Ensure join decrement is atomic to prevent lost updates and incorrect continuation ordering.
- Decide which execution continues after the join (commonly the last arriving task). Document this because different models use different conventions (parent resumes, last child continues, explicit waiter, etc.).
- Watch for shared data races; synchronise accesses to shared variables using locks, atomic operations, or by structuring data as private to each task and combining results only at the join point.
- Use clear labels for fork targets (L1, L2, ...) and explicit control transfers (GOTO) only in small illustrative examples; structured constructs (spawn/join blocks) are preferred in real code.
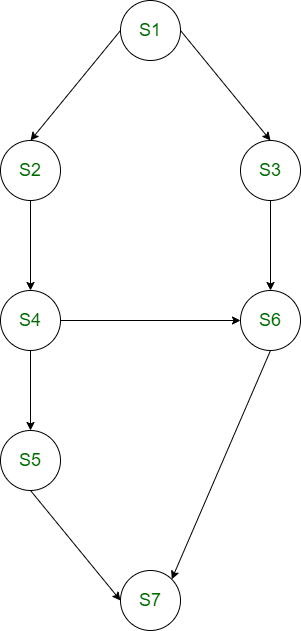
Example 1:
Construct the precedence graph for the following fork/join program.
S1; count1 := 2; fork L1; S2; S4; count2 := 2; fork L2; S5; Go to L3; L1: S3; L2: join count1; S6; L3: join count2; S7;
Solution:
Interpretation and construction steps:
- Initial sequence: S1 executes first.
- First fork setup: count1 is set to 2 so two computations are expected to synchronise on that counter. The fork L1 produces two concurrent flows: the child begins at label L1 (which executes S3) and the parent continues with S2 then S4.
- Second fork setup: later, count2 is set to 2 and fork L2 produces another pair of concurrent flows: one starts at L2 (which executes join count1, then S6) and the other is the parent flow that executes S5 and jumps to L3.
- Joining using count1: the join at L2 decrements count1. When the last of the two computations that belong to count1 arrives, it continues with S6. Until both have executed their join count1, the last one is the continuation.
- Joining using count2: both branches that were created by the second fork converge at L3 with join count2. The last arriving computation continues with S7.
The precedence graph is the visual representation showing these branches and joins. The following placeholder represents the expected diagram for this program:
Example 2:
Write a fork/join program for the following precedence graph.
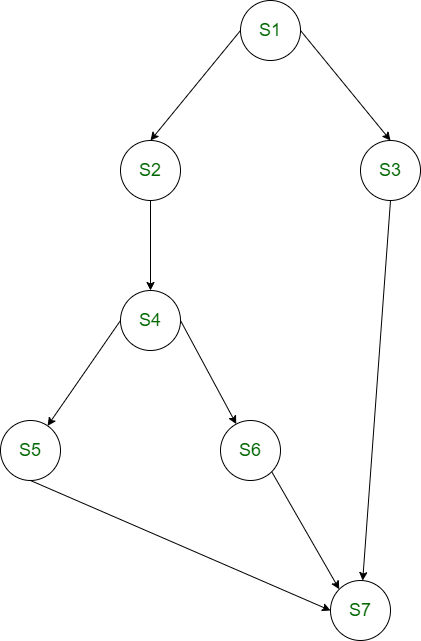
Solution:
Observations from the precedence graph:
- After S1 the work splits into three concurrent computations that must all complete before the final statement S7.
- Two forks placed at appropriate points can create the required parallel branches. A single count variable initialised to 3 ensures that exactly one continuation occurs after all three branches signal completion.
S1; count := 3; fork L1; S2; S4; fork L2; S5; Go to L3; L2: S6; GOTO L3; L1: S3; L3: join count; S7;
Explanation of this program:
- The program begins with S1.
- count := 3 records that three computations (branches) will be combined later.
- fork L1 creates a child that executes at label L1 (S3). The parent continues with S2 and S4.
- After S4 the program executes fork L2 which creates a second child that executes at label L2 (S6). The parent continues with S5 and then jumps to L3.
- Both children, after finishing their statements (S3 and S6), will reach the join count pattern: they decrement count. The parent branch also reaches the join at L3 and executes join count. When the last of the three decrements makes count zero, that arriving process continues with S7.
Final remarks
The fork/join constructs provide a clear and compact way to express parallelism and synchronisation in algorithms. Key points to remember:
- fork creates concurrent flows; the child starts at a label and the parent continues after fork.
- join with a counter implements a fan-in: arriving computations decrement the counter atomically and only the last arriving computation continues the single continuation.
- Correctness requires atomic operations on synchronisation variables and careful handling of shared data to prevent races.


 | Explore Courses for Computer Science Engineering (CSE) exam |
 | Get EduRev Notes directly in your Google search |