Previous Year Questions: File System | Database Management System (DBMS) - Computer Science Engineering (CSE) PDF Download

Q1: Which of the following file organizations is/are I/O efficient for the scan operation in DBMS? (2024 SET 2
(a) Sorted
(b) Heap
(c) Unclustered tree index
(d) Unclustered hash index
Ans: (a, b)
Sol: The file organizations that are I/O Efficient for the Scan Operation in DBMS are:
A. Sorted and B. Heap
Hence, the correct answer is A and B.
Q2: Consider a database of fixed-length records, stored as an ordered file. The database has 25,000 records, with each record being 100 bytes, of which the primary key occupies 15 bytes. The data file is block-aligned in that each data record is fully contained within a block. The database is indexed by a primary index file, which is also stored as a block-aligned ordered file. The figure below depicts this indexing scheme. (2023)
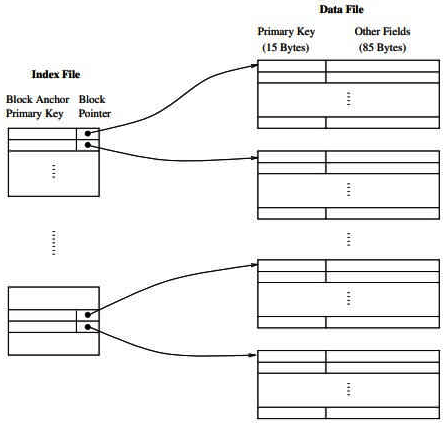
Suppose the block size of the file system is 1024 bytes, and a pointer to a block occupies 5 bytes. The system uses binary search on the index file to search for a record with a given key. You may assume that a binary search on an index file of b blocks takes [log2 b] block accesses in the worst case.
Given a key, the number of block accesses required to identify the block in the data file that may contain a record with the key, in the worst case, is _____
(a) 4
(b) 6
(c) 8
(d) 16
Ans: (b)
Sol: Given that One block should fully contain within block so here it means that they are saying that you should use unspanned file organization.
Given that ,
No. of Record (Rn) = 25000
RecordSize (Rs) = 100Byte
KeySize (Ks) 15 Byte
Block Pointer Size (Ps) = 5Byte
So that Index Size (Is)15+5 = 20Byte
Disk Block Size(Bs) 1024Byte
No. of Record per Block = (Bs/Rs) = [1024B/100B]
= [10.24]
= 10.
No of Block Required for blocks = ceilvalue ( no of record / no of record per block)
[25000 / 10]
= 2500 Block Required to store all records
“The database is indexed by a primary index file” it means that here we have to use sparse indexing
Given That Binary Search is used to search the desired block and we know that it takes
the number of block accesses required to identify the block in the data file that may contain a record with the key, in the worst case, is.
NO of Index per Block = ⌊ ( B s / I s ) ⌋ = floorValue( 1024 / 20 ) = 51
NO of Block Required for indexes = CeilValue( N o . O f I n d e x /No. Of Index Per Block )
= CeilValue( 2500 / 51 ) = 50 Blocks
Given That Binary Search is used to search the desired block and we know that it takes l o g ( n ) Time to search in worst case where n= no of comparision Required = No. of Index Block here.
the number of block accesses required to identify the block in the data file that may contain a record with the key, in the worst case, is.
= l o g ( 50 ) =6Block
Q3: A data file consisting of 1,50,000 student-records is stored on a hard disk with block size of 4096 bytes. The data file is sorted on the primary key RollNo. The size of a record pointer for this disk is 7 bytes. Each student-record has a candidate key attribute called ANum of size 12 bytes. Suppose an index file with records consisting of two fields, ANum value and the record pointer the corresponding student record, is built and stored on the same disk. Assume that the records of data file and index file are not split across disk blocks. The number of blocks in the index file is ______ (2021 SET 2)
(a) 235
(b) 248
(c) 488
(d) 698
Ans: (d)
Sol: Index is being built on attribute “ANum” which is Candidate Key, but Given that file is Sorted on Primary Key “Roll No”.
This indicates that The Index must a Secondary Index, (data records not being physically ordered as per the index making a dense record necessary) so “THERE SHOULD EXIST AN INDEX RECORD FOR EVERY RECORD of Original ‘Student Table’ ”.
=> Also this Line: “Assume that Records of data file and index file are not split across disc blocks”.
This indicates UNSPANNED STRATEGY.
With This Knowledge, let’s see the Data given.
→ Record Size in Index = 12 + 7 = 19 B (‘ANum’ key size + Record pointer Size), and Block Size = 4096 B
→ So number of Index records in 1 Block = [4096 / 19] = 215 records in 1 block (Remember again, unspanned strategy).
→ So number of blocks in the Index file = Total Number Of Records / Records per block = [ 1, 50, 000 / 215 ] = 698 .
(Recall that this is Secondary Index)
Q4: Consider a linear list based directory implementation in a file system. Each directory is a list of nodes, where each node contains the file name along with the file metadata, such as the list of pointers to the data blocks. Consider a given directory foo. (2021 SET 1)
Which of the following operations will necessarily require a full scan of foo for successful completion?
[MSQ]
(a) Creation of a new file in foo
(b) Deletion of an existing file from foo
(c) Renaming of an existing file in foo
(d) Opening of an existing file in foo
Ans: (a, c)
Sol: Each File in Directory is uniquely referenced by its name. So different files must have different names!
So,
A. Creation of a New File: For creating new file, we’ve to check whether the new name is same as the existing files. Hence, the linked list must be scanned in its entirety.
B. Deletion of an Existing File: Deletion of a file doesn’t give rise to name conflicts, hence if the node representing the files is found earlier, it can be deleted without a through scan.
C. Renaming a File: Can give rise to name conflicts, same reason can be given as option A.
D. Opening of existing file: same reason as option B.
Q5: Consider a database implemented using B+ tree for file indexing and installed on a disk drive with block size of 4 KB. The size of search key is 12 bytes and the size of tree/disk pointer is 8 bytes. Assume that the database has one million records. Also assume that no node of the B+ tree and no records are present initially in main memory. Consider that each record fits into one disk block. The minimum number of disk accesses required to retrieve any record in the database is _______ (2020)
(a) 2
(b) 3
(c) 4
(d) 5
Ans: (c)
Sol: Given,
- Search Key: 12 bytes
- Tree Pointer: 8 bytes
- Block Size: 4096 bytes
- Number of database records:10 6
Since it's a B+ tree, an internal node only has search key values and tree pointers. Let p be the order of an internal node. Hence,
p(8) + (p - 1)(12) ≤ 4096
which gives p ≤ 205.4.
Therefore p = 205
Now. Level 3 alone has approximately 8.5 × 10 6 entries. So we can be sure that a 3 -level B + tree is sufficient to index 10 6 records.
Level 3 alone has approximately 8.5 × 10 6 entries. So we can be sure that a 3 -level B + tree is sufficient to index 10 6 records.
So to access any record (in the worst case), we need 3 block access to search for the record in the index along with 1 more access to actually access the record.
Hence, 4 accesses are required.
Q6: Which one of the following statements is NOT correct about the B +tree data structure used for creating an index of a relational database table? (2019)
(a) B + Tree is a height-balanced tree
(b) Non-leaf nodes have pointers to data records
(c)Key values in each node are kept in sorted order
(d) Each leaf node has a pointer to the next leaf node
Ans: (b)
Sol: Properties of B+ trees:
1. B+ tree is height balance tree.
2. Key value is in sorted order.
3. Leaf node has pointer to next leaf node.
4. Non leaf node has pointer to a node (leaf or non leaf) and not pointer to data record.
Q7: In a B +tree, if the search -key value is 8 bytes long, the block size is 512 bytes and the block pointer size is 2 bytes, then maximum order of the B + tree is _______________. (2017 SET 2)
(a) 64
(b) 32
(c) 52
(d) 12
Ans: (c)
Sol: Let order of B + tree is p then maximum number of child pointers = p and maximum number of keys = p − 1 .
To accommodate all child pointers and search key, total size of these together can not exceed 512 bytes .
2(p) + 8(p-1) ≤ 512
⇒p ≤ 52
Therefore, maximum order must be 52.
Q8: Consider a B+ tree in which the search key is 12 bytes long, block size is 1024 bytes, record pointer is 10 bytes long and block pointer is 8 bytes long. The maximum number of keys that can be accommodated in each non-leaf node of the tree is ____________. (2015 SET 3)
(a) 50
(b) 56
(c) 46
(d) 40
Ans: (a)
Sol: In a B+ tree of order n , for a non-leaf node we can have up to ( n − 1 ) keys and n child pointers (pointing to child blocks).
∴ (n - 1)12 + n x 8 ≤ 1024
⇒n ≤ 51
Number of keys = n - 1
= 51 -1 = 50
Q9: A file is organized so that the ordering of data records is the same as or close to the ordering of data entries in some index. Then that index is called (2015 SET 1)
(a) Dense
(b) Sparse
(c) Clustered
(d) Unclustered
Ans: (c)
Sol: The correct answer is option 3
The clustered index is as same as a dictionary where the data is arranged by alphabetical order. In a clustered index, the index contains a pointer to block but not direct data.
A file is organized so that the ordering of data records is the same as, or close to the ordering of data entries in some indexes. Such an index is commonly known as the clustered index.
Hence the correct answer is clustered.
Q10: An index is clustered, if (2013)
(a) it is on a set of fields that form a candidate key.
(b) it is on a set of fields that include the primary key
(c) the data records of the file are organized in the same order as the data entries of the index.
(d) the data records of the file are organized not in the same order as the data entries of the index.
Ans: (c)
Sol: Index can be created using any column or combination of column which need not be unique. So, A, B are not the answers.
Indexed column is used to sort rows of table. Whole data record of file is sorted using index so, C is correct option. (Simple video explains this).
|
62 videos|92 docs|35 tests
|
FAQs on Previous Year Questions: File System - Database Management System (DBMS) - Computer Science Engineering (CSE)
| 1. What is a file system in computer science? |  |
| 2. What are the different types of file systems? | |
| 3. How does a file system ensure data integrity? | |
| 4. Can different operating systems use the same file system? | |
| 5. What is fragmentation in a file system? | |


Top Courses for Computer Science Engineering (CSE)
Summary
,Viva Questions
,video lectures
,Previous Year Questions: File System | Database Management System (DBMS) - Computer Science Engineering (CSE)
,Previous Year Questions with Solutions
,study material
,Sample Paper
,Important questions
,Exam
,Semester Notes
,Extra Questions
,Free
,ppt
,mock tests for examination
,practice quizzes
,MCQs
,Objective type Questions
,shortcuts and tricks
,past year papers
,Previous Year Questions: File System | Database Management System (DBMS) - Computer Science Engineering (CSE)
,Previous Year Questions: File System | Database Management System (DBMS) - Computer Science Engineering (CSE)
;


Previous Year Questions: File System Free PDF Download
Importance of Previous Year Questions: File System
Previous Year Questions: File System Notes
Previous Year Questions: File System Computer Science Engineering (CSE)
Study Previous Year Questions: File System on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!