Computer Science Engineering (CSE) Exam > Computer Science Engineering (CSE) Notes > Computer Architecture & Organisation (CAO) > Single Cycle & Pipeline Datapath
Single Cycle & Pipeline Datapath

Single Cycle Datapaths
Single Datapaths is equivalent to the original single-cycle datapath The data memory has only one Address input. The actual memory operation can be determined from the MemRead and MemWrite control signals. There are separate memories for instructions and data There are 2 adders for PC-based computations and one ALU. The control signals are the same.
Pipeline Datapaths
The goal of pipelining is to allow multiple instructions to be executed at the same time. We may need to perform several operations in a cycle. Increment the PC and add registers at the same time. Fetch one instruction while another one reads or writes data. Like the single-cycle datapath, a pipeline processor needs to duplicate hardware elements that are needed in the same clock cycle.
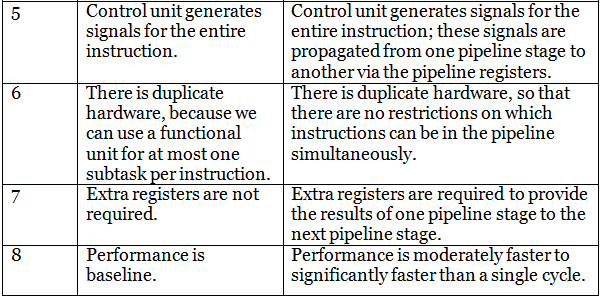
Differences between Single Datapath and Pipeline Datapath :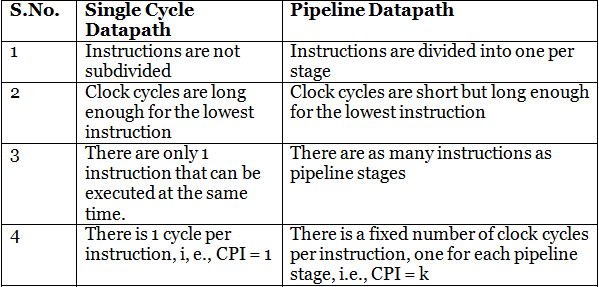
The document Single Cycle & Pipeline Datapath is a part of the Computer Science Engineering (CSE) Course Computer Architecture & Organisation (CAO).
All you need of Computer Science Engineering (CSE) at this link: Computer Science Engineering (CSE)
About this Document

4.71/5 Rating

Apr 30, 2026 Last updated
Related Exams
Document Description: Single Cycle & Pipeline Datapath for Computer Science Engineering (CSE) 2026 is part of Computer Architecture & Organisation (CAO) preparation. The notes and questions for Single Cycle & Pipeline Datapath have been prepared according to the Computer Science Engineering (CSE) exam syllabus. Information about Single Cycle & Pipeline Datapath covers topics like and Single Cycle & Pipeline Datapath Example, for Computer Science Engineering (CSE) 2026 Exam. Find important definitions, questions, notes, meanings, examples, exercises and tests below for Single Cycle & Pipeline Datapath.
Introduction of Single Cycle & Pipeline Datapath in English is available as part of our Computer Architecture & Organisation (CAO) for Computer Science Engineering (CSE) & Single Cycle & Pipeline Datapath in Hindi for Computer Architecture & Organisation (CAO) course. Download more important topics related with notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free. Computer Science Engineering (CSE): Single Cycle & Pipeline Datapath
Description
Single Cycle & Pipeline Datapath of Computer Architecture & Organisation covers all the important topics, helping you prepare for the Computer Science Engineering (CSE) exam on EduRev.
Information about Single Cycle & Pipeline Datapath
In this doc you can find the meaning of Single Cycle & Pipeline Datapath defined & explained in the simplest way possible. Besides explaining types of Single Cycle & Pipeline Datapath theory, EduRev gives you an ample number of questions to practice Single Cycle & Pipeline Datapath tests, examples and also practice Computer Science Engineering (CSE) tests
 | Explore Courses for Computer Science Engineering (CSE) exam |
 | Get EduRev Notes directly in your Google search |
Related Searches
Single Cycle & Pipeline Datapath, Single Cycle & Pipeline Datapath, study material, Single Cycle & Pipeline Datapath, mock tests for examination, Free, Sample Paper, practice quizzes, Viva Questions, shortcuts and tricks, ppt, past year papers, Semester Notes, MCQs, pdf , Previous Year Questions with Solutions, Summary, video lectures, Exam, Objective type Questions, Important questions, Extra Questions;