Redundancy in Databases | Database Management System (DBMS) - Computer Science Engineering (CSE) PDF Download
Introduction
Redundancy in DBMS is having several copies of the same data in the database, for example, storing the complete details of the department such as department_id, department_name, and department_head repeatedly in every student record. Redundancy may cause inconsistency in data when they are not properly updated. It may also cause an increase in storage space and cost.
Scope
- In this article, we will understand the concept of redundancy in DBMS.
- We will also understand the problems caused by redundancy in DBMS, such as insertion anomaly, deletion anomaly, and updation anomaly.
- We will also understand the advantages and disadvantages of redundancy in DBMS.
What is Redundancy in DBMS?
Redundancy in DBMS is the problem that arises when the database is not normalized. It is the concept of storing multiple copies of the same data in different parts of the database.
Example for Redundancy in DBMS?
Let's understand the concept of redundancy in DBMS with a simple student table.
In this student table, we have repeated the same department details, dept_id, dept_name, and dept_head in every student record. This causes redundancy in the student table.
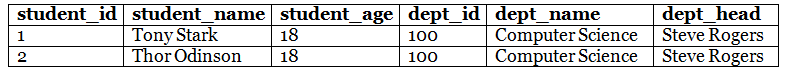
How does Data Redundancy Occur?
Data redundancy in DBMS may occur due to any of the below reasons.
- The database is not normalized through DBMS normalization.
- The same data is stored in multiple places by multiple systems causing redundancy in data.
- Mistake during database design causes the same data to be stored multiple times.
Problems caused by redundancy in Database
Redundancy in DMBS can cause several problems while performing operations on data such as insert, delete, and update. Let's use the below student table to understand insertion, updation, and deletion anomalies.
- Insertion Anomaly: An insertion anomaly occurs when specific details cannot be inserted into the database without the other details.
Example: Without knowing the department details, we cannot insert the student details in the above table. The student details (student_id, student_name, and student_age) depends on the department details (dept_id, dept_name, and dept_head). - Deletion Anomaly: Deletion anomaly occurs when deleting specific details loses some unrelated information from the database.
Example: If we delete the student with student_id 3 from the above student table, we also lose the department details with dept_id 101. Deleting student details result in losing unrelated department details. - Updation Anomaly: Updation anomaly occurs when there is data inconsistency resulting from a partial data update.
Example: We wanted to update the dept_head to Peter Parker for dept_id 101; we need to update it in all places. If the update didn't occur in all the places (partial update), it may result in data inconsistency.
How To Avoid Redundancy in DBMS?
Redundancy in DBMS can be avoided by following the below approaches.
- Redundancy in DBMS can be avoided by normalizing the data through database normalization.
- Redundancy can be avoided using Master Data. Master data is a single source of data accessed by several applications and systems.
- Proper database architecture design can avoid data redundancy.
Advantages of Data Redundancy
- Data redundancy can help disaster recovery by backing up the data in a different place.
- Data redundancy can help during malicious attacks. Data integrity can be verified if we have multiple copies of the same data.
Disadvantages of Data Redundancy
- Data redundancy can cause an increase in storage space due to duplicate data which may increase the cost of the data storage.
- Data redundancy increase the size of the database, which increases the complexity of performing operations on the data.
- Data redundancy can cause inconsistency in data due to partial updates to the database.
Conclusion
- Redundancy in DBMS is having several copies of the same data in the database.
- Redundancy in DBMS occurs when the database is not normalized.
- Redundancy causes insertion, deletion, and updation anomalies.
- Redundancy can be avoided by normalizing the database, maintaining master data, etc.
|
62 videos|66 docs|35 tests
|

|
Dec 23, 2024 Last updated |

|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
Previous Year Questions with Solutions
,Free
,shortcuts and tricks
,Exam
,study material
,video lectures
,Semester Notes
,Redundancy in Databases | Database Management System (DBMS) - Computer Science Engineering (CSE)
,Sample Paper
,Objective type Questions
,past year papers
,mock tests for examination
,practice quizzes
,Viva Questions
,Redundancy in Databases | Database Management System (DBMS) - Computer Science Engineering (CSE)
,Summary
,Redundancy in Databases | Database Management System (DBMS) - Computer Science Engineering (CSE)
,Extra Questions
,Important questions
,MCQs
,ppt
;






Redundancy in Databases Free PDF Download
Importance of Redundancy in Databases
Redundancy in Databases Notes
Redundancy in Databases Computer Science Engineering (CSE) Questions
Study Redundancy in Databases on the App
|
© EduRev
|
Education Revolution
|



|




