Pipeline Hazards | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE) PDF Download
Pipeline Hazards
A pipeline hazard occurs when the pipeline, or some portion of the pipeline, must stall because conditions do not permit continued execution. Such a pipeline stall is also referred to as a pipeline bubble. There are three types of hazards: resource, data, and control.
Resources Hazards
A resource hazard occurs when two (or more) instructions that are already in the pipeline need the same resource. The result is that the instructions must be executed in serial rather than parallel for a portion of the pipeline. A resource hazard is sometime referred to as a structural hazard.
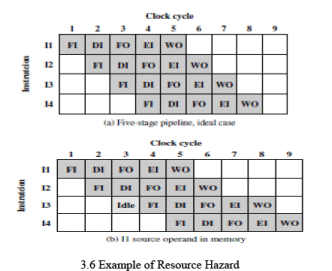
Let us consider a simple example of a resource hazard.Assume a simplified five-stage pipeline, in which each stage takes one clock cycle. In Figure 3.6a which a new instruction enters the pipeline each clock cycle. Now assume that main memory has a single port and that all instruction fetches and data reads and writes must be performed one at a time. In this case, an operand read to or write from memory cannot be performed in parallel with an instruction fetch. This is illustrated in Figure 3.6b, which assumes that the source operand for instruction I1 is in memory, rather than a register. Therefore, the fetch instruction stage of the pipeline must idle for one cycle before beginning the instruction fetch for instruction I3. The figure assumes that all other operands are in registers
Data Hazards
A data hazard occurs when two instructions in a program are to be executed in sequence and both access a particular memory or register operand. If the two instructions are executed in strict sequence, no problem occurs but if the instructions are executed in a pipeline, then the operand value is to be updated in such a way as to produce a different result than would occur only with strict sequential execution of instructions. The program produces an incorrect result because of the use of pipelining.
As an example, consider the following x86 machine instruction sequence:
ADD EAX, EBX /* EAX = EAX + EBX
SUB ECX, EAX /* ECX = ECX - EAX
The first instruction adds the contents of the 32-bit registers EAX and EBX and stores the result in EAX. The second instruction subtracts the contents of EAX from ECX and stores the result in ECX.
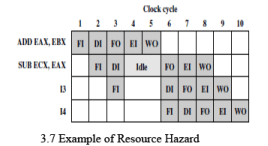
Figure 3.7 shows the pipeline behaviour. The ADD instruction does not update register EAX until the end of stage 5, which occurs at clock cycle 5. But the SUB instruction needs that value at the beginning of its stage 2, which occurs at clock cycle 4. To maintain correct operation, the pipeline must stall for two clocks cycles. Thus, in the absence of special hardware and specific avoidance algorithms, such a data hazard results in inefficient pipeline usage. There are three types of data hazards;
• Read after write (RAW), or true dependency:.A hazard occurs if the read takes place before the write operation is complete.
• Write after read (RAW), or antidependency: A hazard occurs if the write operation completes before the read operation takes place.
• Write after write (RAW), or output dependency: Two instructions both write to the same location. A hazard occurs if the write operations take place in the reverse order of the intended sequence. The example of Figure 3.7 is a RAW hazard.
Control Hazards
A control hazard, also known as a branch hazard, occurs when the pipeline makes the wrong decision on a branch prediction and therefore brings instructions into the pipeline that must subsequently be discarded.
|
20 videos|86 docs|48 tests
|
FAQs on Pipeline Hazards - Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
| 1. What are pipeline hazards in computer architecture? |  |
| 2. What is a data hazard in pipeline processing? | |
| 3. How can data hazards be resolved in pipeline processing? | |
| 4. What is a control hazard in pipeline processing? | |
| 5. How can control hazards be mitigated in pipeline processing? | |

|
1.9K Views |

|
4.90/5 Rating |

|
Dec 26, 2024 Last updated |
|
20 videos|86 docs|48 tests
|

|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
mock tests for examination
,Summary
,Pipeline Hazards | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,ppt
,Previous Year Questions with Solutions
,practice quizzes
,MCQs
,Extra Questions
,Semester Notes
,Viva Questions
,Pipeline Hazards | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,Objective type Questions
,Exam
,Pipeline Hazards | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,past year papers
,Sample Paper
,study material
,Free
,video lectures
,shortcuts and tricks
,Important questions
;






Pipeline Hazards Free PDF Download
Importance of Pipeline Hazards
Pipeline Hazards Notes
Pipeline Hazards Computer Science Engineering (CSE) Questions
Study Pipeline Hazards on the App
|
© EduRev
|
Education Revolution
|



|




