Natural Language Processing Chapter Notes | Artificial Intelligence for Class 10 PDF Download
| Table of contents |
|
| What is NLP? |
|
| Human Language VS Computer Language |
|
| Data Processing |
|
| Bag of word Algorithm |
|
| TFIDF |
|

What is NLP?
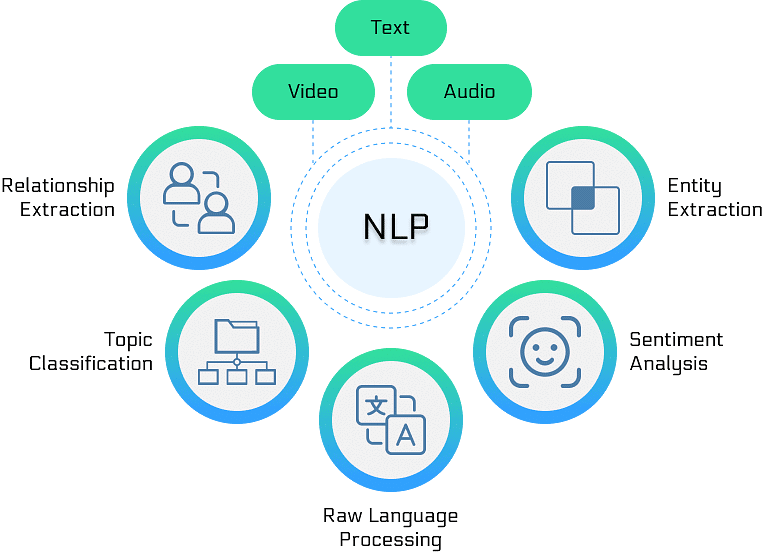
- Natural Language Processing (NLP) is a sub-field of AI that focuses on enabling computers to understand human language, both spoken and written, and generate appropriate responses by processing it. NLP is a component of Artificial Intelligence.
- So far, we have covered two domains of AI: Data Science and Computer Vision. NLP is the third domain.
- Data Science: This domain involves applying mathematical and statistical principles to data. In simple terms, Data Science is the study of data, which can be of three types: audio, visual, and textual.
- Computer Vision: This domain involves identifying symbols from given objects (such as pictures), learning patterns, and using a camera to alert or predict future objects.
Applications of Natural Language Processing
Here are some real-life applications of Natural Language Processing (NLP):
- Automatic Summarization: Summarizes the content of documents and information, extracting key emotional information from text to understand reactions, especially on social media.
- Sentiment Analysis:
- Definition: Identifies sentiment within multiple posts or even within a single post where emotions may not be explicitly expressed.
- Usage: Companies utilize it to gauge opinions and sentiments to understand customer thoughts about their products and services.
- Outcomes: Sentiments can be classified as positive, negative, or neutral.
- Text Classification:
- Function: Assigns predefined categories to documents to help organize information and simplify tasks.
- Example: Spam filtering in email systems.
- Virtual Assistants:
- Examples: Google Assistant, Cortana, Siri, Alexa, etc., have become essential in our daily lives.
- Capabilities:
- Engage in conversations.
- Access personal data to assist with tasks such as note-taking, making calls, sending messages, and more.
- Technology: Utilize speech recognition to understand and respond to speech.
- Future Outlook: Significant advancements are expected in this field in the near future according to recent research.
ChatBots
One of the most common applications of Natural Language Processing is a chatbot. Let's explore some chatbots and see how they work:
- Mitsuku Bot: https://www.pandorabots.com/mitsuku/
- Cleverbot: https://www.cleverbot.com/
- Jabberwacky: http://www.jabberwacky.com/
- Haptik: https://haptik.ai/contact-us
Types of ChatBots
From this experience, we can understand that there are two types of chatbots around us: Script-bots and Smart-bots.
Let's explore what each of them is:
Script Bot:
- Easy to Create: Script bots are straightforward to develop, making them accessible for various applications.
- Based on a Predefined Script: These bots operate using a set script, responding to user inputs in a predetermined manner.
- Usually Free and Simple to Add: Script bots are often available at no cost and can be easily integrated into messaging platforms.
- Limited Language Processing: They have minimal or no capabilities for understanding or processing natural language, which restricts their functionality.
- Limited Functions: Script bots offer a narrow range of functions, primarily focused on specific tasks.
- Example: These bots are commonly found in customer service sections of various companies, assisting with basic inquiries.
Smart Bot:
- Adaptable and Powerful: Smart bots are highly flexible and capable of handling complex tasks.
- Use Extensive Databases: They rely on vast databases and various resources to provide accurate and relevant responses.
- Learn and Improve: Smart bots have the ability to learn from interactions and improve their performance over time.
- Requires Coding for Setup: Setting up a smart bot typically involves coding and technical expertise.
- Wide Range of Functions: These bots offer a broad spectrum of functions, making them suitable for diverse applications.
- Examples: Well-known smart bots include Google Assistant, Alexa, Cortana, and Siri, which perform a variety of tasks and assist users in numerous ways.
Human Language VS Computer Language
Human Language
- Our brain continually processes the sounds it hears, trying to make sense of them all the time.
- Example: In a classroom, while the teacher delivers a lesson, our brain is constantly processing everything and storing it. If a friend whispers something, our brain automatically shifts focus from the teacher’s speech to the friend's conversation.
- Thus, the brain processes both sounds but prioritizes the one we are more interested in.
- Sound reaches the brain through a long pathway. As a person speaks, the sound travels from their mouth to the listener’s eardrum, where it is converted into neuron impulses, transported to the brain, and processed.
- After processing the signal, the brain understands its meaning. If clear, the signal is stored; otherwise, the listener seeks clarification from the speaker. This is how humans process languages.
Computer Language
- Computers understand numbers. Everything sent to a machine must be converted to numbers. When typing, a single mistake can cause the computer to throw an error and not process that part. Machine communications are basic and simple.
- To make machines understand our language, what challenges might they face?
Here are some key difficulties: - Arrangement of Words and Meaning
- Human languages have rules involving nouns, verbs, adverbs, and adjectives. A word can function as a noun at one time and an adjective at another. These rules provide structure to a language.
- Syntax: Syntax refers to the grammatical structure of a sentence.
- Semantics: Semantics refers to the meaning of a sentence.
- Examples to Understand Syntax and Semantics:
- Different Syntax, Same Semantics:
- Example: 2 + 3 = 3 + 2
- Both statements are written differently but have the same meaning, which is 5.
- Different Semantics, Same Syntax:
- Example: 2 / 3 (Python 2.7) ≠ 2 / 3 (Python 3)
- Both statements have the same syntax but different meanings. In Python 2.7, the result is 1, while in Python 3, the result is 1.5.
- Different Syntax, Same Semantics:
Multiple Meanings of a word
To understand the complexity of natural language, consider the following three sentences:
- His face turned red after he found out that he had taken the wrong bag.
- What does this mean? Is he feeling ashamed because he took someone else's bag by mistake? Or is he angry because he failed to steal the bag he was targeting?
- The red car zoomed past his nose.
- This is likely talking about the color of the car that quickly passed very close to him.
- His face turns red after consuming the medicine.
- Is he having an allergic reaction? Or is the taste of the medicine unbearable for him?
In these examples, context is crucial. We intuitively understand sentences based on our history with the language and the memories built over time. The word "red" is used in three different ways, each changing its meaning based on the context of the statement. Therefore, in natural language, it's important to recognize that a word can have multiple meanings, and these meanings fit into the statement according to its context.
Perfect Syntax, no Meaning
- Sometimes, a statement can be grammatically correct but lack meaningful content.
- For example: "Chickens feed extravagantly while the moon drinks tea."
- This sentence follows proper grammar rules but doesn’t convey any sensible meaning. In human language, achieving a balance between correct syntax and meaningful semantics is essential for clear understanding.
Data Processing
- To enable machines to understand and generate natural languages, Natural Language Processing (NLP) starts by converting human language into numerical data. The initial step in this process is Text Normalization.
- Text normalization involves cleaning and simplifying textual data to reduce its complexity. This process transforms the text into a more manageable form, making it easier for the machine to handle.
Text Normalization
- In text normalization, we process the text to simplify and standardize it. This involves working with a collection of texts, collectively known as a corpus.
Sentence Segmentation
Sentence segmentation involves breaking the entire corpus into individual sentences. Each sentence is treated as a separate data unit, thus reducing the complexity of the corpus.
Example:
- Before Sentence Segmentation:
- “You want to see the dreams with close eyes and achieve them? They’ll remain dreams, look for AIMs and your eyes have to stay open for a change to be seen.”
- After Sentence Segmentation:
- You want to see the dreams with close eyes and achieve them?
- They’ll remain dreams, look for AIMs and your eyes have to stay open for a change to be seen.
Tokenization
After segmenting sentences, we break each sentence into smaller units called tokens. Tokens can be words, numbers, or special characters.
Removal of Stopwords
In this step, we remove stopwords, which are common words that do not contribute much meaning to the text. Additionally, special characters and numbers may be removed based on the context of the corpus.
Example:
- You want to see the dreams with close eyes and achieve them?
- the removed words would be
- to, the, and, ?
- The outcome would be:
- You want see dreams with close eyes achieve them
Converting text to a common case
We convert all text to a consistent case, typically lower case, to ensure that words are not treated differently based on case sensitivity.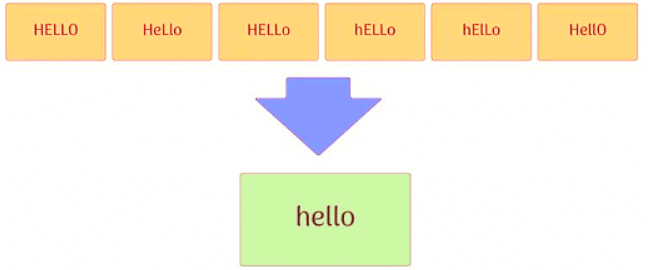
Stemming
Stemming reduces words to their base or root form by removing prefixes and suffixes. This process may produce words that are not necessarily meaningful.
Example:
Difference between Stemming and Lemmatization
- Stemming: The stemmed word may not always be meaningful. Example: Caring → Car
- Lemmatization: The lemma is always a meaningful word. Example: Caring → Care
Bag of word Algorithm
- Feature Extraction: The Bag of Words model helps in extracting features from text, which is useful for machine learning algorithms. It focuses on the occurrences of each word to build a vocabulary for the corpus.
- Vector Creation: The BoW model creates vectors representing the count of word occurrences in a document. This results in a straightforward and interpretable representation of text.
- Normalization Process: After text normalization, the Bag of Words algorithm identifies unique words and their frequencies from the processed corpus.
- Output: The output includes:
- A list of unique words (vocabulary) from the corpus.
- The frequency of each word (how often it appears in the text).
- Indifference to Order: The term “bag” implies that the order of words or sentences does not affect the model. The primary focus is on the unique words and their frequencies, regardless of their sequence in the text.
Steps of the bag of words algorithm
- Data Collection and Pre-processing: Gather and clean the textual data to prepare it for analysis.
- Create Dictionary: Generate a list of all unique words found in the corpus, forming the vocabulary.
- Create Document Vectors: For each document, count the occurrences of each word from the vocabulary to create a vector representation of the document.
- Document Vectors for All Documents: Repeat the process for all documents in the corpus to build a comprehensive set of document vectors.
Example:
Step 1: Collecting data and pre-processing it.
Raw Data
- Document 1: Aman and Anil are stressed
- Document 2: Aman went to a therapist
- Document 3: Anil went to download a health chatbot
Processed Data
- Document 1: [aman, and, anil, are, stressed ]
- Document 2: [aman, went, to, a, therapist]
- Document 3: [anil, went, to, download, a, health, chatbot]
Note that in the stopwords removal step, no tokens were removed because the dataset is small, and the frequency of all words is nearly equal. Consequently, no word can be considered less valuable than the others.
Step 2: Create Dictionary
In NLP, a dictionary refers to a list of all unique words present in the corpus. If words are repeated across different documents, each word is included only once in the dictionary.
Dictionary: Step 3: Create a document vector
Step 3: Create a document vector
In NLP, a document vector represents the frequency of each word from the vocabulary in a specific document.
How to make a document vector table?
In a document vector, the vocabulary is listed in the top row. For each word in the document:
- If the word matches a word in the vocabulary, put a 1 under it.
- If the same word appears again, increment the previous value by 1.
- If the word does not appear in the document, put a 0 under it.

Step 4: Creating a document vector table for all documents
In this table, the header row contains the vocabulary of the corpus and three rows correspond to three different documents. Take a look at this table and analyze the positioning of 0s and 1s in it.
Finally, this gives us the document vector table for our corpus. But the tokens have still not converted to numbers. This leads us to the final steps of our algorithm: TFIDF.
TFIDF
TFIDF stands for Term Frequency & Inverse Document Frequency.
Term Frequency
- Term Frequency: Term frequency refers to how often a word appears in a specific document.
- Term frequency can be identified in the document vector table, where the frequency of each word in the vocabulary is noted for each document.
Example of Term Frequency: Here, as we can see that the frequency of each word for each document has been recorded in the table. These numbers are nothing but the Term Frequencies!
Here, as we can see that the frequency of each word for each document has been recorded in the table. These numbers are nothing but the Term Frequencies!
Inverse Document Frequency
To understand IDF (Inverse Document Frequency), we should first understand DF (Document Frequency).
DF (Document Frequency)
Definition of Document Frequency (DF): Document Frequency refers to the number of documents in which a particular word appears, regardless of how many times it appears in each document.
Example of Document Frequency:
From the table, we can observe that:
- The document frequency of 'aman', 'anil', 'went', 'to', and 'a' is 2, as they have appeared in two documents.
- The rest of the words have appeared in just one document, so their document frequency is 1.
IDF (Inverse Document Frequency)
Definition of Inverse Document Frequency (IDF): Inverse Document Frequency is calculated by taking the total number of documents and dividing it by the document frequency (the number of documents in which a word occurs). This helps to determine how important a word is within the entire corpus.
Example of Inverse Document Frequency:
Formula of TFIDF
The formula of TFIDF for any word W becomes:
TFIDF(W) = TF(W) * log( IDF(W) )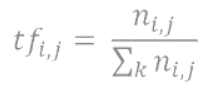
Example of TFIDF: Here, we can see that the IDF values for Aman in each row are the same and a similar pattern is followed for all the words in the vocabulary. After calculating all the values, we get:
Here, we can see that the IDF values for Aman in each row are the same and a similar pattern is followed for all the words in the vocabulary. After calculating all the values, we get:
Finally, the words have been converted to numbers. These numbers represent the values of each document. In this small dataset, even common words like 'are' and 'and' have a high value. However, as the IDF value increases, the significance of a word decreases. For instance:
- Total Number of documents: 10
- Number of documents in which 'and' occurs:10
- IDF(and): 10/10 = 1
- Logarithm: log(1) = 0
- Value of 'and': 0
- On the other hand, for the word 'pollution':
- Number of documents in which 'pollution' occurs: 3
- IDF(pollution): 10/3 ≈ 3.3333
- Logarithm: log(3.3333) ≈ 0.522
- Value of 'pollution': 0.522
- This example demonstrates that the word 'pollution' has significant value in the corpus due to its higher IDF score.
Applications of TFIDF
TF-IDF is a widely used technique in the field of Natural Language Processing (NLP). Here are some of its important applications:
- Document Classification: TF-IDF helps in categorizing different types and genres of documents by analyzing the importance of words within them.
- Topic Modelling: It assists in identifying the main topics present within a collection of documents by highlighting the most relevant terms.
- Information Retrieval Systems: TF-IDF is used to extract significant information from a set of documents, helping to retrieve relevant data efficiently.
- Stop Word Filtering: This application involves removing unimportant words from a text to focus on more meaningful content, improving the quality of text analysis.
|
26 videos|88 docs|8 tests
|
FAQs on Natural Language Processing Chapter Notes - Artificial Intelligence for Class 10
| 1. What is Natural Language Processing (NLP) and its significance? |  |
| 2. How do human language and computer language differ? | |
| 3. What is data processing in the context of NLP? | |
| 4. Can you explain the Bag of Words algorithm? | |
| 5. What is TF-IDF and how is it used in NLP? | |



Natural Language Processing Chapter Notes | Artificial Intelligence for Class 10
,Extra Questions
,mock tests for examination
,video lectures
,ppt
,Objective type Questions
,past year papers
,practice quizzes
,Exam
,Previous Year Questions with Solutions
,MCQs
,Natural Language Processing Chapter Notes | Artificial Intelligence for Class 10
,Sample Paper
,Important questions
,Summary
,Free
,Semester Notes
,study material
,shortcuts and tricks
,Viva Questions
,Natural Language Processing Chapter Notes | Artificial Intelligence for Class 10
;






Chapter Notes: Natural Language Processing Free PDF Download
Importance of Chapter Notes: Natural Language Processing
Chapter Notes: Natural Language Processing
Chapter Notes: Natural Language Processing Class 10 Questions
Study Chapter Notes: Natural Language Processing on the App
|
© EduRev
|
Education Revolution
|



|





