Normal Forms


Introduction
Database normalization is the process of organising the attributes and relations of a database to reduce or eliminate data redundancy (the same data stored at different places) and to avoid anomalies in insert, delete and update operations. Normalisation uses the notion of functional dependency to decide how to split relations so that redundancy and anomalies are minimised while essential information and query capability are preserved.
Functional Dependency (FD)
A functional dependency is a constraint between two sets of attributes X and Y in a relation R. It means that for any two tuples of R, if the values of attributes X are the same, then the values of attributes Y must also be the same. We denote this by X → Y.
Example: employee_id → name means employee_id functionally determines name. In a timetable, {student_id, time} → lecture_room means student and time together determine the lecture room.
What "X → Y" means
X → Y means: for every value of X that appears in the relation, there is exactly one corresponding value of Y. If two tuples have the same X value, they must have the same Y value.
Trivial and Non-trivial Functional Dependencies
- Trivial FD: X → Y is trivial if Y ⊆ X. Example: ABC → AB, ABC → A, ABC → ABC.
- Non-trivial FD: X → Y is non-trivial if Y ⊄ X. A further refinement: X → Y is completely non-trivial when X ∩ Y = ∅. Example: Id → Name, Name → DOB.
Other important types of dependencies
- Partial dependency: a non-prime attribute depends on a proper subset of a candidate key. Important in definition of 2NF.
- Transitive dependency: a non-prime attribute depends on another non-prime attribute (A → B and B → C gives A → C) - important in definition of 3NF.
Keys and Prime Attributes
Superkey: a set of attributes S such that S functionally determines all attributes of the relation.
Candidate key: a minimal superkey (no proper subset is a superkey).
Primary key: one chosen candidate key to identify tuples.
Prime attribute: an attribute that is part of some candidate key. Non-prime attribute is not part of any candidate key.
Normal Forms (overview)
Normal forms are standardised levels of design that progressively reduce redundancy and anomalies. Each normal form builds on previous ones. The commonly covered normal forms are 1NF, 2NF, 3NF and BCNF. Higher forms (4NF, 5NF, etc.) exist but are less commonly required in typical systems.
First Normal Form (1NF)
A relation is in First Normal Form if every attribute contains atomic (single) values only - no repeating groups, no multi-valued or composite attributes. Relational DBMSs enforce 1NF by design.
Example:

Second Normal Form (2NF)
A relation is in Second Normal Form if
- it is in 1NF, and
- there is no partial dependency: no non-prime attribute is functionally dependent on a proper subset of any candidate key.
In other words, every non-prime attribute must depend on the whole of every candidate key, not on a part of it.
Third Normal Form (3NF)
A relation is in Third Normal Form if it is in 2NF and, for every non-trivial FD X → A, at least one of the following holds:
- X is a superkey, or
- A is a prime attribute (A is part of some candidate key).
Equivalently, 3NF disallows transitive dependencies of non-prime attributes on candidate keys.
Boyce-Codd Normal Form (BCNF)
A relation is in BCNF if, for every non-trivial FD X → Y, X is a superkey. BCNF is a stronger condition than 3NF. Every relation in BCNF is in 3NF, but the converse need not be true.
Note: Decomposing to BCNF can sometimes cause loss of dependency preservation. When dependency preservation matters, 3NF may be preferred.
Key Points and Practical Remarks
- BCNF is stricter than 3NF and removes more redundancy where applicable.
- If a relation is in BCNF, it is also in 3NF.
- If all attributes of a relation are prime attributes, the relation is automatically in 3NF.
- A relation in a relational DBMS is at least in 1NF.
- Every binary relation (relation with only 2 attributes) is always in BCNF.
- If every candidate key is a singleton attribute (single attribute), partial dependency cannot occur; the relation is automatically in 2NF.
- Sometimes converting to BCNF may not preserve all functional dependencies. When a dependency must be preserved, normalise to 3NF instead of BCNF.
- Higher normal forms beyond BCNF such as 4NF exist (they address multivalued dependencies etc.), but are less commonly required in practical systems.
Exercise 1
Find the highest normal form in R (A, B, C, D, E) under following functional dependencies.
ABC --> D
CD --> AE
Important Points for solving above type of question.
1) It is always a good idea to start checking from BCNF, then 3NF and so on.
2) If any functional dependency satisfies a normal form then there is no need to check for lower normal form. For example, ABC -> D is in BCNF (Note that ABC is a superkey), so there is no need to check this dependency for lower normal forms.
Candidate keys in given relation are {ABC, BCD}.
BCNF: ABC → D is in BCNF. Let us check CD → AE. CD is not a superkey so this dependency is not in BCNF. So R is not in BCNF.
3NF: ABC → D we do not need to check as it already satisfied BCNF. Consider CD → AE. Since E is not a prime attribute, the dependency CD → AE violates the 3NF condition. So R is not in 3NF.
2NF: Check for partial dependency. CD is a proper subset of candidate key BCD and it determines E (a non-prime attribute). So partial dependency exists and relation is not in 2NF.
Therefore the highest normal form for R is 1NF.
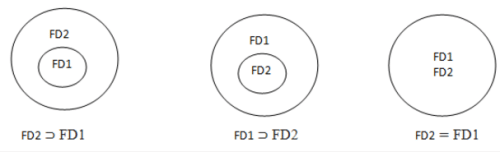
Equivalence of Functional Dependency Sets
Two sets of functional dependencies FD1 and FD2 for the same relation are equivalent if they have the same logical consequences, i.e. each FD in FD1 can be derived from FD2 and each FD in FD2 can be derived from FD1. To test this we commonly compute attribute closures and check derivations.
Given FD1 and FD2:
- If every FD of FD1 can be derived from FD2, then FD2 ⊃ FD1.
- If every FD of FD2 can be derived from FD1, then FD1 ⊃ FD2.
- If both hold, FD1 = FD2 (semantic equivalence).
Worked example - equivalence check
Q. Let us take an example to show the relationship between two FD sets. A relation R(A,B,C,D) having two FD sets FD1 = {A->B, B->C, AB->D} and FD2 = {A->B, B->C, A->C, A->D}
Step 1. Checking whether all FDs of FD1 are present in FD2.
A → B in set FD1 is present in set FD2.
B → C in set FD1 is present in set FD2.
AB → D is present in FD1 but not explicitly in FD2. Compute closure (AB)+ using FD2: (AB)+ = {A, B, C, D}. Therefore AB → D is implied by FD2.
So all FDs of FD1 hold in FD2; FD2 ⊃ FD1.
Step 2. Checking whether all FDs of FD2 are present in FD1.
A → B in FD2 is in FD1.
B → C in FD2 is in FD1.
A → C in FD2 is not explicit in FD1. Compute A+ using FD1: (A)+ = {A, B, C, D}. So A → C is implied by FD1.
A → D in FD2 is not explicit in FD1. Using (A)+ = {A, B, C, D} we also have A → D implied by FD1.
So all FDs of FD2 hold in FD1; FD1 ⊃ FD2.
Step 3. Since FD2 ⊃ FD1 and FD1 ⊃ FD2, FD1 = FD2. These two FD sets are semantically equivalent.
Second worked example - non-equivalence
Q. Let us take another example to show the relationship between two FD sets. A relation R2(A,B,C,D) having two FD sets FD1 = {A->B, B->C,A->C} and FD2 = {A->B, B->C, A->D}
Step 1. Checking whether all FDs of FD1 are present in FD2.
A → B in FD1 is present in FD2.
B → C in FD1 is present in FD2.
A → C in FD1 is not explicit in FD2. Compute A+ under FD2: (A)+ = {A, B, C, D}. So A → C is implied by FD2.
Therefore FD2 ⊃ FD1.
Step 2. Checking whether all FDs of FD2 are present in FD1.
A → B in FD2 is in FD1.
B → C in FD2 is in FD1.
A → D in FD2 is not in FD1 and computing A+ under FD1 gives (A)+ = {A, B, C}. D is not in the closure, so A → D is not implied by FD1.
Therefore FD2 ⊄ FD1 and the two sets are not equivalent.
How to find the highest normal form of a relation (procedure)
Before applying the steps, you must be comfortable with computing attribute closure and finding all candidate keys.
Steps:
- Find all candidate keys of the relation (using closure computations).
- Classify attributes as prime (part of some candidate key) and non-prime.
- Verify normal forms in descending order: check BCNF first, then 3NF, then 2NF, then 1NF. If the relation fails an n-th normal form, the highest normal form is (n-1)NF.
Examples (finding highest normal form)
Example 1. Find the highest normal form of R(A,B,C,D,E) with FD set {A->D, B->A, BC->D, AC->BE}
Step 1. Compute closures to find candidate keys.
(AC)+ = {A, C, B, E, D} so AC determines all attributes and is a candidate key.
A can be derived from B (B → A), so replacing A in AC by B gives BC. Compute (BC)+ = {B, C, D, A, E} so BC is also a candidate key.
Therefore candidate keys are {AC, BC}.
Step 2. Prime attributes = {A, B, C}. Non-prime attributes = {D, E}.
Step 3. 1NF: relation is in 1NF (relational model assumption).
Check 2NF: A → D is a partial dependency because A is a proper subset of candidate key AC and D is non-prime. Thus relation is not in 2NF.
Therefore highest normal form is 1NF.
Example 2. Find the highest normal form of R(A,B,C,D,E) with FD set {BC->D, AC->BE, B->E}
Step 1. (AC)+ = {A, C, B, E, D} so AC is a candidate key. No subset of AC determines all attributes, so candidate key set = {AC}.
Step 2. Prime attributes = {A, C}. Non-prime attributes = {B, D, E}.
Step 3. 1NF: relation is in 1NF.
2NF: check partial dependencies. BC → D is fine because BC is not a proper subset of candidate key AC. AC → BE is fine because AC is the candidate key. B → E: B is not a subset of the candidate key AC, so not partial with respect to AC. Hence relation is in 2NF.
3NF: check each non-trivial FD. For BC → D, BC is not a superkey and D is not a prime attribute - this violates the 3NF condition. Also B → E violates 3NF for the same reason. Therefore relation is not in 3NF.
Highest normal form is 2NF.
Example 3. Find the highest normal form of R(A,B,C,D,E) with FD set {B->A, A->C, BC->D, AC->BE}
Step 1. (B)+ = {B, A, C, E, D} so B determines all attributes; B is a candidate key.
AC → BE implies AC is a superkey. Compute closures for subsets: (A)+ = {A, C, B, E, D} so A is also a candidate key. Therefore candidate keys are {A, B}.
Step 2. Prime attributes = {A, B}. Non-prime attributes = {C, D, E}.
Step 3. 1NF: holds.
2NF: check dependencies - B → A (B is a superkey), A → C (A is a superkey), BC → D (BC is a superkey), AC → BE (AC is a superkey). No partial dependencies exist, so relation is in 2NF.
3NF: each FD has LHS as a superkey, hence 3NF holds.
BCNF: since every FD has LHS a superkey, BCNF holds.
Therefore the highest normal form is BCNF.
Attribute Closure (useful method)
To test whether X → Y follows from a given FD set F, compute the closure X+ under F. If Y ⊆ X+, then X → Y is implied by F. Attribute closure is also the standard method to find candidate keys: compute closure of attribute sets and find minimal sets whose closure contains all attributes.
Practical steps to normalise a schema
- List all attributes and functional dependencies.
- Find candidate keys using attribute closures.
- Decide prime and non-prime attributes.
- Check and remove partial dependencies to achieve 2NF by decomposing relations where necessary.
- Remove transitive dependencies to achieve 3NF (or use synthesis algorithm to produce dependency-preserving 3NF decomposition).
- Consider BCNF decomposition if stricter elimination of redundancy is required and dependency preservation is not essential or can be restored by additional design choices.
Summary (optional)
Normalization uses functional dependencies and keys to organise relations into forms that reduce redundancy and anomalies. Start by ensuring 1NF, then check for partial dependencies (2NF), transitive dependencies and prime-attribute conditions (3NF), and finally the stronger BCNF condition that every determinant is a superkey. Use attribute closure to find keys and to test implications of FDs. When normalising, balance redundancy reduction against practical concerns such as dependency preservation and query performance.
FAQs on Normal Forms
| 1. What are the different normal forms in computer science engineering? |  |
| 2. How does First Normal Form (1NF) ensure data integrity? | |
| 3. What is the role of Second Normal Form (2NF) in database design? | |
| 4. How does Third Normal Form (3NF) improve database performance? | |
| 5. What is the significance of Boyce-Codd Normal Form (BCNF) in database normalization? | |



 | Explore Courses for Computer Science Engineering (CSE) exam |
 | Get EduRev Notes directly in your Google search |