Pipeline Hazards

Pipeline Hazards
A pipeline hazard occurs when the pipeline, or some portion of the pipeline, must stall because conditions do not permit continued correct execution of instructions in successive pipeline stages. Such a stall is commonly called a pipeline bubble. The three broad classes of hazards are resource (structural) hazards, data hazards, and control hazards. Each class requires different detection and resolution techniques to maintain correct program behaviour while preserving high instruction throughput.
Types of Hazards
Resource (Structural) Hazards
A resource hazard (also called a structural hazard) arises when two or more instructions in the pipeline require the same hardware resource at the same time and the resource cannot be shared. Because the resource is contended, one instruction must wait and the pipeline must execute those instructions in serial for the conflicted stages, producing bubbles and reducing performance.
Example: consider a simplified five-stage pipeline with stages IF (instruction fetch), ID (instruction decode/register read), EX (execute), MEM (memory access) and WB (write back), where each stage takes one clock cycle. If the processor uses a single-ported main memory for both instruction fetch and data read/write, an operand read or write to memory cannot be performed in parallel with an instruction fetch. In such a case the pipeline must stall the instruction fetch stage for the duration of the memory access for the other instruction. This behaviour is illustrated in the referenced figures (Figure 3.6a and Figure 3.6b).
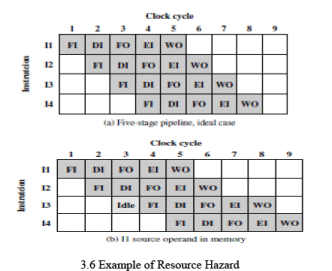
Common hardware solutions:
- Duplicate resources where possible (for example, separate instruction and data memories - a Harvard architecture - or separate instruction and data caches).
- Use multi-ported memories or caches to allow simultaneous accesses.
- Pipeline the contested resources themselves so that multiple accesses are overlapped safely.
- Use scheduling techniques in hardware to avoid conflicts when duplication is impractical.
Data Hazards
A data hazard arises when two instructions that execute close together in time access the same register or memory location and at least one of the accesses is a write. If the pipeline allows overlapping execution of those instructions, the later instruction may read a value before the earlier instruction has written the correct one, producing an incorrect result compared with strict sequential execution.
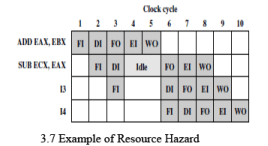
Consider the x86 instruction sequence:
ADD EAX, EBX /* EAX = EAX + EBX */
SUB ECX, EAX /* ECX = ECX - EAX */
In a five-stage pipeline, the result of the ADD is not written to EAX until the end of the WB stage, which completes in a later clock cycle than when the SUB instruction needs the updated value. If the SUB reads EAX before the ADD has written it, the SUB will use the old value and produce an incorrect result. Without special hardware or compiler arrangements, the pipeline must insert stalls so that the SUB sees the correct value.
The three canonical types of data hazards are:
- Read After Write (RAW) - true dependency: an instruction needs to read a location that a prior instruction will write. A hazard occurs if the read happens before the write completes.
- Write After Read (WAR) - anti-dependency: an instruction writes to a location that an earlier instruction needs to read. A hazard occurs if the write completes before the earlier read has taken its value.
- Write After Write (WAW) - output dependency: two instructions write to the same location. A hazard occurs if the writes complete in the reverse order to the program order.
Hardware and compiler techniques to handle data hazards:
- Forwarding (bypassing): route a result directly from a producing stage (for example EX/MEM) to a consuming stage (for example EX) without waiting for the write-back stage. Forwarding eliminates many RAW hazards.
- Pipeline interlocks (automatic stalls): hardware detects hazards that cannot be resolved by forwarding and inserts bubbles until the data is ready.
- Scoreboarding and Tomasulo's algorithm: dynamic scheduling techniques that track dependencies and resource usage to allow out-of-order execution while preserving data dependences.
- Compiler scheduling: the compiler reorders independent instructions or inserts small delays (NOPs or useful independent instructions) to avoid hazards.
Illustrative timing note (five-stage pipeline): when an instruction produces a register value in its WB stage and a dependent instruction requires that value in its ID or EX stage earlier, there will be a window of cycles in which the consumer must wait unless forwarding provides the value sooner.
Control Hazards
A control hazard (branch hazard) occurs when the pipeline cannot determine which instruction to fetch next because of a branch, jump or other control transfer. If the processor fetches instructions along the wrong path (because the branch decision or target was not yet known), those speculatively fetched instructions must be discarded if the prediction turns out to be incorrect, costing cycles to refill the pipeline.
Consequences and a simple model: the number of cycles lost (the branch penalty) is approximately the number of pipeline stages between the point of the branch instruction and the stage that resolves the branch outcome. Deeper pipelines and longer branch-resolution latencies increase branch penalty and reduce effective instruction throughput.
Techniques to reduce control hazards:
- Static branch prediction: use simple rules (for example, predict backward branches as taken for loops) decided at compile time or by fixed hardware heuristics.
- Dynamic branch prediction: use history-based predictors such as two-bit predictors, global history predictors, or hybrid predictors to predict the branch outcome at run time.
- Branch target buffer (BTB): predict both branch outcome and target early so the next instruction fetch can start on the predicted path.
- Delayed branching: the compiler schedules useful instructions in the delay slots immediately after a branch so that a misprediction wastes fewer cycles.
- Speculative execution with rollback: execute down the predicted path and commit results only when the prediction is confirmed; if mispredicted, flush the speculative results and restore state.
- Predication: convert small conditional branches into predicated (conditional) instructions to avoid branching altogether.
Mitigation Summary and Best Practices
Effective pipeline design uses a mix of hardware and compiler strategies to reduce hazard penalties while maintaining correctness:
- Design resources to minimise structural hazards (separate caches, multi-ported memories, or duplicated functional units where cost permits).
- Implement forwarding and pipeline interlocks to handle most data hazards automatically; use dynamic scheduling or Tomasulo for more aggressive out-of-order designs.
- Reduce control hazard costs via accurate dynamic branch prediction, BTBs and speculative execution; use compiler techniques like static prediction, instruction scheduling and predication where appropriate.
- When designing or analysing pipelined systems, quantify hazards using metrics such as cycles per instruction (CPI), stall cycles per instruction, and branch penalty to identify dominant bottlenecks.
Understanding pipeline hazards and their resolution is central to achieving high instruction throughput in modern processors. The correct combination of microarchitectural features and compiler optimisations depends on the target performance, power, area and complexity trade-offs.
FAQs on Pipeline Hazards
| 1. What are pipeline hazards in computer architecture? |  |
| 2. What is a data hazard in pipeline processing? | |
| 3. How can data hazards be resolved in pipeline processing? | |
| 4. What is a control hazard in pipeline processing? | |
| 5. How can control hazards be mitigated in pipeline processing? | |



 | Explore Courses for Computer Science Engineering (CSE) exam |
 | Get EduRev Notes directly in your Google search |