SQL | Database Management System (DBMS) - Computer Science Engineering (CSE) PDF Download
Structured Query Language (SQL)
Structured Query Language is a standard Database language which is used to create, maintain and retrieve the relational database.
What is Relational Database?
Relational database means the data is stored as well as retrieved in the form of relations (tables). Table 1 shows the relational database with only one relation called STUDENT which stores ROLL_NO, NAME, ADDRESS, PHONE and AGE of students.
STUDENT

TABLE 1
These are some important terminologies that are used in terms of relation.
Attribute: Attributes are the properties that define a relation. e.g.; ROLL_NO, NAME etc.
Tuple: Each row in the relation is known as tuple. The above relation contains 4 tuples, one of which is shown as:
| 1 | RAM | DELHI | 945512345 | 18 |
Degree: The number of attributes in the relation is known as degree of the relation. The STUDENT relation defined above has degree 5.
Cardinality: The number of tuples in a relation is known as cardinality. The STUDENT relation defined above has cardinality 4.
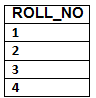
Column: Column represents the set of values for a particular attribute. The column ROLL_NO is extracted from relation STUDENT.
The queries to deal with relational database can be categories as:
Data Definition Language: It is used to define the structure of the database. e.g; CREATE TABLE, ADD COLUMN, DROP COLUMN and so on.
Data Manipulation Language: It is used to manipulate data in the relations. e.g.; INSERT, DELETE, UPDATE and so on.
Data Query Language: It is used to extract the data from the relations. e.g.; SELECT
So first we will consider the Data Query Language. A generic query to retrieve from a relational database is:
- SELECT [DISTINCT] Attribute_List FROM R1,R2….RM
- [WHERE condition]
- [GROUP BY (Attributes)[HAVING condition]]
- [ORDER BY(Attributes)[DESC]];
Part of the query represented by statement 1 is compulsory if you want to retrieve from a relational database. The statements written inside [] are optional. We will look at the possible query combination on relation shown in Table 1.
Case 1: If we want to retrieve attributes ROLL_NO and NAME of all students, the query will be:
SELECT ROLL_NO, NAME FROM STUDENT;
| ROLL_NO | NAME |
| 1 | RAM |
| 2 | RAMESH |
| 3 | SUJIT |
| 4 | SURESH |
Case 2: If we want to retrieve ROLL_NO and NAME of the students whose ROLL_NO is greater than 2, the query will be:
SELECT ROLL_NO, NAME FROM STUDENT
WHERE ROLL_NO>2;
| ROLL_NO | NAME |
| 3 | SUJIT |
| 4 | SURESH |
CASE 3: If we want to retrieve all attributes of students, we can write * in place of writing all attributes as:
SELECT * FROM STUDENT
WHERE ROLL_NO>2;
| ROLL_NO | NAME | ADDRESS | PHONE | AGE |
| 3 | SUJIT | ROHTAK | 9156253131 | 20 |
| 4 | SURESH | DELHI | 9156768971 | 18 |
CASE 4: If we want to represent the relation in ascending order by AGE, we can use ORDER BY clause as:
SELECT * FROM STUDENT ORDER BY AGE;
| ROLL_NO | NAME | ADDRESS | PHONE | AGE |
| 1 | RAM | DELHI | 9455123451 | 18 |
| 2 | RAMESH | GURGAON | 9652431543 | 18 |
| 4 | SURESH | DELHI | 9156768971 | 18 |
| 3 | SUJIT | ROHTAK | 9156253131 | 20 |
Note: ORDER BY AGE is equivalent to ORDER BY AGE ASC. If we want to retrieve the results in descending order of AGE, we can use ORDER BY AGE DESC.
CASE 5: If we want to retrieve distinct values of an attribute or group of attribute, DISTINCT is used as in:
SELECT DISTINCT ADDRESS FROM STUDENT;

If DISTINCT is not used, DELHI will be repeated twice in result set. Before understanding GROUP BY and HAVING, we need to understand aggregations functions in SQL.
AGGRATION FUNCTIONS: Aggregation functions are used to perform mathematical operations on data values of a relation. Some of the common aggregation functions used in SQL are:
- COUNT: Count function is used to count the number of rows in a relation. e.g;
SELECT COUNT (PHONE) FROM STUDENT;

- SUM: SUM function is used to add the values of an attribute in a relation. e.g;
SELECT SUM (AGE) FROM STUDENT;
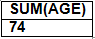
In the same way, MIN, MAX and AVG can be used. As we have seen above, all aggregation functions return only 1 row.
GROUP BY: Group by is used to group the tuples of a relation based on an attribute or group of attribute. It is always combined with aggregation function which is computed on group. e.g.;
SELECT ADDRESS, SUM(AGE) FROM STUDENT
GROUP BY (ADDRESS);
In this query, SUM(AGE) will be computed but not for entire table but for each address. i.e.; sum of AGE for address DELHI(18+18=36) and similarly for other address as well. The output is:
| ADDRESS | SUM(AGE) | |
| DELHI | 36 | |
| GURGAON | 18 | |
| ROHTAK |
|
If we try to execute the query given below, it will result in error because we have computed SUM(AGE) for each address and there can be more than 1 student for each address. So it can’t be displayed in result set.
SELECT ROLL_NO, ADDRESS, SUM(AGE) FROM STUDENT
GROUP BY (ADDRESS);
NOTE: An attribute which is not a part of GROUP BY clause can’t be used for selection. Any attribute which is part of GROUP BY CLAUSE can be used for selection but it is not mandatory.
Inner Join vs Outer Join
What is Join?
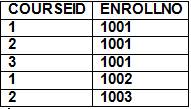
An SQL Join is used to combine data from two or more tables, based on a common field between them. For example, consider the following two tables.
Student Table

StudentCourse Table
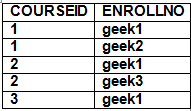
Following is join query that shows names of students enrolled in different courseIDs.
SELECT StudentCourse.CourseID,Student.StudentName
FROM Student
INNER JOIN StudentCourse
ON StudentCourse.EnrollNo = Student.EnrollNo
ORDER BY StudentCourse.CourseID
Note: INNER is optional above. Simple JOIN is also considered as INNER JOIN
The above query would produce following result.
What is the difference between inner join and outer join?
Outer Join is of 3 types
1) Left outer join
2) Right outer join
3) Full Join
1) Left outer join returns all rows of table on left side of join. The rows for which there is no matching row on right side, result contains NULL in the right side.
SELECT Student.StudentName,
StudentCourse.CourseID
FROM Student
LEFT OUTER JOIN StudentCourse
ON StudentCourse.EnrollNo = Student.EnrollNo
ORDER BY StudentCourse.CourseID
Note: OUTER is optional above. Simple LEFT JOIN is also considered as LEFT OUTER JOIN
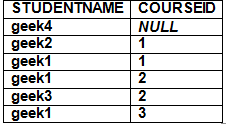
2) Right Outer Join is similar to Left Outer Join (Right replaces Left everywhere)
3) Full Outer Join Contains results of both Left and Right outer joins.
Having vs Where Clause?
The difference between the having and where clause in SQL is that the where clause cannot be used with aggregates, but the having clause can.
The where clause works on row’s data, not on aggregated data. Let us consider below table ‘Marks’
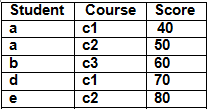
Consider the query
SELECT Student, Score FROM Marks WHERE Score >=40a
This would select data row by row basis.
The having clause works on aggregated data.
For example, output of below query
SELECT Student, SUM(score) AS total FROM Marks GROUP BY Student
| Student | Total |
| a | 90 |
| b | 60 |
| d | 70 |
| e | 80 |
When we apply having in above query, we get
SELECT Student, SUM(score) AS total FROM Marks GROUP BY Student
HAVING total > 70
| Student | Total |
| a | 90 |
| e | 80 |
Note: It is not a predefined rule but in a good number of the SQL queries, we use WHERE prior to GROUP BY and HAVING after GROUP BY. The Where clause acts as a pre filter where as Having as a post filter.
DBMS | Nested Queries in SQL
Prerequisites : Basics of SQL
In nested queries, a query is written inside a query. The result of inner query is used in execution of outer query. We will use STUDENT, COURSE, STUDENT_COURSE tables for understanding nested queries.
STUDENT

COURSE
| C_ID | C_NAME |
| C1 | DSA |
| C2 | Programming |
| C3 | DBMS |
STUDENT_COURSE
| S_ID | C_ID |
| S1 | C1 |
| S1 | C3 |
| S2 | C1 |
| S3 | C2 |
| S4 | C2 |
| S4 | C3 |
There are mainly two types of nested queries:
- Independent Nested Queries: In independent nested queries, query execution starts from innermost query to outermost queries. The execution of inner query is independent of outer query, but the result of inner query is used in execution of outer query. Various operators like IN, NOT IN, ANY, ALL etc are used in writing independent nested queries.
IN: If we want to find out S_ID who are enrolled in C_NAME ‘DSA’ or ‘DBMS’, we can write it with the help of independent nested query and IN operator. From COURSE table, we can find out C_ID for C_NAME ‘DSA’ or DBMS’ and we can use these C_IDs for finding S_IDs from STUDENT_COURSE TABLE.
STEP 1: Finding C_ID for C_NAME =’DSA’ or ‘DBMS’
Select C_ID from COURSE where C_NAME = ‘DSA’ or C_NAME = ‘DBMS’
STEP 2: Using C_ID of step 1 for finding S_ID
Select S_ID from STUDENT_COURSE where C_ID IN
(SELECT C_ID from COURSE where C_NAME = ‘DSA’ or C_NAME=’DBMS’);
The inner query will return a set with members C1 and C3 and outer query will return those S_IDs for which C_ID is equal to any member of set (C1 and C3 in this case). So, it will return S1, S2 and S4.
Note: If we want to find out names of STUDENTs who have either enrolled in ‘DSA’ or ‘DBMS’, it can be done as:
Select S_NAME from STUDENT where S_ID IN
(Select S_ID from STUDENT_COURSE where C_ID IN
(SELECT C_ID from COURSE where C_NAME=’DSA’ or C_NAME=’DBMS’));
NOT IN: If we want to find out S_IDs of STUDENTs who have neither enrolled in ‘DSA’ nor in ‘DBMS’, it can be done as:
Select S_ID from STUDENT where S_ID NOT IN
(Select S_ID from STUDENT_COURSE where C_ID IN
(SELECT C_ID from COURSE where C_NAME=’DSA’ or C_NAME=’DBMS’));
The innermost query will return a set with members C1 and C3. Second inner query will return those S_IDs for which C_ID is equal to any member of set (C1 and C3 in this case) which are S1, S2 and S4. The outermost query will return those S_IDs where S_ID is not a member of set (S1, S2 and S4). So it will return S3. - Co-related Nested Queries: In co-related nested queries, the output of inner query depends on the row which is being currently executed in outer query. e.g.; If we want to find out S_NAME of STUDENTs who are enrolled in C_ID ‘C1’, it can be done with the help of co-related nested query as:
Select S_NAME from STUDENT S where EXISTS
(select * from STUDENT_COURSE SC where S.S_ID=SC.S_ID and SC.C_ID=’C1’);
For each row of STUDENT S, it will find the rows from STUDENT_COURSE where S.S_ID = SC.S_ID and SC.C_ID=’C1’. If for a S_ID from STUDENT S, atleast a row exists in STUDENT_COURSE SC with C_ID=’C1’, then inner query will return true and corresponding S_ID will be returned as output.
|
62 videos|66 docs|35 tests
|
FAQs on SQL - Database Management System (DBMS) - Computer Science Engineering (CSE)
| 1. What is SQL in Computer Science Engineering (CSE)? |  |
| 2. How is SQL used in Computer Science Engineering (CSE)? | |
| 3. What are the benefits of learning SQL for Computer Science Engineering (CSE) students? | |
| 4. Are there any resources available to learn SQL for Computer Science Engineering (CSE) students? | |
| 5. How can SQL skills be beneficial for future career prospects in Computer Science Engineering (CSE)? | |

|
1.5K Views |

|
4.98/5 Rating |

|
Jan 03, 2025 Last updated |

|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
study material
,Semester Notes
,Free
,video lectures
,Previous Year Questions with Solutions
,SQL | Database Management System (DBMS) - Computer Science Engineering (CSE)
,Important questions
,past year papers
,MCQs
,SQL | Database Management System (DBMS) - Computer Science Engineering (CSE)
,SQL | Database Management System (DBMS) - Computer Science Engineering (CSE)
,practice quizzes
,ppt
,mock tests for examination
,Viva Questions
,Summary
,Exam
,Objective type Questions
,Extra Questions
,shortcuts and tricks
,Sample Paper
;






SQL Free PDF Download
Importance of SQL
SQL Notes
SQL Computer Science Engineering (CSE) Questions
Study SQL on the App
|
© EduRev
|
Education Revolution
|



|




