Q1: Consider the alphabet ∑= {0, 1}, the null/empty string A and the sets of strings X0, X1, and X2 generated by the corresponding non-terminals of a regular grammar.
X0, X1, and X2 are related as follows.
X0 = 1X1
X1, = 0X1 + 1X2
X2 = 0X1 + {1}
Which one of the following choices precisely represents the strings in X0? (2015 SET-2)
(a) 10(0* + (10)*)1
(b) 10(0* + (10)*)*1
(c) 1(0 + 10)*1
(d) 10(0 + 10)*1 + 110(0 + 10)*1
Ans: (c)
Sol:
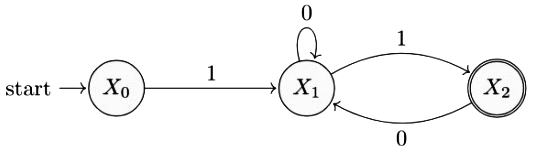
Convert the given transitions to a state diagram
From the given diagram we can write
X0 = 1(0 + 10)*1
Correct Option: C
Q2: Consider the following two statements:
P: Every regular grammar is LL(1)
Q: Every regular set has a LR(1) grammar
Which of the following is TRUE? (2007)
(a) Both P and Q are true
(b) P is true and Q is false
(c) P is false and Q is true
(d) Both P and Q are false
Ans: (c)
Sol:
LL Grammar: Grammars which can be parsed by an LL parser.
LL parser: Parses the input from Left to right, and constructs a Leftmost derivation of the sentence(i.e. it is always the leftmost non-terminal which is rewritten). LL parser is a top-down parser for a subset of context-free languages.
An LL parser is called an LL(k) parser if it uses k tokens of lookahead when parsing a sentence and can do it without backtracking.
Consider a Grammar G:
This grammar is Regular but cannot be parsed by a LL(1) parser w/o backtracking, because here, lookahead
is of 1 symbol only and in the grammar for both productions, parser while looking at just one(first) symbol, which is a, fails to select the correct rule for parsing.
Hence, not every Regular grammar is LL(1); Statement P is False.
LR Grammar: Grammars which can be parsed by LR parsers.
LR Parser: They are a type of bottom-up parsers that efficiently handle deterministic context-free languages (DCFL) in guaranteed linear time.
All Regular Languages are also DCFL. Hence, they all can be parsed by a LR(1) grammar.
Hence, Statement Q is True.
Q3: Consider the regular grammar below
S → bS ∣ αΑ ∣ ε
A → aS ∣ bA
The Myhill-Nerode equivalence classes for the language generated by the grammar are (2006)
(a) {w ∈ (a + b)* | #a(w) is even) and {w ∈ (a + b)* | #a(w) is odd}
(b) {w ∈ (a + b)* | #a(w) is even) and {w ∈ (a + b)* | #b(w) is odd}
(c) {w ∈ (a + b)* | #a(w) = #b(w) and {w ∈ (a + b)* | #a(w) ≠ #b(w)}
(d) {ϵ}, {wa | w ∈ (a + b)* and {wb | w ∈ (a + b)* }
Ans: (a)
Sol:
Option A is the correct answer.
Before doing this question we should know the following points.
- Number of equivalence classes = Number of states in Minimal FA (MFA)
- In MFA, we get some language at each and every stage. These languages are mutually exclusive and are called equivalence classes.
So to solve this question, first convert the given Right Linear Regular Grammar into DFA.
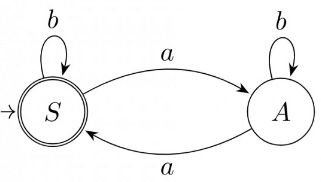
There are two states named S and A.
The language at state S represents one Equivalence Class. {w ∈ (a + b)* #a(w) is even}
The language at State A represents another Equivalence Class. {w ∈ (a + b)* | #a(w) is odd}
Q4: Consider the following grammar G: (2004)
S → bS | aA |b
A → bA | aB
B → bB | aS |a
Let Na(w) and Nb(w) denote the number of a's and b's in a string w respectively.
The language L(G) ⊆ {a, b}+ generated by G is
(a) {w | Na(w) > 3Nb(w)}
(b) {w | Nb(w) > 3Na(w)}
(c) {w | Na(w) = 3k, k ∈ {0, 1, 2, ...}}
(d) {w | Nb(w) = 3k, k ∈ {0, 1, 2, ...}}
Ans: (c)
Sol:
Here, we have
S → bS
S → baA (S → aA)
S → baaB (A → aB)
S → baaa (B → a)
Therefore, | Na (w) | = 3. Also, if we use A → bA instead of A → aB,
S→ baA
S→ babA
To terminate A, we would have to use A → aB as only B terminates at a (B → a).
S → baA
S→ babA
S→ babaB
S→ father
Thus, here also, | Na (w) | = 3.
So, C is the correct choice.
Please comment below if you find anything wrong in the above post.





