Computer Science Engineering (CSE) Exam > Computer Science Engineering (CSE) Notes > Compiler Design > Mind Map: Lexical Analysis
Mind Map: Lexical Analysis

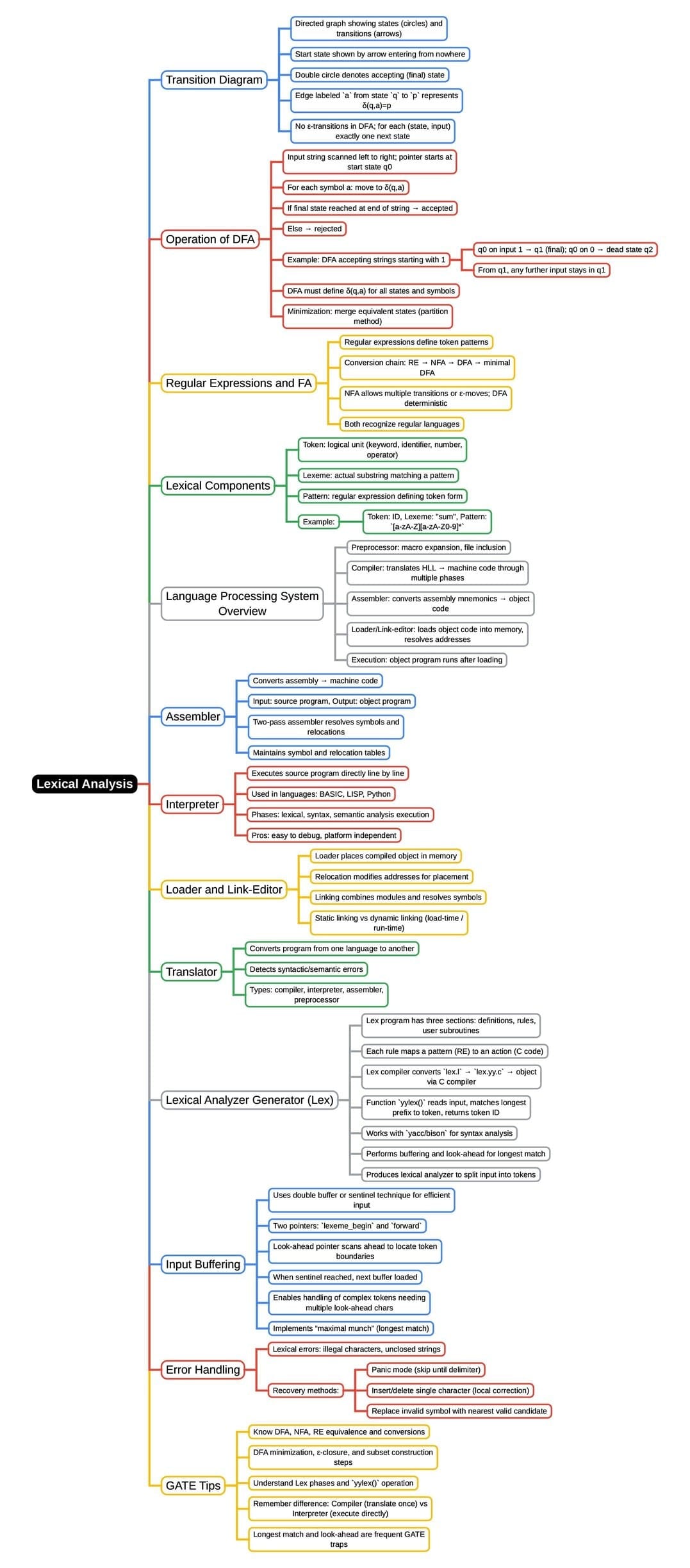
The document Mind Map: Lexical Analysis is a part of the Computer Science Engineering (CSE) Course Compiler Design.
All you need of Computer Science Engineering (CSE) at this link: Computer Science Engineering (CSE)
FAQs on Mind Map: Lexical Analysis
| 1. What is lexical analysis and why is it important in computer science? |  |
Ans.Lexical analysis is the first phase of the compiler design process, where the source code is converted into tokens. It involves breaking down the input text into meaningful symbols or tokens, which can include keywords, identifiers, literals, and operators. This phase is crucial because it simplifies the parsing process by providing a structured representation of the input code, enabling the compiler to understand and process the syntax effectively.
| 2. What are the main components of a lexical analyzer? | |
Ans.The main components of a lexical analyzer include the input buffer, a finite state machine (FSM), and a symbol table. The input buffer holds the source code being analyzed, while the FSM recognizes patterns in the input to generate tokens. The symbol table stores information about identifiers and their attributes, such as type and scope, facilitating the management of variable names and other symbols throughout the program.
| 3. How does a lexical analyzer differ from a parser? | |
Ans.A lexical analyzer and a parser serve different functions in the compilation process. The lexical analyzer focuses on breaking down the source code into tokens and identifying the basic elements of the language, while the parser takes these tokens and organizes them into a hierarchical structure, known as a parse tree or syntax tree, based on grammatical rules. Essentially, the lexical analyzer deals with the "words" of the programming language, while the parser deals with the "sentences."
| 4. What are regular expressions and how are they used in lexical analysis? | |
Ans.Regular expressions are sequences of characters that define search patterns, commonly used for string matching. In lexical analysis, regular expressions are employed to specify the patterns for different token types, such as keywords, operators, and identifiers. The lexical analyzer uses these expressions to recognize tokens in the input source code, allowing it to identify and categorize the various components of the language efficiently.
| 5. Can you explain the process of tokenization in lexical analysis? | |
Ans.Tokenization is the process of converting the input source code into tokens, which are the smallest units of meaning. During tokenization, the lexical analyzer scans the input stream, identifies valid tokens based on predefined rules (often using regular expressions), and discards irrelevant characters like whitespace and comments. Each identified token is then classified and stored in a structured format, which is later used by the parser for further processing of the code.
About this Document

4.73/5 Rating

Apr 30, 2026 Last updated
Related Exams
Document Description: Mind Map: Lexical Analysis for Computer Science Engineering (CSE) 2026 is part of Compiler Design preparation. The notes and questions for Mind Map: Lexical Analysis have been prepared according to the Computer Science Engineering (CSE) exam syllabus. Information about Mind Map: Lexical Analysis covers topics like and Mind Map: Lexical Analysis Example, for Computer Science Engineering (CSE) 2026 Exam. Find important definitions, questions, notes, meanings, examples, exercises and tests below for Mind Map: Lexical Analysis.
Introduction of Mind Map: Lexical Analysis in English is available as part of our Compiler Design for Computer Science Engineering (CSE) & Mind Map: Lexical Analysis in Hindi for Compiler Design course. Download more important topics related with notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free. Computer Science Engineering (CSE): Mind Map: Lexical Analysis
Description
Mind Map: Lexical Analysis of Compiler Design provides you one-page visual summary of the chapter covering all the important topics. Download the PDF from EduRev.
Information about Mind Map: Lexical Analysis
In this doc you can find the meaning of Mind Map: Lexical Analysis defined & explained in the simplest way possible. Besides explaining types of Mind Map: Lexical Analysis theory, EduRev gives you an ample number of questions to practice Mind Map: Lexical Analysis tests, examples and also practice Computer Science Engineering (CSE) tests
 | Explore Courses for Computer Science Engineering (CSE) exam |
 | Get EduRev Notes directly in your Google search |
Related Searches
shortcuts and tricks, Mind Map: Lexical Analysis, Extra Questions, Objective type Questions, MCQs, Free, Mind Map: Lexical Analysis, Sample Paper, Exam, Mind Map: Lexical Analysis, Semester Notes, pdf , past year papers, study material, video lectures, mock tests for examination, ppt, Viva Questions, Important questions, Summary, Previous Year Questions with Solutions, practice quizzes;