Statistics Class 9 Notes - Mathematics, Class 9 PDF Download
INTRODUCTION
In various fields, we need information in the form of numerical figures called data.
These data may relate to the marks obtained by the pupils of a class in a certain examination; the weights, heights, ages, etc., of pupils in a class; the monthly wages earned by workers in a factory; the population of a town or the profits of a company during last few years, etc.
Evaluation of such data helps analysts study the various growth patterns and formulate future targets or policies or derive certain inferences.
STATISTICS
It is the science which deals with the collection, presentation, analysis and interpretation of numerical data.
In singular form, statistics is taken as a subject. And, in plural form, statistics means data.
DATA
The word data means a set of given facts in numerical figures.
Fundamental Characteristics of Data
(i) Numerical facts alone form data. Qualitative characteristics, like honesty, poverty, etc., which cannot be measured numerically do not form data.
(i) Data are aggregate of facts. A single observation does not form data.
(ii) Data collected for a definite purpose may not be suitable for another purpose.
Types of Data
(i) Primary Data : The data collected by the investigator himself with a definite plan in mind are known as primary data.
(ii) Secondary Data : The data collected by someone, other than the investigator, are known as secondary data.
VARIABLE
A quantity which can take different values is called a variable.
Ex : Height, Age and Weight of pupils in a class are three variables.
If we denote them by x, y and z respectively, then values of x give the heights of the pupils; the values of y give the ages of the pupils and the values of z give the weights of the pupils.
Continuous and Discrete Variables
Variables are of 2 types
1. Continuous Variable : A variable which can take any numerical value within a certain range is called a continuous variable.
Ex.
(i) Wages of workers in a factory
(ii) Heights of children in a class
(iii) Weights of persons in a group etc.
2. Discontinuous (or Discrete) Variable : A variable which cannot take all possible values between two given values, is called a discontinuous or discrete variable.
Ex.
(i) Number of members in a family
(ii) Number of workers in a factory
Such variables cannot take any value between 1 and 2, 2 and 3, etc.
IMPORTANT TERMS
Range : The difference between the maximum and minimum values of a variable is called its range.
Variate : A particular value of a variable is called variate.
Presentation of Data : Putting the data in condensed form in the form of a table, is known as presentation of data.
Frequency : The number of times an observation occurs is called its frequency.
Frequency Distribution : The tabular arrangement of data showing the frequency of each observation is called its frequency distribution.
RAW OR UNGROUPED DATA
The data obtained in original form are called raw data or ungrouped data.
Ex. The marks obtained by 25 students in a class in a certain examination are given below:
25, 8, 37, 16, 45, 40, 29, 12, 42, 40, 25, 14, 16, 16, 20, 10, 36, 33, 24, 25, 35, 11, 30, 45,48.
This is the raw data.
Array : An arrangement of raw data in ascending or descending order of magnitude is called an array.
Arranging the marks of 25 students in ascending order, we get the following array.
8, 10, 11, 12, 14, 16, 16, 16, 20, 24, 25, 25, 25, 29, 30, 33, 35, 36, 37, 40, 40, 42, 45, 45, 48.
TO PREPARE A FREQUENCY DISTRIBUTION TABLE FOR RAW DATA USING TALLY MARKS
We take each observation from the data, one at a time, and indicate the frequency (the number of times the observation has occurred in the data) by small lines, called tally marks. For convenience, we write tally marks in bunches of five, the fifth one crossing the fourth diagonally. In the table so formed, the sum of all the frequencies is equal to the total number of observations in the given data.
Ex. The sale of shoes of various sizes at a shop, on a particular day is given below:
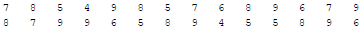
The above data is clearly raw data.
From this data, we may construct a frequency table, as given below :
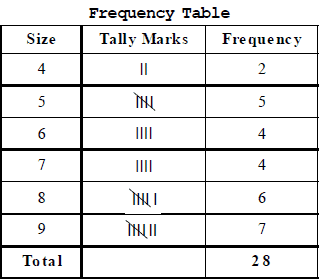
To put the data in a more condensed form, we make groups of suitable size, and mention the frequency of each group.
Such a table is called a grouped frequency distribution table.
GROUPED DATA
To put the data in a more condensed form, we make groups of suitable size, and mention the frequency of each group.
Such a table is called a grouped frequency distribution table.
Class-Interval : Each group into which the raw data is condensed, is called a class-interval.
Each class is bounded by two figures, which are called class limits. The figure on the left side of a class is called its lower limit and that on its right is called its upper limit.
Types of Grouped Frequency Distribution
1. Exclusive Form (or Continuous Interval Form) : A frequency distribution in which the upper limit of each class is excluded and lower limit is included, is called an exclusive form.
Ex. Suppose the marks obtained by some students in an examination are given.
We may consider the classes 0 – 10, 10 – 20 etc. In class 0 – 10, we include 0 and exclude 10. In class 10
- 20, we include 10 and exclude 20.
2. Inclusive Form (or Discontinuous Interval Form) : A frequency distribution in which each upper limit as well as lower limit is included, is called an inclusive form. Thus, we have classes of the form 0 – 10, 11 – 20, 21 – 30 etc. In 0 – 10, both 0 and 10 are included.
Ex.1 Given below are the marks obtained by 40 students in an examination :
3, 25, 48, 23, 17, 13, 11, 9, 46, 41, 37, 45, 10, 19, 39, 36, 34, 5, 17, 21,
39, 33, 28, 25, 12, 3, 8, 17, 48, 34, 15, 19, 32, 32, 19, 21, 28, 32, 20, 23.
Arrange the data in ascending order and present it as a grouped data in :
(i) Discontinuous Interval form, taking class-intervals 1 – 10, 11 – 20, etc.
(ii) Continuous Interval form, taking class-intervals 1 – 10, 10 – 20, etc.
Sol. Arranging the marks in ascending order, we get:
3, 3, 5, 8, 9, 10, 11, 12, 13, 15, 17, 17, 17, 19, 19, 19, 20, 21, 21, 23,
23, 25, 25, 28, 28, 32, 32, 32, 33, 34, 34, 36, 37, 39, 39, 41, 45, 46, 48, 48.
We may now classify them into groups as shown below:
(i) Discontinuous Interval Form (or Inclusive Form)
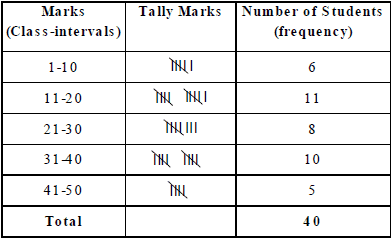
Note that the class 1 – 10 means, marks obtained from 1 to 10, including both.
(ii) Continuous Interval Form (or Exclusive Form)
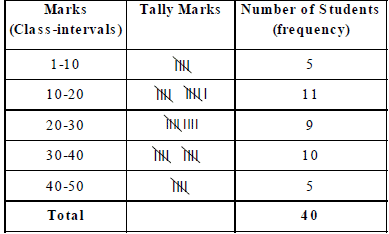
Here, the class 1 – 10 means, marks obtained from 1 to 9, i.e., excluding 10.
IMPORTANT TERMS RELATED TO GROUPED DATA
1. Class Boundaries Or True Upper And True Lower Limits :
(i) In the exclusive form, the upper and lower limits of a class are respectively known as the true upper limit
and true lower limit.
(ii) In the inclusive form, the number midway between the upper limit of a class and lower limit of the subsequent
class gives the true upper limit of the class and the true lower limit of the subsequent class ..
Thus, in the above table of inclusive form, we have :
true upper limit of class 1 – 10 is 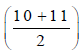 = 10.5, and, true lower limit of class 11 – 20 is 10.5.
= 10.5, and, true lower limit of class 11 – 20 is 10.5.
Similarly, true upper limit of class 11 – 20 is 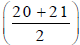 = 20.5, and, true lower limit of class 21 – 30 is 20.5.
= 20.5, and, true lower limit of class 21 – 30 is 20.5.
2. Class Size : The difference between the true upper limit and the true lower limit of a class is called its class size.
3. Class Mark of A Class =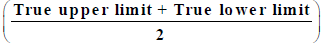
The difference between any two successive class marks gives the class size.
Ex.2 The class marks of a frequency distribution are 7, 13, 19, 25, 31, 37, 43. Find the class-size
and all the class-intervals.
Sol. Class size = Difference between two successive class-marks = (13 – 7) = 6.
Let the lower limit of the first class interval be a. Then, its upper limit = (a + 6).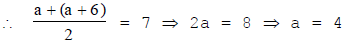
So, the first class-interval is 4 – 10.
Let the lower limit of last class-interval be b.
Then, its upper class limit = (b + 6).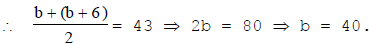
So, the last class-interval is 40 – 46.
Hence, the required class-intervals are 4 – 10, 10 – 16, 16 – 22, 22 – 28, 28 – 34, 34 – 40 and 40 – 46.
METHOD OF FORMING CLASSES OF A DATA
1. Determine the maximum and minimum values of the variate occurring in the data.
2. Decide upon the number of classes to be formed.
3. Find the range, i.e., the difference between the maximum value and the minimum value. Divide the range by
the number of classes to be formed to get the class-size.
4. Be sure that there must be classes having minimum and maximum values occurring in the data.
5. By counting, we obtain the frequency of each class.
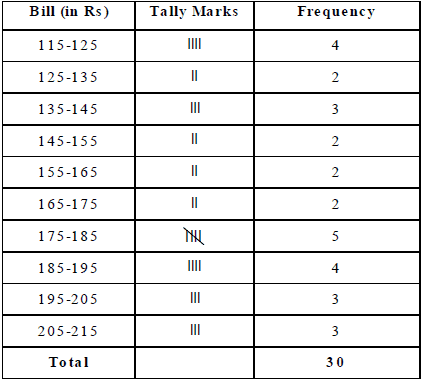
Ex.3 The water tax bills (in rupees) of 30 houses in a locality are given below :
147, 167, 136, 178, 175, 116, 155, 121, 115, 156, 176, 141, 189, 167, 177,
208, 212, 143, 203, 210, 188, 178, 212, 118, 197, 145, 134, 133, 196, 185.
Construct a frequency-distribution table with class-size 10.
Sol. Minimum observation = 115, Maximum observation = 212.
Range = (Maximum observation) – (Minimum observation) = (212 – 115) = 97.
Class size = 10.
Since 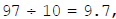 , we should have 10 classes, each of size 10. These classes are:
, we should have 10 classes, each of size 10. These classes are:
115 – 125, 125 – 135, 135 – 145, 145 – 155, 155 – 165, 165 – 175, 175 – 185, 185 – 195, 195
– 205 and 205 – 215. The frequency distribution table may be presented as shown below :
The frequency distribution table may be presented as shown below :
RULE TO CONVERT DISCONTINUOUS (OR INCLUSIVE) FORM TO CONTINUOUS (OR EXCLUSIVE) FORM
In a discontinuous interval or inclusive form, we have :
Adjustment factor = (1 over 2)[(Lower limit of one class – Upper limit of previous class)]
Thus, if the classes are 1 – 10, 11 – 20, etc., then adjustment factor = (1 over 2) (11 – 10) = 0.5.
To convert data given in discontinuous form to the continuous form, we subtract the adjustment factor from each lower limit and add the adjustment factor to each upper limit to get the true limits.
Ex. 4 Convert the following frequency distribution from discontinuous to continuous form:
Sol. Adjustment factor = (1 over 2)(11 – 10) = 0.5. Subtract 0·5 from each lower limit and add 0·5 to each upper limit.
Then, the required table in continuous form may be prepared as under :
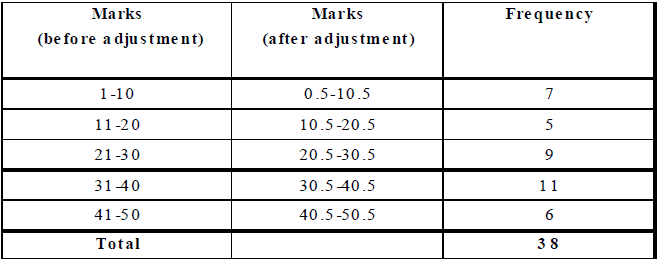
CUMULATIVE FREQUENCY OF A CLASS-INTERVAL
The sum of the frequencies of all the previous classes and that particular class, is called the cumulative frequency of the class.
Cumulative Frequency Table
A table which shows the cumulative frequencies over various classes is called a cumulative frequency distribution table.
Ex.5 Following are the ages (in years) of 360 patients, getting medical treatment in a hospital.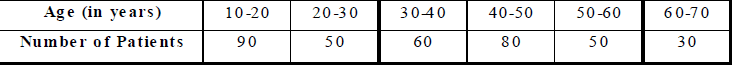
Construct the cumulative frequency table for the above data.
Sol. The cumulative frequency table for the above data is given below.
This table may be presented in 'less than form', as under.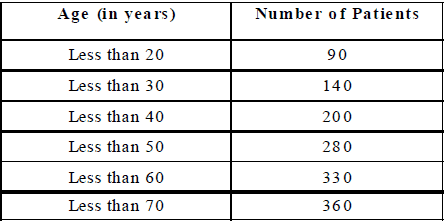
Ex.6 The monthly wages (in rupees) of 28 labourers working in a factory, are given below .-
220, 268, 258, 242, 210, 267, 272, 242, 311, 290, 300, 320, 319, 304,
302, 292, 254, 278, 318, 306, 210, 240, 280, 316, 306, 215, 256, 328.
Form a cumulative frequency table with class intervals of length 20.
Sol. We may form the table as under :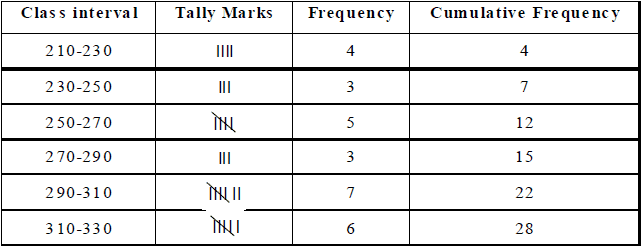
GRAPHICAL REPRESENTATION OF STATISTICAL DATA
The tabular representation of data is an ideal way of presenting them in a systematic manner. When these numerical figures are represented pictorially or graphically, they become more noticeable and easily intelligible, leaving a more lasting effect on the mind of the observer. With the help of these pictures or graphs, data can be compared easily.
There are various types of graphs. In this chapter, we shall be dealing with the following graphs:
1. Bar Graphs
2. Histogram
3. Frequency Polygon
BAR GRAPH (OR COLUMN GRAPH OR BAR CHART)
A bar graph is a pictorial representation of numerical data in the form of rectangles (or bars) of equal width and varying heights.
These rectangles are drawn either vertically or horizontally.
The height of a bar represents the frequency of the corresponding observation.
The gap between two bars is kept the same.
Ex.7 The following table shows the number of students participating in various games in a school.
Draw a bar graph to represent the above data.
Sol. Take the games along x-axis and the number of students along Y-axis.
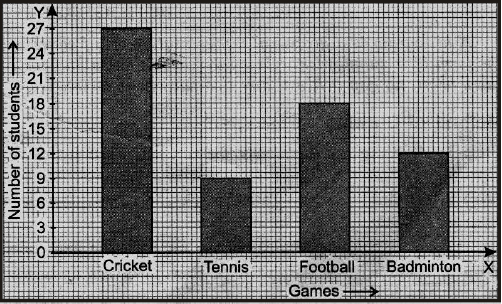
Along y-axis, take the scale 1 cm = 6 students. The bar-graph may, thus, be drawn as shown alongside.
Ex.8 Given below are data showing number of students of a school using different modes of travel to school.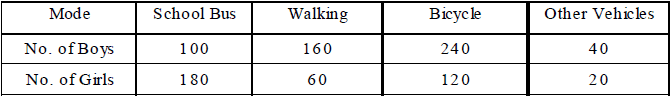
Draw a bar graph to represent the above data.
Sol. Take the mode along x-axis and the number of students along y-axis.
Scale : Along y-axis, take 1 cm = 40 students.
The bars of equal width and proportionate heights with same gap between the two consecutive bars, may be drawn as shown below.
Shading for boys and girls may be done as under :
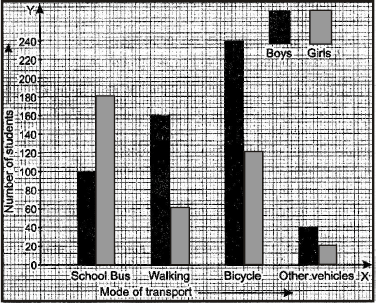
HISTOGRAM
A histogram is a graphical representation of a frequency distribution in an exclusive form in the form of rectangles with class intervals as bases and the corresponding frequencies as heights, there being no gap between any two successive rectangles.
METHOD OF DRAWING A HISTOGRAM
Step 1 : If the given frequency distribution is in inclusive form, convert it into an exclusive form.
Step 2 : Taking suitable scales, mark the class-intervals along x-axis and frequencies along y-axis.
Note that the scales chosen for both the axes need not be the same.
Step 3 : Construct rectangles with class-intervals as bases and the corresponding frequencies as heights.
Ex.9 Draw a histogram to represent the following data :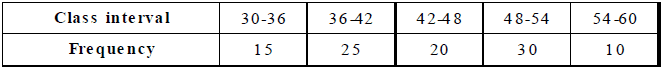
Sol. Draw rectangles with bases 30 – 36, 36 – 42, 42 – 48, 48 – 54 and 54 – 60 and heights 15, 25, 20,
30 and 10 respectively.
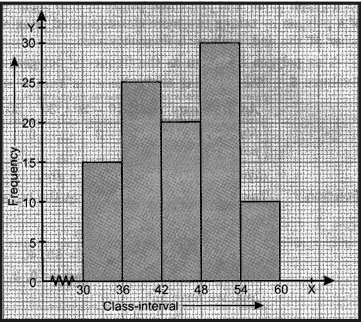
Note : Since the scale on x-axis starts at 30, we make a kink ( ) in the beginning.
Ex.10 Draw a histogram for the following data :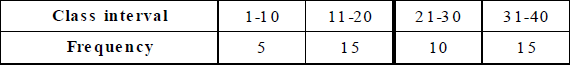
Sol. The given table is in inclusive-form. So, we first convert it into an exclusive form, as given below.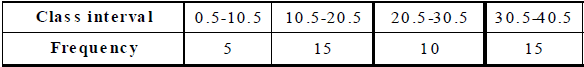
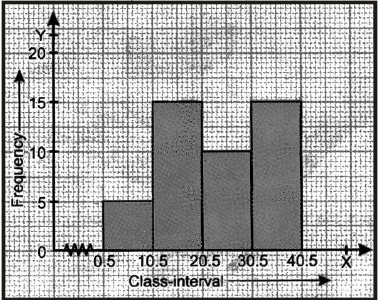
Now, we may draw the histogram, as shown below.
Note : Since the scale on x-axis starts at 0.5, a kink is shown near the origin.
FREQUENCY POLYGON
Let x1, x2, ..., xn be the class marks (i.e., mid points) of the given frequency distribution and let f1, f2, ..... fn be the corresponding frequencies. We plot the points (x1, f1), (x2, f2),..., (xn, fn) on a graph paper and join these points by line segments. We complete the diagram in the form of a polygon by taking two more classes (called imagined classes), one at the beginning and the other at the end, each with frequency zero.
This polygon is known as the frequency polygon of the given frequency distribution.
Ex.11 The following table shows the number of diabetic patients at various age groups.
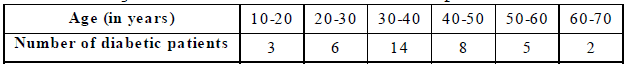
Represent the above data by a frequency polygon.
Sol. Take two more intervals one at the beginning and the other at the end, each with frequency 0. Thus, we have class-intervals
0 – 10, 10 – 20, 20 – 30, 30 – 40, 40 – 50, 50 – 60, 60 – 70 and 70 – 80 with corresponding frequencies as 0, 3, 6, 14, 8, 5, 2, 0 respectively. Thus, we have :
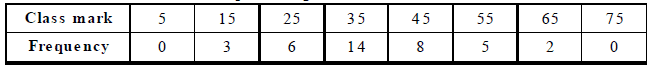
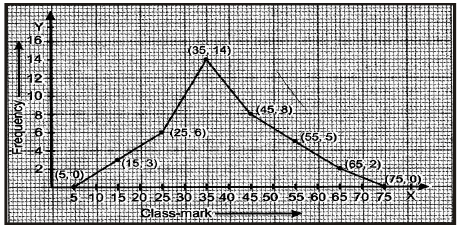
Now, plot the points (5, 0), (15, 3), (25, 6), (35, 14), (45, 8), (55, 5), (65, 2), (75, 0) on a graph paper and join them successively to get the required graph.
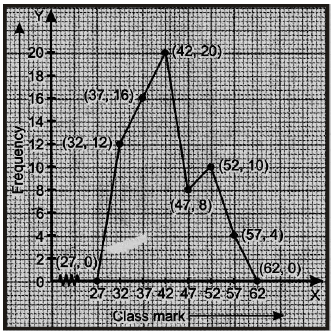
Ex. Draw the frequency polygon representing the following frequency distribution.

Sol. Though the given frequency table is in inclusive form, yet we find that class marks in case of inclusive and exclusive forms are the same. We take the imagined classes 25 – 29 at the beginning and 60 – 64 at the end, each with frequency zero. Thus, we have :

Now plot the points (27, 0), (32, 12), (37, 16), (42, 20), (47, 8), (52, 10), (57, 4) and (62, 0) and join them successively to obtain the required frequency polygon, as shown below :
HISTOGRAM AND FREQUENCY POLYGON ON THE SAME GRAPH
When a histogram and a frequency polygon are to be drawn on the same graph, we first draw the histogram with the given data. We then join the mid-points of the tops of adjacent rectangles by line segments to obtain the frequency polygon.
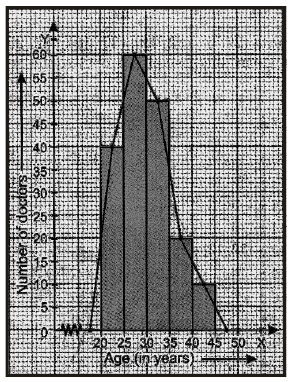
Ex.13 The following table gives the number of doctors working in government hospitals in a city in various age groups. Draw a histogram and frequency polygon for the given data.

Sol. Step-1 : Draw rectangles with bases 20–25, 25–30, 30–35, 35–40 and 40–45 and heights 40, 60, 50, 20 and 10 respectively. Since the scale on x-axis starts at 20, we make a kink in the beginning. Thus, we obtain the required histogram.
Step-2 : Mark the mid-point of the top of each rectangle of the histogram.
Step 3 : Mark the mid-points of class-intervals 15 - 20 and 45 - 50 on x-axis.
Step-4 : Join the consecutive mid-points by line segments to obtain the required frequency polygon.
ARTHMETIC MEAN
The average of numbers in arithmetic is known as the Arithmetic Mean or simply the mean of these numbers in statistics.
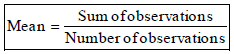
MEAN OF UNGROUPED DATA
The mean of n observations x1, x2, ...., xn is given by
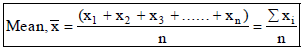
where the symbol 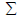 , called sigma stands for the summation of the terms.
, called sigma stands for the summation of the terms.
Ex.14 The heights of 6 boys in a group are 142 cm, 154 cm, 146 cm, 145 cm, 151 cm and 150 cm. Find the mean height per boy.
Sol.
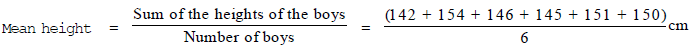
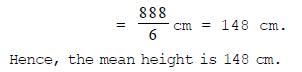
Ex.15 Find the mean of the first five multiples of 7.
Sol. The first five multiples of 7 are 7, 14, 21, 28 and 35.
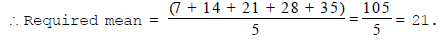
MEAN FOR AN UNGROUPED FREQUENCY DISTRIBUTION
I. Direct Method
Let n observations consist of values x1, x2, ...., xn of a variable x, occurring with frequencies f1, f2, .... , fn respectively.
Then, the mean of these observations is given by :
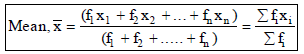
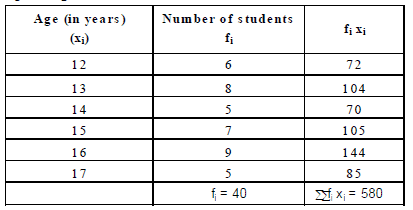
Ex.18 The ages of 40 students in a class are given below :

Find the mean age of the class.
Sol. We prepare the table as given below :
Age (in years) Number of students 1;, xi
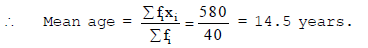
MEDIAN OF UNGROUPED DATA
Median : After arranging the given data in an ascending or a descending order of magnitude, the value of the middle-most observation is called the median of the data.
Method for Finding the Median of An Ungrouped Data
Arrange the given data in an increasing or decreasing order of magnitude. Let the total number of observations be n.
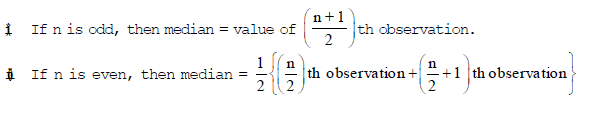
Ex.21 The marks of 13 students (out of 50) in an examination are:
39, 21, 23, 17, 32, 41, 18, 26, 30, 24, 27, 36, 9.
Find the median marks.
Sol. Arranging the marks in an ascending order, we have :
9, 17, 18, 21, 23, 24, 26, 27, 30, 32, 36, 39, 41
Here, n = 13, which is odd .

= Value of 7th term = 26.
Hence, the median marks are 26.
FAQs on Statistics Class 9 Notes - Mathematics, Class 9
| 1. What is statistics? |  |
| 2. What are the different types of statistics? | |
| 3. What are the different measures of central tendency? | |
| 4. How is standard deviation calculated? | |
| 5. What is a normal distribution? | |

|
10.2K Views |

|
4.62/5 Rating |

|
Dec 27, 2024 Last updated |

|
Explore Courses for Class 9 exam
|
|
Viva Questions
,shortcuts and tricks
,Sample Paper
,Class 9
,mock tests for examination
,study material
,Summary
,MCQs
,Objective type Questions
,Important questions
,Statistics Class 9 Notes - Mathematics
,practice quizzes
,Class 9
,Class 9
,Exam
,Statistics Class 9 Notes - Mathematics
,Semester Notes
,past year papers
,video lectures
,ppt
,Extra Questions
,Statistics Class 9 Notes - Mathematics
,Free
,Previous Year Questions with Solutions
;






Statistics Class 9 Notes - Mathematics, Class 9 Free PDF Download
Importance of Statistics Class 9 Notes - Mathematics, Class 9
Statistics Class 9 Notes - Mathematics, Class 9
Statistics Class 9 Notes - Mathematics, Class 9 Class 9 Questions
Study Statistics Class 9 Notes - Mathematics, Class 9 on the App
|
© EduRev
|
Education Revolution
|



|




