Allocating Kernel Memory

Allocating kernel memory (buddy system and slab system)
The kernel uses specialised memory-allocation strategies to satisfy requests from kernel code and kernel data structures. Two widely used strategies are the buddy system and the slab allocator. Each targets different goals: the buddy system is a page-level allocator that makes splitting and coalescing of contiguous memory simple and fast, while the slab allocator provides caches of preinitialised objects to reduce allocation overhead and fragmentation for frequently used kernel data structures.
1. Buddy system
The buddy allocation system divides a contiguous region of memory into blocks whose sizes are powers of two. When the kernel requests memory, the allocator finds the smallest power-of-two block that fits the request. If no block of that size is free, a larger block is split into two equal-sized buddies repeatedly until a suitably sized block is produced. When two free buddies of the same size become adjacent, they can be merged (coalesced) back into a single larger block.
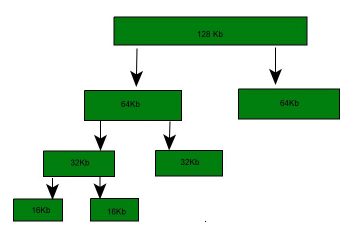
How it works (binary buddy example)
Suppose the available segment is 256 KB and the kernel requests 25 KB. The allocator finds the smallest power of two >= 25 KB, which is 32 KB. The 256 KB segment is split as follows:
- 256 KB → two 128 KB buddies (A1, A2).
- One 128 KB buddy is split into two 64 KB buddies (B1, B2).
- One 64 KB buddy is split into two 32 KB buddies (C1, C2).
- One 32 KB buddy is allocated to satisfy the 25 KB request; the other 32 KB buddy remains free.
A split block can be merged only with its unique buddy when that buddy is also free. For example, when C1 is freed and C2 is free, C1 and C2 can be coalesced to reform a 64 KB block; that 64 KB block can then be coalesced with its buddy to reform a 128 KB block, and so on, eventually restoring the original 256 KB segment if all parts are free.
Four types of buddy systems
- Binary buddy system
- Fibonacci buddy system
- Weighted buddy system
- Tertiary buddy system
Fibonacci buddy system
The Fibonacci buddy system uses block sizes equal to Fibonacci numbers rather than powers of two. If Zi denotes the i-th block size, it satisfies Zi = Zi-1 + Zi-2. Typical Fibonacci sizes include 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, ...
The Fibonacci approach reduces internal fragmentation for some allocation patterns but complicates address calculations and buddy arithmetic; original implementations either limited the set of sizes or required more expensive computations.
Why use the buddy system?
- Fast allocation and deallocation: splitting and coalescing operations are simple and efficient.
- Simple representation: free lists per block-size make locating free blocks straightforward.
- Easy coalescing: buddies are uniquely determined, enabling quick merges to form larger blocks.
- Low metadata overhead compared with maintaining arbitrary-sized free segments.
Advantages
- Little external fragmentation compared with naive variable-size allocators because free space is formed from power-of-two blocks that coalesce.
- Efficient to implement using a binary-tree or indexed free lists representing split blocks.
- Allocation and free operations are typically fast relative to best-fit or first-fit algorithms.
- Address calculation and locating a block's buddy are straightforward in binary and weighted schemes.
Coalescing
Coalescing is the process of merging adjacent free buddies to form larger blocks. It allows the allocator to recover large contiguous regions of memory after smaller allocations are released. For example, freeing C1 (a 32 KB block) allows coalescing with free C2 to form a 64 KB block B1; B1 can then be coalesced with its buddy B2 to produce 128 KB, and so on.
Drawbacks
- Internal fragmentation: allocations round up to the next power-of-two size, which can waste memory. For example, a 36 KB request is satisfied by a 64 KB block, leaving 28 KB unused within that block.
- Allocation granularity limited to power-of-two page multiples; for smaller or variable-sized kernel objects this can be inefficient.
- Although coalescing is simple, fragmentation patterns can still lead to wasted memory when many different sizes are used.
Implementation notes
- Typically implemented with separate free lists for each allowed block size (each power-of-two). The allocator inspects the free list for the requested size; if empty, it takes a block from a larger-size list and splits it until the requested size is reached.
- Time complexity is proportional to the number of splits/merges, which is bounded by the number of size classes (logarithmic in the maximum region size).
- In many kernels (including Linux), a buddy system is used as the page-level allocator and serves slab allocators by providing contiguous pages for slab creation.
2. Slab allocation
The slab allocator is designed to manage memory for kernel objects of specific types and sizes. It reduces fragmentation and improves allocation speed by keeping pools (caches) of preallocated objects ready for reuse. Slab allocation is especially effective when many short-lived or frequently requested kernel objects (such as file descriptors, inode structures or process descriptors) are created and destroyed.
Core concepts
- Slab: A slab is one or more physically contiguous pages that form the memory container for objects of a particular type stored in a cache.
- Cache: A cache holds slabs for one kernel data structure type. Each cache contains several slabs; each slab contains multiple object instances of the cache's type.
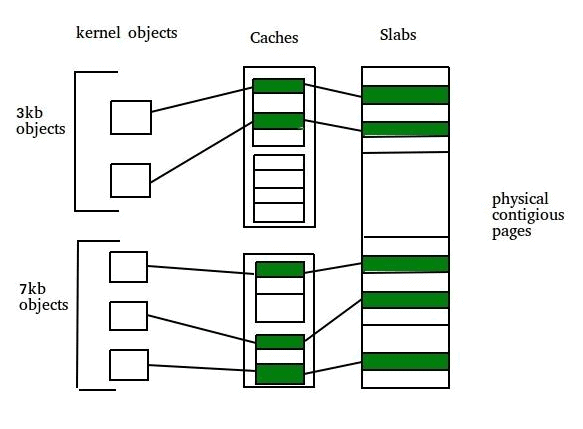
Examples of caches
- A cache for process descriptors (task_struct instances).
- A cache for file objects.
- A cache for semaphore objects.
How slab allocation is implemented
When a cache is created for a kernel data structure, several objects are allocated (within one or more slabs) and initially marked free. Each object may be initialised (constructor) so that allocations return objects in a ready-to-use state. When the kernel requests an object, the slab allocator assigns a free object from a slab in the cache and marks it used. When the object is released, it is marked free and returned to the cache for reuse.
An example of packing objects into a slab: a 12 KB slab (three contiguous 4 KB pages) could store six 2 KB objects. Initially all six objects are free; they are allocated one-by-one on requests and freed back to the cache when no longer needed.
Slab states (typical in Linux)
- Full: All objects in the slab are in use.
- Empty: All objects in the slab are free.
- Partial: Some objects are free and some are in use.
When allocating, the slab allocator prefers a free object from a partial slab. If no partial slab exists, it tries an empty slab. If none are available, the allocator requests new contiguous pages (from the page allocator, commonly the buddy system) to create a new slab for the cache.
Benefits of slab allocation
- Reduced fragmentation for kernel objects because each cache stores objects of a fixed type and size.
- Very fast allocation and deallocation since objects are preallocated and often require only pointer manipulation to mark used/free.
- Objects can be returned in an initialised state, avoiding repeated construction cost on each allocation.
- Effective when objects are frequently allocated and freed: returning objects to the cache makes them immediately available for subsequent requests.
Further implementation features and variants
- Object constructors/destructors: caches can run initialisation code when objects are first created and cleanup when slabs are freed.
- Per-CPU caches: caches local to a CPU reduce locking and improve performance on multiprocessor systems.
- Linux has multiple slab-family implementations: SLAB (the original), SLUB (a simpler per-CPU oriented design), and SLOB (a simpler allocator for small-memory systems). Each trades off complexity, fragmentation, and performance.
- Debugging features such as red-zoning, poisoning and object tracking help detect memory corruption or use-after-free bugs at the cost of extra memory.
Limitations of slab allocation
- When a wide variety of object sizes is required, many caches and slabs may be needed; this can increase memory overhead.
- Small internal fragmentation can still occur if object sizes do not pack perfectly into slabs.
- Complexity: the slab family of allocators adds bookkeeping and may require tuning (for example per-CPU caches) to obtain the best performance.
Comparison and typical use
- The buddy system is commonly used as the page allocator: it manages contiguous pages and supplies memory to higher-level allocators (such as slab). It is efficient for large allocations and makes coalescing straightforward.
- The slab allocator manages kernel objects of fixed sizes; it reduces allocation latency and fragmentation for those objects by caching preinitialised instances.
- In practice, kernel memory management layers cooperate: the slab allocator obtains contiguous pages from the buddy allocator to build slabs, and returns whole pages back to the buddy system when slabs are released.
Practical notes for interviews and exams
- Be ready to explain splitting and coalescing in the buddy system and to give a short example (e.g., 25 KB request satisfied by a 32 KB block from a 256 KB region through successive splits).
- Know the definitions of internal and external fragmentation, and which allocator primarily addresses which issue: slab reduces internal fragmentation for small kernel objects; buddy reduces external fragmentation at page granularity but can suffer internal fragmentation due to power-of-two rounding.
- Recall Linux-specific points: slab-family variants (SLAB, SLUB, SLOB), slab states (full/partial/empty), and that the buddy allocator commonly supplies pages to slab caches.
- If asked about performance, mention per-CPU caches, reduced locking, and rapid reuse of objects as key slab performance features; mention low metadata and simple buddy arithmetic for buddy performance.
Summary
The buddy system and slab allocator are complementary kernel memory-allocation strategies. The buddy system provides simple, fast page-level allocation with easy coalescing of power-of-two blocks but can waste space due to rounding. The slab allocator provides caches of fixed-size kernel objects to avoid repeated initialisation and to reduce fragmentation and allocation latency. Modern kernels combine these techniques to satisfy different classes of kernel memory requests efficiently.


 | Explore Courses for Computer Science Engineering (CSE) exam |
 | Get EduRev Notes directly in your Google search |