Extendible Hashing


Introduction
Extendible Hashing is a dynamic hashing technique that uses a directory of pointers and fixed-size buckets to store records. The hash function adapts as the structure grows: when buckets overflow the directory and buckets may be reorganised so that the file can grow without a full reorganisation. Extendible hashing is widely used for secondary indexing and dynamic file organisation in database systems.
Main features
- Directory: an array of pointers; each entry stores the address of a bucket. The directory size can change (grow) by doubling, and each directory entry is identified by a bit pattern (the directory id).
- Buckets: fixed-capacity containers that store actual records or keys. Multiple directory entries may point to the same bucket.
- Dynamic hash function: the number of bits the hash function returns (used to index into the directory) changes with the global depth.
Basic structure of Extendible Hashing

Frequently used terms
- Directory: an array whose size is 2Global Depth; each directory entry holds a pointer to a bucket.
- Bucket: a block that stores up to a fixed number of records (bucket size). More than one directory entry can point to the same bucket when that bucket's local depth is less than the global depth.
- Global Depth: the number of least significant bits (LSBs) of the hash value that the directory currently uses; directory size = 2Global Depth.
- Local Depth: the number of hash bits that a particular bucket uses to distinguish its contents; for any bucket Local Depth ≤ Global Depth.
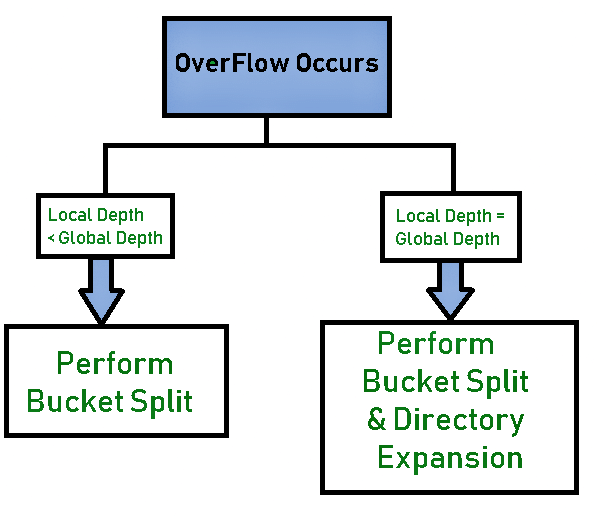
- Bucket split: when a bucket overflows, the bucket may be split into two buckets and some entries rehashed between them.
- Directory expansion (doubling): when an overflowing bucket has Local Depth = Global Depth, the directory is doubled (Global Depth is incremented) before splitting the bucket.
Basic working of Extendible Hashing

- Choose a hash function and compute hash value: for a record key compute its hash and consider its binary representation. For string keys, a common approach is to take the ASCII code(s) of characters and treat them as integers before hashing.
- Use Global Depth bits: take the Global Depth number of least significant bits (LSBs) of the hash value to index into the directory; that directory entry points to the bucket where the key should be stored.
- Insert into the bucket: if the bucket has space, place the record there and stop.
- If bucket overflows, handle overflow: examine the overflowing bucket's Local Depth and follow the appropriate action.
- Case 1 - Local Depth = Global Depth: double the directory (increment Global Depth by 1), then split the overflowing bucket into two buckets and increment the Local Depth of the split buckets by 1. Redistribute (re-hash) the entries of the original bucket according to the new number of bits.
- Case 2 - Local Depth < Global Depth: split the overflowing bucket into two buckets and increment only the Local Depth of those buckets by 1; update the relevant directory entries to point to the correct new buckets; do not double the directory. Redistribute the bucket's entries according to its new Local Depth.
- After split/expansion: rehash only the entries from the bucket that was split (these are moved between the two new buckets using the additional bit) and then continue insertion.
- Finish insertion: after rehashing the necessary entries the key is placed and the operation completes.
Worked example
Problem: Insert the keys 16, 4, 6, 22, 24, 10, 31, 7, 9, 20, 26 using extendible hashing.
Assumptions:
- Bucket size: 3 (each bucket can hold up to 3 keys)
- Hash function: use the key value in binary; the directory index is the Global Depth number of LSBs of the key's binary form.
- Initial Global Depth and Local Depths: assume Global Depth = 1 and each existing bucket has Local Depth = 1 initially.
Step A - Binary forms of keys:
- 16 - 10000
- 4 - 00100
- 6 - 00110
- 22 - 10110
- 24 - 11000
- 10 - 01010
- 31 - 11111
- 7 - 00111
- 9 - 01001
- 20 - 10100
- 26 - 11010
Initial directory (Global Depth = 1):
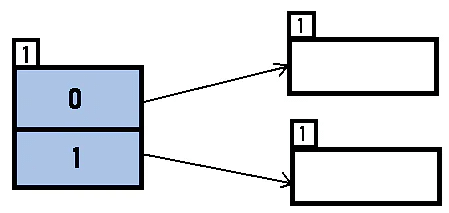
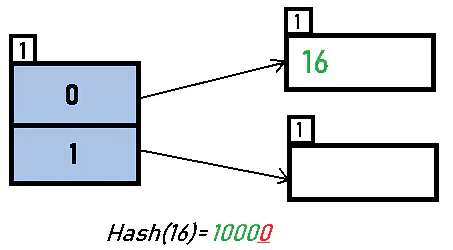
Insert 16: 16 (10000) → 1 LSB = 0 → directory id = 0. Insert into bucket 0.
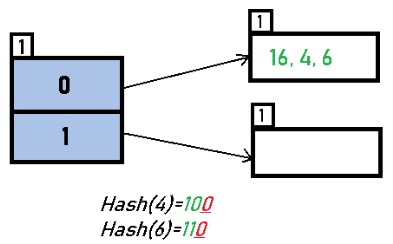
Insert 4 and 6: 4 (00100) and 6 (00110) both have LSB = 0 and go to the same bucket as 16. No overflow yet if bucket capacity is 3.
Insert 22: 22 (10110) has LSB = 0. The bucket for directory 0 already contains 16, 4, 6 so inserting 22 causes overflow.
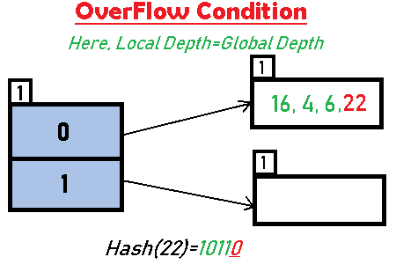
Since the overflowing bucket's Local Depth = Global Depth (both are 1), apply Case 1: double the directory (Global Depth becomes 2), split the overflowing bucket, and increment the local depth of the split buckets to 2. Rehash the entries of the original bucket using 2 LSBs.

Note: buckets with Local Depth less than Global Depth will be pointed to by multiple directory entries. After directory doubling some directory entries may point to the same physical bucket until that bucket is split.
Insert 24 and 10: 24 (11000) → 2 LSBs = 00 or 24(11000) gives appropriate directory; 10 (01010) → 2 LSBs = 10; they map to buckets identified by 00 and 10 respectively and no overflow occurs for these insertions.

Insert 31, 7, 9: 31 (11111) → 2 LSBs = 11; 7 (00111) → 2 LSBs = 11; 9 (01001) → 2 LSBs = 01. These keys map to buckets pointed to by directory entries 01 and 11. No overflow occurs if capacity allows.
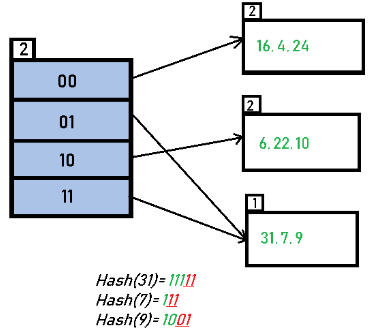
Insert 20: 20 (10100) → 2 LSBs = 00; inserting into the bucket for directory 00 causes an overflow.

Again the overflowing bucket has Local Depth = Global Depth (both equal to 2), so double the directory (Global Depth becomes 3), split the bucket, increment the local depth of the split bucket(s) and rehash the entries of the split bucket using 3 LSBs.
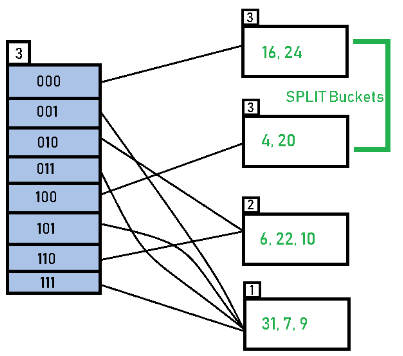
Insert 26: 26 (11010) → 3 LSBs = 010; with Global Depth = 3 it maps to directory entry 010 and is inserted into the corresponding bucket.
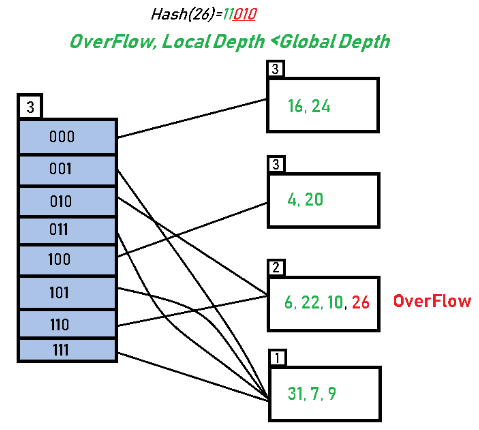
When the bucket that receives 26 overflows, if its Local Depth < Global Depth (for example 2 < 3), then only that bucket is split (increment the bucket's Local Depth) and directory entries are adjusted to point to the newly created buckets; the directory is not doubled.
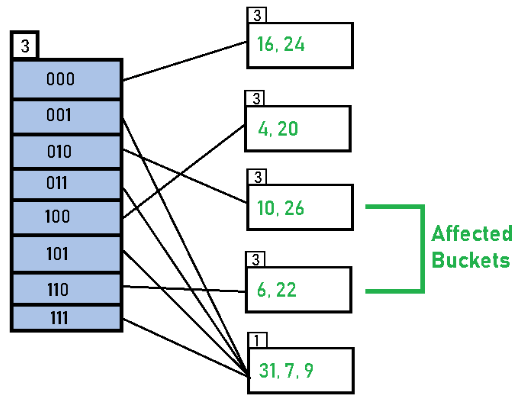
Result: after processing all 11 keys as above the extendible hash file grows by splitting buckets and occasionally doubling the directory; the final layout is obtained when no further overflows occur after insertion and rehashing.
Key observations
- A bucket may be referenced by multiple directory entries when its Local Depth is less than the Global Depth.
- On an overflow only the entries in the overflowing bucket are rehashed (not the whole file); rehashing uses the updated Local Depth (or Global Depth when directory was doubled).
- If the Local Depth of an overflowing bucket equals the Global Depth, the directory must be doubled (Global Depth incremented) before splitting that bucket.
- Bucket capacity is fixed; the algorithm grows by splitting buckets and doubling the directory, not by increasing bucket size.
Advantages
- Search, insertion and deletion operations are typically constant-time on average (O(1)) because only a few buckets are inspected; costly full reorganisation of the file is avoided.
- The file grows dynamically without a monolithic reorganisation; records are redistributed locally at bucket splits.
- Storage grows incrementally; keys are rehashed according to the new hash-bit usage when splits or directory expansions occur.
Limitations
- The directory can grow large if many directory entries point to distinct buckets; this can waste memory for the directory pointers.
- Bucket size is fixed; if distribution of keys is skewed many splits and directory growth may occur.
- Pointer overhead increases when Global Depth becomes much larger than some buckets' Local Depth (multiple pointers refer to the same bucket).
- Implementation is more complex compared with static hashing schemes.
Data structures commonly used for implementation
- Array: to implement the directory (an array indexed by bit patterns).
- Linked list or array of records: to implement the contents of each bucket.
- B+ trees: sometimes mentioned as alternative indexing structures; keep this entry only as a recognised indexing structure rather than a direct implementation of extendible hashing.
Practical notes and applications
History: Extendible hashing was proposed to support dynamic files efficiently (classic references include the work by Fagin, Nievergelt, Pippenger and Strong, 1979).
When to use: use extendible hashing when the file size is expected to grow unpredictably and when fast point lookups with low average I/O are required (for example, as a secondary index in database systems).
Implementation tips: pick a bucket size that matches block size on disk (for disk-based systems); maintain and update Local Depth with each bucket; when doubling the directory reassign pointers correctly to avoid losing access to buckets.
Summary
Extendible hashing is a flexible, dynamic hashing scheme that grows by splitting overflowing buckets and doubling a directory when necessary. It keeps most reorganisation local, supports efficient average-time operations, and is well suited for dynamic data sets with unpredictable growth. Understanding Global Depth, Local Depth, and the mechanics of bucket splitting and directory doubling is central to implementing and using extendible hashing correctly.
FAQs on Extendible Hashing
| 1. How does extendible hashing handle bucket overflow differently from static hashing? |  |
| 2. What's the difference between global depth and local depth in extendible hashing? | |
| 3. Why do we need a directory in extendible hashing instead of direct bucket access? | |
| 4. Can bucket splitting in extendible hashing cause the directory to shrink? | |
| 5. How do hash functions determine which bucket a record goes to in extendible hashing? | |


 | Explore Courses for Computer Science Engineering (CSE) exam |
 | Get EduRev Notes directly in your Google search |