Previous Year Questions: Pipeline Processor | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE) PDF Download

Q1: A non-pipelined instruction execution unit operating at 2 GHz takes an average of 6 cycles to execute an instruction of a program P. The unit is then redesigned to operate on a 5-stage pipeline at 2 GHz. Assume that the ideal throughput of the pipelined unit is 1 instruction per cycle. In the execution of program P, 20% instructions incur an average of 2 cycles stall due to data hazards and 20% instructions incur an average of 3 cycles stall due to control hazards. The speedup (rounded off to one decimal place) obtained by the pipelined design over the non-pipelined design is ________ (2024 SET-2)
(a) 1.2
(b) 6.2
(c) 2.6
(d) 3.1
Ans: (d)
Sol: Non-pipelined Design:
A non-pipelined instruction takes 6 cycles to execute an instruction.
Total cycles taken to execute n instructions = 6n
Pipelined Design:
It is given that, 20% of instructions incur 2 cycles stall and 20% of instructions incur 3 cycles stall.
Total cycles taken to execute n instructions = (n * 1) + (0.2 * n * 2) + (0.2 * n * 3) = 2n
Speedup = 6n/2n = 3 (Answer)
Note:
In pipelined design, 1 cycle is taken by ALL instructions but 20% of them are taking 2 Stall cycles, which means they are taking "extra" 2 cycles & similarly other 20% of them are taking Extra 3 cycles.
2.8 to 3.1 is a correct answer. (Acc to Official Answer key)
Q2: An instruction format has the following structure:
Instruction Number: Opcode destinationreg, sourcereg − 1, sourcereg − 2
Consider the following sequence of instructions to be executed in a pipelined processor:
I1: DIV R3, R1, R2
I2: SUB R5, R3, R4
I3: ADD R3, R5, R6
I4: MUL R7, R3, R8
Which of the following statements is/are TRUE (2024 SET-2)
(a) There is a RAW dependency on R3 between I1 and I2
(b) There is a WAR dependency on R3 between I1 and I3
(c) There is a RAW dependency on R3 between I2 and I3
(d) There is a WAW dependency on R3 between I3 and I4
Ans: (a)
Sol: There is a RAW dependency on R3 between I1 and I2.
There is a RAW dependency on R5 between I2 and I3.
There is NO RAW dependency on R3 between I2 and I3.
There is a WAW dependency on R3 between I1 and I3.
So, answer will be: Only Option A is correct.
Q3: The baseline execution time of a program on a 2 GHz single core machine is 100 nanoseconds (ns). The code corresponding to 90% of the execution time can be fully parallelized. The overhead for using an additional core is 10 ns when running on a multicore system. Assume that all cores in the multicore system run their share of the parallelized code for an equal amount of time.
The number of cores that minimize the execution time of the program is _______ (2024 SET-1)
(a) 1
(b) 2
(c) 3
(d) 4
Ans: (c)
Sol: 2 GHz Machine implies Cycle-Time of 0.5 ns or you can say for every 1 ns, there are 2 cycles
Now, Given Exec Time of 100 ns implies 200 cycles out of which 90% i.e. 180 cycles can be parallelized
Task is to distribute 180 cycles equally in 'x' number of cores (each 2 GHz) such that exec time gets minimized
Now
Take x = 2, which means 20ns(Overhead) + 90 cycles(each core i.e. 180 cycles/2) i.e. 45ns totaling to 65ns
Take x = 3 which means 30ns(Overhead) + 60 cycles(each core i.e. 180 cycles/3) i.e. 30ns totaling to 60ns
Take x = 4 which means 40ns(Overhead) + 45 cycles(each core i.e. 180 cycles/4) i.e. 22.5 ns totaling to 62.5ns
Take x =5 which means 50 ns(Overhead) + 36 cycles(each core i.e. 180 cycles/5) i.e. 18 ns totaling to 65 ns
Clearly, minima can be observed at x = 3 i.e. 60 ns
Q4: Consider a 5-stage pipelined processor with Instruction Fetch (IF), Instruction Decode (ID), Execute (EX), Memory Access (MEM), and Register Writeback (WB) stages. Which of the following statements about forwarding is/are CORRECT? (2024 SET-1)
(a) In a pipelined execution, forwarding means the result from a source stage of an earlier instruction is passed on to the destination stage of a later instruction
(b) In forwarding, data from the output of the MEM stage can be passed on to the input of the EX stage of the next instruction
(c) Forwarding cannot prevent all pipeline stalls
(d) Forwarding does not require any extra hardware to retrieve the data from the pipeline stages
Ans: (a, c)
Sol: Each Option is discussed in THIS lecture on "Forwarding in pipeline".
Option A: False.
Correct statement is: In a pipelined execution, forwarding means the result from a destination stage of an earlier instruction is passed on to the source stage of a later instruction. See HERE.
Option B: False, because of "next instruction".
1. In forwarding, data from the output of the MEM stage can be passed on to the input of the EX stage of the next instruction. FALSE.
2. In forwarding, data from the output of the MEM stage can be passed on to the input of the EX stage of a later instruction. TRUE.
3. In forwarding, data from the output of the MEM stage can be passed on to the input of the EX stage of the next instruction, after a stall. TRUE.
In the graphical representation of events (timing diagram that we draw for execution), forwarding paths are valid only if the destination stage is later in time than the source stage. For example, there cannot be a valid forwarding path from the output of the memory access stage in the first instruction to the input of the execution stage of the following, since that would mean going backward in time (tine travel).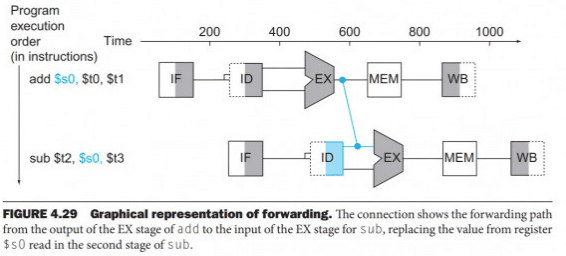
Q5: Consider a 3-stage pipelined processor having a delay of 10 ns (nanoseconds), 20 ns, and 14 ns, for the first, second, and the third stages, respectively. Assume that there is no other delay and the processor does not suffer from any pipeline hazards. Also assume that one instruction is fetched every cycle.
The total execution time for executing 100 instructions on this processor is _______ ns (2023)
(a) 2541
(b) 2040
(c) 1825
(d) 2358
Ans: (b)
Sol: Given,
delays = 10ns, 20ns, 14ns
total instruction (n) = 100
We take pipeline delay as tp = max(10, 20, 14) = 20
number of stages (k) = 3
So,
Total execution time = (k+(n–1)) × tp
⇒ (3+100−1) × 20ns
⇒ 2040ns
Q6: A processor X1 operating at 2 GHz has a standard 5-stage RISC instruction pipeline having a base CPI (cycles per instruction) of one without any pipeline hazards. For a given program P that has 30% branch instructions, control hazards incur 2 cycles stall for every branch. A new version of the processor X2 operating at same clock frequency has an additional branch predictor unit (BPU) that completely eliminates stalls for correctly predicted branches. There is neither any savings nor any additional stalls for wrong predictions. There are no structural hazards and data hazards for X1 and X2. If the BPU has a prediction accuracy of 80%, the speed up (rounded off to two decimal places) obtained by X2 over X1 in executing P is (2022)
(a) 0.72
(b) 1.42
(c) 0.64
(d) 1.64
Ans: (b)
Sol: Execution Time = No.of Instructions x Clocks per Instructions x Clock cylce time When no.of Instructions and clock cycle time are same, then
When no.of Instructions and clock cycle time are same, then 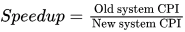 Normal processor CPI = 1, without any pipeline hazards.
Normal processor CPI = 1, without any pipeline hazards.
Given that, Program P has 30% branch instructions where each instruction will lead to 2 stall cycles.
Processor X1 has NO BPU, therefore CPI =  Processor X2 has BPU, therefore CPI =
Processor X2 has BPU, therefore CPI =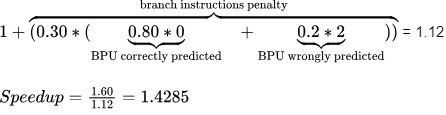
Q7: Consider a pipelined processor with 5 stages, Instruction Fetch(IF), Instruction Decode(ID), Execute (EX), Memory Access (MEM), and Write Back (WB). Each stage of the pipeline, except the EX stage, takes one cycle. Assume that the ID stage merely decodes the instruction and the register read is performed in the EX stage. The EX stage takes one cycle for ADD instruction and the register read is performed in the EX stage, The EX stage takes one cycle for ADD instruction and two cycles for MUL instruction. Ignore pipeline register latencies.
Consider the following sequence of 8 instructions:
ADD, MUL, ADD, MUL, ADD, MUL, ADD, MUL
Assume that every MUL instruction is data-dependent on the ADD instruction just before it and every ADD instruction (except the first ADD) is data-dependent on the MUL instruction just before it. The speedup defined as follows.
Speedup = Execution time without operand forwarding/Execution time with operand forearding
The Speedup achieved in executing the given instruction sequence on the pipelined processor (rounded to 2 decimal places) is ____. (2021 SET-2)
(a) 2.58
(b) 6.37
(c) 1.45
(d) 1.87
Ans: (d)
Sol: 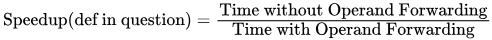 Without Operand Forwarding:
Without Operand Forwarding: Time taken without Operand Forwarding = 30
Time taken without Operand Forwarding = 30
With Operand Forwarding: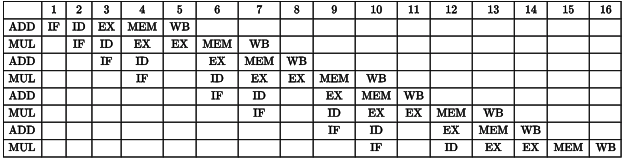 Time taken with Operand Forwarding =16
Time taken with Operand Forwarding =16
Speedup =  = 30/16 = 1.875
= 30/16 = 1.875
Q8: A five-stage pipeline has stage delays of 150, 120, 150, 160 and 140 nanoseconds. The registers that are used between the pipeline stages have a delay of 5 nanoseconds each.
The total time to execute 100 independent instructions on this pipeline, assuming there are no pipeline stalls, is _______ nanoseconds. (2021 SET-1)
(a) 17080
(b) 16335
(c) 17160
(d) 16640
Ans: (c)
Sol: For the given pipelined system:
- Total number of stages (k) = 5
- Total number of instructions, (n) = 100
- Total delay (tp) = max(stage delay)+buffer delay
- ⇒ tp = max(150, 120, 150, 160, 140) + 5ns
- ⇒ tp = 160 + 5ns
- ⇒ tp = 165ns
ETp = [(k + (n−1)) ∗ tp]
⇒ ETp = [(5 + (100−1)) ∗ 165]ns
⇒ ETp = (5 + 99) ∗ 165ns
⇒ ETpipeline = 17160ns
∴ To execute 100 instructions in the given pipeline, 17160ns time is required.
Q9: One instruction tries to write an operand before it is written by previous instruction. This may lead to a dependency called (2020)
(a) True dependency
(b) Anti-dependency
(c) Output dependency
(d) Control Hazard
Ans: (c)
Sol: 1. WAW (Output Dependency)
2. WAR (Anti-Dependency)
3. RAW (Flow or True data Dependency)
Q10: Consider a 5- segment pipeline with a clock cycle time 20 ns in each sub operation. Find out the approximate speed-up ratio between pipelined and non-pipelined system to execute 100 instructions. (if an average, every five cycles, a bubble due to data hazard has to be introduced in the pipeline) (2020)
(a) 5
(b) 4.03
(c) 4.81
(d) 4.17
Ans: (b)
Sol: Twithout pipeline = no. of instructions x stages in pipeline x clock cycle per stage
= 100 x 5 x 20
Tpipeline = (time for pipelined execution without stalls) + (overhead due to stalls)
= (5 + 99) x 20 + 20 x 20 = 124 x 20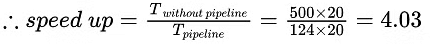 ∴ Option B is correct.
∴ Option B is correct.
Q11: Consider a non-pipelined processor operating at 2.5 GHz. It takes 5 clock cycles to complete an instruction. You are going to make a 5-stage pipeline out of this processor. Overheads associated with pipelining force you to operate the pipelined processor at 2 GHz. In a given program, assume that 30% are memory instructions, 60% are ALU instructions and the rest are branch instructions. 5% of the memory instructions cause stalls of 50 clock cycles each due to cache misses and 50% of the branch instructions cause stalls of 2 cycles each. Assume that there are no stalls associated with the execution of ALU instructions. For this program, the speedup achieved by the pipelined processor over the non-pipelined processor (round off to 2 decimal places) is________. (2020)
(a) 1.25
(b) 2.16
(c) 1.85
(d) 2.82
Ans: (b)
Sol: Time taken by non-pipelined processor to finish executing the n instructions : 5n/2.5 = 2n ns
Now, for pipelined processor, Therefore, time taken by pipelined processor:
Therefore, time taken by pipelined processor:
0.6n(1) + 0.3n[0.05(1+50) + 0.95(1)] + 0.1n[0.5(1 + 2) + 0.5(1)] cycles
= 1.85n cycles
= 1.85n/2 ns
= 0.925n ns
Speedup = 2n/0.925n = 2.162 ≈ 2.16.
Q12: A particular parallel program computation requires 100 sec when executed on a single processor, if 40% of this computation is inherently sequential (i.e. will not benefit from additional processors), then theoretically best possible elapsed times of this program running with 2 and 4 processors, respectively, are: (2018)
(a) 20 sec and 10 sec
(b) 30 sec and 15 sec
(c) 50 sec and 25 sec
(d) 70 sec and 55 sec
Ans: (d)
Sol: 40% sequential means 40 seconds.
Rest 60 % will be divided into 30 -30 % each parallely by the two processors hence total 40+30 = 70 sec
If four processors then 15% each, hence total 40+15 = 55 sec
Q13: The instruction pipeline of a RISC processor has the following stages: Instruction Fetch (IF), Instruction Decode (ID), Operand Fetch (OF), Perform Operation (PO) and Writeback (WB). The IF, ID, OF and WB stages take 1 clock cycle each for every instruction. Consider a sequence of 100 instructions. In the PO stage, 40 instructions take 3 clock cycles each, 35 instructions take 2 clock cycles each, and the remaining 25 instructions take 1 clock cycle each. Assume that there are no data hazards and no control hazards.
The number of clock cycles required for completion of execution of the sequence of instructions is ______. (2018)
(a) 200
(b) 315
(c) 219
(d) 375
Ans: (c)
Sol: Total Instruction = 100
Number of stages = 5
In normal case total cycles = 100 + 5 − 1 = 104 cycles
Now, For PO stage 40 instructions take 3 cycles, 35 take 2 cycles and rest of the 25 take 1 cycle.
That means all other stages are perfectly fine and working with CPI (Clock Cycle Per Instruction) = 1
PO stage:
40 instructions take 3 cycles i.e. these instructions are suffering from 2 stall cycle,
35 instructions take 2 cycles i.e. these instructions are suffering from 1 stall cycle,
25 instructions take 1 cycles i.e. these instructions are suffering from 0 stall cycle,
So, extra cycle would be 40 ∗ 2 + 35 ∗ 1 + 25 ∗ 0 = 80 + 35 = 115 cycle.
Total cycles = 104 + 115 = 219.
Q14: Instructions execution in a processor is divided into 5 stages. Instruction Fetch (IF), Instruction Decode (ID) , Operand Fetch (OF), Execute (EX), and Write Back (WB), These stages take 5,4,20, 10 and 3 nanoseconds (ns) respectively. A pipelined implementation of the processor requires buffering between each pair of consecutive stages with a delay of 2ns.
Two pipelined implementations of the processor are contemplated.
(i) a naive pipeline implementation (NP) with 5 stages and
(ii) an efficient pipeline (EP) where the OF stage id divided into stages OF1 and OF2 with execution times of 12 ns and 8 ns respectively.
The speedup (correct to two decimals places) achieved by EP over NP in executing 20 independent instructions with no hazards is ______. (2017 SET-1)
(a) 2.5
(b) 1.508
(c) 1.212
(d) 2.016
Ans: (b)
Sol: Case 1:
Stages 5, max delay = 22 (after adding buffer delay), number of instructions = 20
Case 2:
Stages 6, (since OF is split), max delay
=14, number of instructions = 20
So, execution time is (K+N−1)× Max delay
Speed Up = 528/350 = 1.508(Execution time case 1/Execution time case 2)
So, the answer is 1.508
Q15: Register renaming is done in pipelined processors: (2016)
(a) as an alternative to register allocation at compile time
(b) for efficient access to function parameters and local variables
(c) to handle certain kinds of hazards
(d) as part of address translation
Ans: (c)
Sol: Register renaming is done to eliminate WAR (Write after Read) and WAW (Write after Write) dependency between instructions which could have caused pipieline stalls. Hence, (C) is the answer.
Example: I1: Read A to B
I2: Write C to A
Here, there is a WAR dependency and pipeline would need stalls. In order to avoid it register renaming is done and Write C to A will be Write C to A'
WAR dependency is actually called anti-dependency and there is no real dependency except the fact that both uses same memory location. Register renaming can avoid this. Similarly WAW also.
Q16: Consider a non-pipelined processor with a clock rate of 2.5 gigahertz and average cycles per instruction of four. The same processor is upgraded to a pipelined processor with five stages; but due to the internal pipeline delay, the clock speed is reduced to 2 gigahertz. Assume that there are no stalls in the pipeline. The speedup achieved in this pipelined processor is (2016)
(a) 3.2
(b) 3.0
(c) 2.2
(d) 2.0
Ans: (a)
Sol: Option A is Correct
Speed up = Time without pipeline / Time with pipeline
Time without pipeline= 4 clock cycle
1 clock cyle = 1 / (2.5 *109)
Time with pipeline = 1 clock cycle in ideal case
1 clock cycle= 1/ (2 * 109)
so, speed up= (4 * 1 / (2.5 *109)) / 1/ (2 * 109)
CORRECT ANS is 3.2
Q17: The dynamic hazard problem occurs in (2016)
(a) combinational circuit alone
(b) sequential circuit only
(c) Both (A) and (B)
(d) None of the above
Ans: (c)
Sol: Definition: for a single input output changes more than once.
Reason: For larger circuits there may be different routes to output. if each route has different delay, output may change more than once.
In combinational circuits, delays in logic gates (eg: NAND, NOR) may cause this hazard
In sequential circuits, delays by flipflops may cause this hazard
Hence answer is c.
Q18: Consider a 3GHz (gigahertz) processor with a three-stage pipeline and stage latencies τ1, τ2, and τ3 such that τ1 = 3τ2/4 = 2τ3. If the longest pipeline stage is split into two pipeline stages of equal latency, the new frequency is _____GHz, ignoring delays in the pipeline registers. (2016 SET-2)
(a) 2
(b) 3
(c) 4
(d) 5
Ans: (c)
Sol: Given 3 stage pipeline , with 3 GHz processor.
Given, 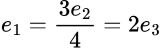 Put e1 = 6x
Put e1 = 6x
we get, e2 = 8x, e3 = 3x
Now largest stage time is 8x.
So, frequency is 1/8x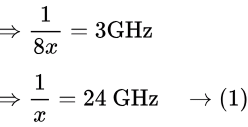
Now, we divide e2 into two stages of 4x & 4x.
New processor has 4 stages
-6x, 4x, 4x, 3x.
Now largest stage time is 6x.
So, new frequency is 1/6x = 24/6 = 4 GHz (Ans) [∵ from(1)]
Q19: Suppose the functions F and G can be computed in 5 and 3 nano seconds by functional units UF and UG, respectively. Given two instances of UF and two instances of UG, it is required to implement the computation F(G(Xi)) for 1 ≤ i ≤ 10. Ignoring all other delays, the minimum time required to complete this computation is ________ nanoseconds. (2016 SET-2)
(a) 40
(b) 28
(c) 20
(d) 23
Ans: (b)
Sol: The same concept is used in pipelining. Bottleneck here is UF as it takes 5ns while UG takes 3ns only. We have to do 10 such calculations and we have 2 instances of UF and UG respectively. So, UF can be done in 50/2 = 25 nano seconds. For the start UF needs to wait for UG output for 3ns and rest all are pipelined and hence no more waiting is needed. So, answer is 3 + 25 = 28 ns.
Q20: The stage delays in a 4-stage pipeline are 800,500,400 and 300 picoseconds.The first stage (with delay 800 picoseconds)is replaced with a functionally equivalent design involving two stages with respective delays 600 and 350 picoseconds.The throughput increase of the pipeline is ________ percent. (2016 SET-1)
(a) 10
(b) 25
(c) 33
(d) 42
Ans: (c)
Sol: In pipeline ideally CPI = 1
So in 1 cycle 1 instruction gets completed
Throughput is instructions in unit time
In pipeline 1, cycle time = max stage delay = 800 psec
In 800 psec, we expect to finish 1 instruction
So, in 1ps, (1/800) instructions are expected to be completed, which is also the throughput for pipeline 1.
Similarly pipeline 2, throughput = 1/600
Throughput increase in percentage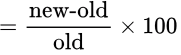
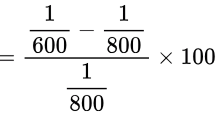 = (200/600) x 100
= (200/600) x 100
= 33.33%
Q21: Consider the following code sequence having five instructions I1 to I5. Each of these instructions has the following format.
OP Ri, Rj, Rk
where operation OP is performed on contents of registers Rj and Rk and the result is stored in register Ri.
I1: ADD R1, R2, R3
I2: MUL R7, R1, R3
I3: SUB R4, R1, R5
I4: ADD R3, R2, R4
I5: MUL R7, R8, R9
Consider the following three statements.
S1: There is an anti-dependence between instructions l2 and l5
S2: There is an anti-dependence between instructions l2 and l4
S3: Within an instruction pipeline an anti-dependence always creates one or more stalls
Which one of above statements is/are correct? (2015 SET-3)
(a) Only S1 is true
(b) Only S2 is true
(c) Only S1 and S3 are true
(d) Only S2 and S3 are true
Ans: (b)
Sol: Anti-dependence can be overcome in pipeline using register renaming. So, "always" in S3 makes it false. Also, if I2 is completed before I4 (execution stage of MUL), then also there won't be any stall.
Q22: Consider the following reservation table for a pipeline having three stages S1, S2 and S3.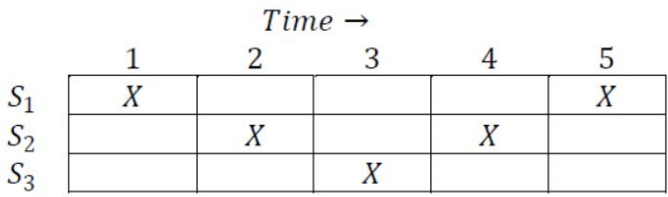 The minimum average latency (MAL) is ________. (2015 SET-3)
The minimum average latency (MAL) is ________. (2015 SET-3)
(a) 2
(b) 3
(c) 4
(d) 5
Ans: (b)
Sol: S1 is needed at time 1 and 5, so its forbidden latency is 5−1 = 4.
S2 is needed at time 2 and 4, so its forbidden latency is 4−2 = 2.
So, forbidden latency =(2, 4, 0) ( 0 by default is forbidden)
Allowed latency = (1, 3, 5) (any value more than 5 also).
Collision vector (4, 3, 2, 1, 0) = 10101 which is the initial state as well.
From initial state we can have a transition after “1" or “3" cycles and we reach new states with collision vectors
(10101>>1+10101 = 11111) and (10101>>3+10101 = 10111) respectively.
These 2 becomes states 2 and 3 respectively. For “5" cycles we come back to state 1 itself.
From state 2 (11111), the new collision vector is 11111. We can have a transition only when we see the first 0 from the right. So, here it happens on 5th cycle only which goes to the initial state. (Any transition after 5 or more cycles goes to initial state as we have 5 time slices).
From state 3 (10111), the new collision vector is 10111. So, we can have a transition on 3, which will give (10111>>3+10101=10111) third state itself. For 5, we get the initial state. Thus all the transitions are complete.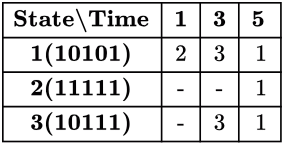
So, minimum length cycle is of length 3 either from 3-3 or from 1-3, 3-1.
Not asked in the question, still.
Pipeline throughput is the number of instructions initiated per unit time.
So, with MAL = 3, we have 2 initiations in 1 + 3 = 4 units of time (one at time unit 1 and another at time unit 4 ). So, throughput = 2/4 = 0.5.
Pipeline efficiency is the % of time every stage of the pipeline is being used.
For the given question we can extend the reservation table and taking MAL = 3, we can initiate new tasks after every 3 cycles. So, we can consider the time interval from 4 - 6 in the below figure. (The red color shows a stage not being used- affects efficiency).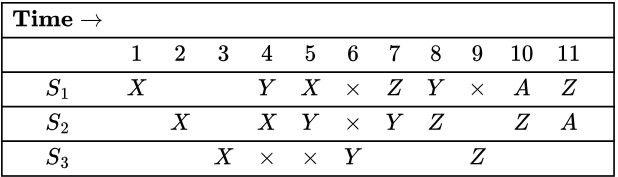 Here (during cycles 4−6 ), stage 1 is used 2/3, stage 2 is used 2/3 and stage 3 is used 1/3.
Here (during cycles 4−6 ), stage 1 is used 2/3, stage 2 is used 2/3 and stage 3 is used 1/3.
So, total stage utilization 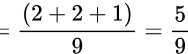 and efficiency = 500/9% = 55.55.
and efficiency = 500/9% = 55.55.
Q23: Consider the sequence of machine instructions given below:
MUL R5, R0, R1
DIV R6, R2, R3
ADD R7, R5, R6
SUB R8, R7, R4
In the above sequence, R0 to R8 are general purpose registers. In the instructions shown, the first register stores the result of the operation performed on the second and the third registers. This sequence of instructions is to be executed in a pipelined instruction processor with the following 4 stages: (1) Instruction Fetch and Decode (IF), (2) Operand Fetch (OF), (3) Perform Operation (PO) and (4) Write back the result (WB). The IF, OF and WB stages take 1 clock cycle each for any instruction. The PO stage takes 1 clock cycle for ADD or SUB instruction, 3 clock cycles for MUL instruction and 5 clock cycles for DIV instruction. The pipelined processor uses operand forwarding from the PO stage to the OF stage.
The number of clock cycles taken for the execution of the above sequence of instructions is ___________. (2015 SET-2)
(a) 11
(b) 13
(c) 15
(d) 16
Ans: (b)
Sol: 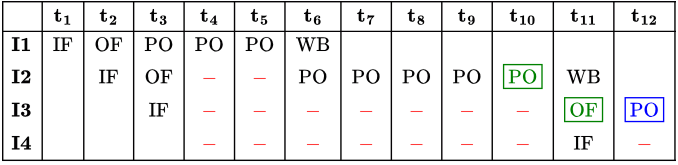 It is mentioned in the question that operand forwarding takes place from PO stage to OF stage and not to PO stage. So, 15 clock cycles.
It is mentioned in the question that operand forwarding takes place from PO stage to OF stage and not to PO stage. So, 15 clock cycles.
But since operand forwarding is from PO-OF, we can do like make the PO stage produce the output during the rising edge of the clock and OF stage fetch the output during the falling edge. This would mean the final PO stage and OF stage can be done in one clock cycle making the total number of cycles = 13. And 13 is the answer given in GATE key.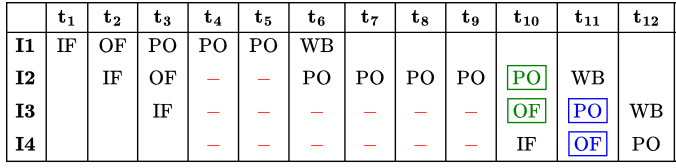
Q24: Consider a non-pipelined processor with a clock rate of 2.5 gigahertz and average cycles per instruction of four. The same processor is upgraded to a pipelined processor with five stages; but due to the internal pipeline delay, the clock speed is reduced to 2 gigahertz. Assume that there are no stalls in the pipeline. The speed up achieved in this pipelined processor is_________. (2015 SET-1)
(a) 2.2
(b) 1.5
(c) 3.2
(d) 2.8
Ans: (c)
Sol: To compute cycle time, we know that a 2.5GHz processor means it completes 2.5billion cycles in a second. So, for an instruction which on an average takes 4 cycles to get completed, it will take 4/2.5 nanoseconds.
On a perfect pipleline (i.e., one which has no stalls) CPI = 1 as during it an instruction takes just one cycle time to get completed.
So,
Speed Up 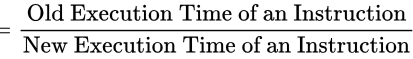
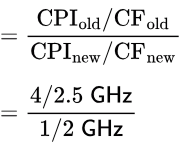 = 3.2
= 3.2
Q25: An instruction pipeline has five stages, namely, instruction fetch (IF), instruction decode and register fetch (ID/RF), instruction execution (Ex), memory access (MEM), and register write back (WB) with stage latencies 1 ns, 2.2 ns, 2 ns, 1 ns, and 0.75 ns, respectively (ns stands for nanoseconds). To gain in terms of frequency, the designers have decided to split the ID/RF stage into three stages (ID, RF1, RF2) each of latency 2.2/3 ns. Also, the Ex stage is split into two stages (Ex1, Ex2) each of latency 1 ns. The new design has a total of eight pipeline stages. A program has 20% branch instructions which execute in the Ex stage and produce the next instruction pointer at the end of the Ex stage in the old design and at the end of the Ex2 stage in the new design. The IF stage stalls after fetching a branch instruction until the next instruction pointer is computed. All instructions other than the branch instruction have an average CPI of one in both the designs. The execution times of this program on the old and the new design are P and Q nanoseconds, respectively. The value of P/Q is __________ (2014 SET-3)
(a) 1.5
(b) 2
(c) 1
(d) 1.75
Ans: (a)
Sol: Five stages:
(IF), instruction decode and register fetch (ID/RF), instruction execution (EX), memory access (MEM), and register writeback (WB)
P old design:
with stage latencies 1 ns, 2.2 ns, 2 ns, 1 ns, and 0.75 ns
MAX( 1 ns, 2.2 ns, 2 ns, 1 ns, and 0.75 ns) = 2.2nsec
AVG instruction execution time is
Tavg = (1 + no of stalls × branch penality) × cycle time
=(1 + 0.20 × 2)2.2 { branch peanlity is 2 because the next instruction pointer at the end of the EX stage in the old design.}
= 3.08 nsec
Q :new DESIGN: the designers decided to split the ID/RF stage into three stages (ID, RF1, RF2) each of latency 2.2/3 ns. Also, the EX stage is split into two stages (EX1, EX2) each of latency 1 ns.
The new design has a total of eight pipeline stages. Time of stages in new design = {1 ns, 0.73ns, 0.73ns, 0.73ns , 1ns,1ns, 1 ns, and 0.75 ns}(IF), instruction decoderegister fetch (ID/RF) → further divided into 3 ie with latency 0.73 of each instruction execution (EX) → further divided int 1 nsec of each)memory access (MEM) register writeback (WB) MAX( 1 ns, 0.73ns, 0.73ns, 0.73ns , 1ns,1ns, 1 ns, and 0.75 ns) = 1 nsecAVG instruction execution time is Tavg = (1+no of stalls×branch penality) × cycle time = (1 + 0.20 × 5)1 { branch penalty is 5 because the next instruction pointer at the end of the EX2 stage in the new design.}
= 2nsec
final result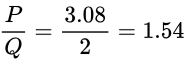
Q26: Consider the following processors (ns stands for nanoseconds). Assume that the pipeline registers have zero latency.
P1: Four-stage pipeline with stage latencies 1 ns, 2 ns, 2 ns, 1 ns.
P2: Four-stage pipeline with stage latencies 1 ns, 1.5 ns, 1.5 ns, 1.5 ns.
P3: Five-stage pipeline with stage latencies 0.5 ns, 1 ns, 1 ns, 0.6 ns, 1 ns.
P4: Five-stage pipeline with stage latencies 0.5 ns, 0.5 ns, 1 ns, 1 ns, 1.1 ns.
Which processor has the highest peak clock frequency? (2014 SET-3)
(a) P1
(b) P2
(c) P3
(d) P4
Ans: (c)
Sol: frequency 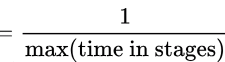 for P3, it is 1/1 = 1 GHz
for P3, it is 1/1 = 1 GHz
for P1, it is 1/2 = 0.5 GHz
for P2, it is 1/1.5 = 0.67 GHz
for P4, it is 1/1.1 = 0.90 GHz
Correct Answer: C
Q27: Consider a 6-stage instruction pipeline, where all stages are perfectly balanced. Assume that there is no cycle-time overhead of pipelining. When an application is executing on this 6-stage pipeline, the speedup achieved with respect to non-pipelined execution if 25% of the instructions incur 2 pipeline stall cycles is _________. (2014 SET-1)
(a) 2
(b) 3
(c) 4
(d) 5
Ans: (c)
Sol: Time without pipeline = 6 stages = 6 cycles
Time with pipeline = 1 + stall freqency × stall cycle
= 1 + .25 × 2
= 1.5
Speed up = 6/1.5 = 4
Q28: A pipeline P operating at 400 MHz has a speedup factor of 6 and operating at 70% efficiency. How many stages are there in the pipeline? (2013)
(a) 5
(b) 6
(c) 8
(d) 9
Ans: (d)
Sol: Efficiency of K stage Pipeline = SpeedUp Factor (Sk) / Number of Stages (K)
0.70 = 6/K
K = 6/0.70 = 8.57 ≌ 9
Number of Stages = 9
Q29: Consider an instruction pipeline with five stages without any branch prediction: Fetch Instruction (FI), Decode Instruction (DI), Fetch Operand (FO), Execute Instruction (EI) and Write Operand (WO). The stage delays for FI, DI, FO, EI and WO are 5 ns, 7 ns, 10 ns, 8 ns and 6 ns, respectively. There are intermediate storage buffers after each stage and the delay of each buffer is 1 ns. A program consisting of 12 instructions I1, I2, I3,..., I12 is executed in this pipelined processor. Instruction I4 is the only branch instruction and its branch target is I9. If the branch is taken during the execution of this program, the time (in ns) needed to complete the program is (2013)
(a) 132
(b) 165
(c) 176
(d) 328
Ans: (b)
Sol: After pipelining we have to adjust the stage delays such that no stage will be waiting for another to ensure smooth pipelining (continuous flow). Since we can not easily decrease the stage delay, we can increase all the stage delays to the maximum delay possible. So, here maximum delay is 10 ns. Buffer delay given is 1 ns. So, each stage takes 11 ns in total.
FI of I9 can start only after the EI of I4. So, the total execution time will be 15 x 11 = 165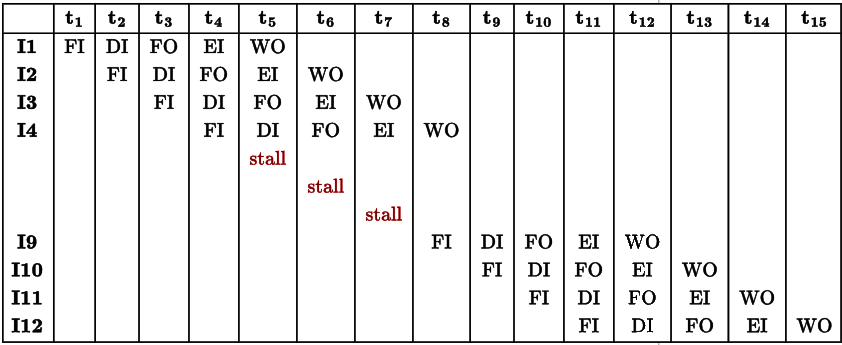 Correct Answer: B
Correct Answer: B
Q30: Register renaming is done in pipelined processors (2012)
(a) as an alternative to register allocation at compile time
(b) for efficient access to function parameters and local variables
(c) to handle certain kinds of hazards
(d) as part of address translation
Ans: (c)
Sol: Register renaming is done to eliminate WAR (Write after Read) and WAW (Write after Write) dependency between instructions which could have caused pipieline stalls. Hence, (C) is the answer.
Example:
I1: Read A to B
I2: Write C to A
Here, there is a WAR dependency and pipeline would need stalls. In order to avoid it register renaming is done and
Write C to A
will be
Write C to A'
WAR dependency is actually called anti-dependency and there is no real dependency except the fact that both uses same memory location. Register renaming can avoid this. Similarly WAW also.
Q31: If a microcomputer operates at 5 MHz with an 8-bit bus and a newer version operates at 20 MHz with a 32-bit bus, the maximum speed-up possible approximately will be (2011)
(a) 2
(b) 4
(c) 8
(d) 16
Ans: (b)
Sol: It should be max(20/5, 32/8) = 4. Increasing the bandwidth aids in achieving the maximum speed up. Suppose we had a memory intensive program then increase in bandwidth becomes critical whereas for a CPU intensive process, increase in clock speed becomes critical.
Q32: A processor takes 12 cycles to complete an instruction I. The corresponding pipelined processor uses 6 stages with the execution times of 3,2,5,4,6 and 2 cycles respectively. What is the asymptotic speedup assuming that a very large number of instructions are to be executed? (2011)
(a) 1.83
(b) 2
(c) 3
(d) 6
Ans: (b)
Sol: For non pipeline processor we have n instruction and each instruction take
12 cycle so total 12n instruction.
For pipeline processor we have each stage strict to 6ns so time to complete
the n instruction is 6 × 6 + (n−1) × 6.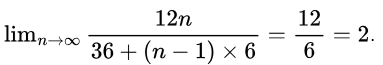 Correct Answer: B.
Correct Answer: B.
Q33: Consider an instruction pipeline with four stages (S1, S2, S3 and S4) each with combinational circuit only. The pipeline registers are required between each stage and at the end of the last stage. Delays for the stages and for the pipeline registers are as given in the figure.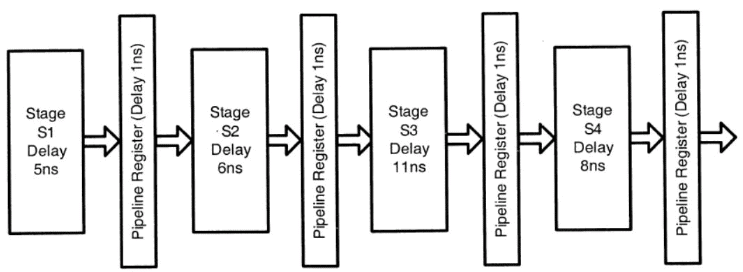 What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation? (2011)
What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation? (2011)
(a) 4
(b) 2.5
(c) 1.1
(d) 3
Ans: (b)
Sol: In pipeline system, Time taken is determined by the max delay at any stage i.e., 11 ns plus the delay incurred by pipeline stages i.e., 1 ns = 12 ns. In non-pipeline system,
Delay = 5 ns + 6 ns + 11 ns + 8 ns = 30 ns.
∴ The speedup is 30/12 = 2.5 ns.
Q34: A 5-stage pipelined processor has Instruction Fetch (IF), Instruction Decode (ID), Operand Fetch (OF), Perform Operation (PO) and Write Operand (WO) stages. The IF, ID, OF and WO stages take 1 clock cycle each for any instruction. The PO stage takes 1 clock cycle for ADD and SUB instructions, 3 clock cycles for MUL instruction, and 6 clock cycles for DIV instruction respectively. Operand forwarding is used in the pipeline. What is the number of clock cycles needed to execute the following sequence of instructions? (2010)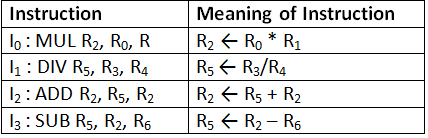 (a) 13
(a) 13
(b) 15
(c) 17
(d) 19
Ans: (a)
Sol:  Operand forwarding allows an output to be passed for the next instruction. Here from the output of PO stage of DIV instruction operand is forwarded to the PO stage of ADD instruction and similarly between ADD and SUB instructions. Hence, 15 cycles required.
Operand forwarding allows an output to be passed for the next instruction. Here from the output of PO stage of DIV instruction operand is forwarded to the PO stage of ADD instruction and similarly between ADD and SUB instructions. Hence, 15 cycles required.
|
20 videos|113 docs|48 tests
|
FAQs on Previous Year Questions: Pipeline Processor - Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
| 1. What is a pipeline processor in computer science? |  |
| 2. How does a pipeline processor improve performance in computers? | |
| 3. What are the stages involved in the pipeline processor? | |
| 4. What are the potential hazards in a pipeline processor design? | |
| 5. How does the concept of pipelining relate to the performance of modern computer systems? | |


|
20 videos|113 docs|48 tests
|

|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
ppt
,Previous Year Questions: Pipeline Processor | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,Important questions
,Extra Questions
,video lectures
,Summary
,Previous Year Questions with Solutions
,study material
,mock tests for examination
,past year papers
,Viva Questions
,shortcuts and tricks
,Semester Notes
,practice quizzes
,Objective type Questions
,Previous Year Questions: Pipeline Processor | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,Previous Year Questions: Pipeline Processor | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,Exam
,Free
,MCQs
,Sample Paper
;


Previous Year Questions: Pipeline Processor Free PDF Download
Importance of Previous Year Questions: Pipeline Processor
Previous Year Questions: Pipeline Processor Notes
Previous Year Questions: Pipeline Processor Computer Science Engineering (CSE)
Study Previous Year Questions: Pipeline Processor on the App
|
© EduRev
|
Education Revolution
|



|





